







目录
聚类和分类的区别:
分类算法中数据带有标签,而聚类无标签。
用途:
寻找优质客户、社区发现、异常点监控(信用卡诈骗与黑客攻击)
1. KMeans模型
- 算法接受参数k:然后将事先输入的n个数据对象划分为k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。
- 算法思想∶以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果
步骤:
- 先从没有标签的元素集合A中随机取k个元素,作为k个子集各自的重心。
- 分别计算剩下的元素到k个子集重心的距离(这里的距离也可以使用欧氏距离),根据距离将这些元素分别划归到最近的子集。
- 根据聚类结果,重新计算重心(重心的计算方法是计算子集中所有元素各个维度的算数平均数)。
- 将集合A中全部元素按照新的重心然后再重新聚类。5.重复第4步,直到聚类结果不再发生变化。
eg:
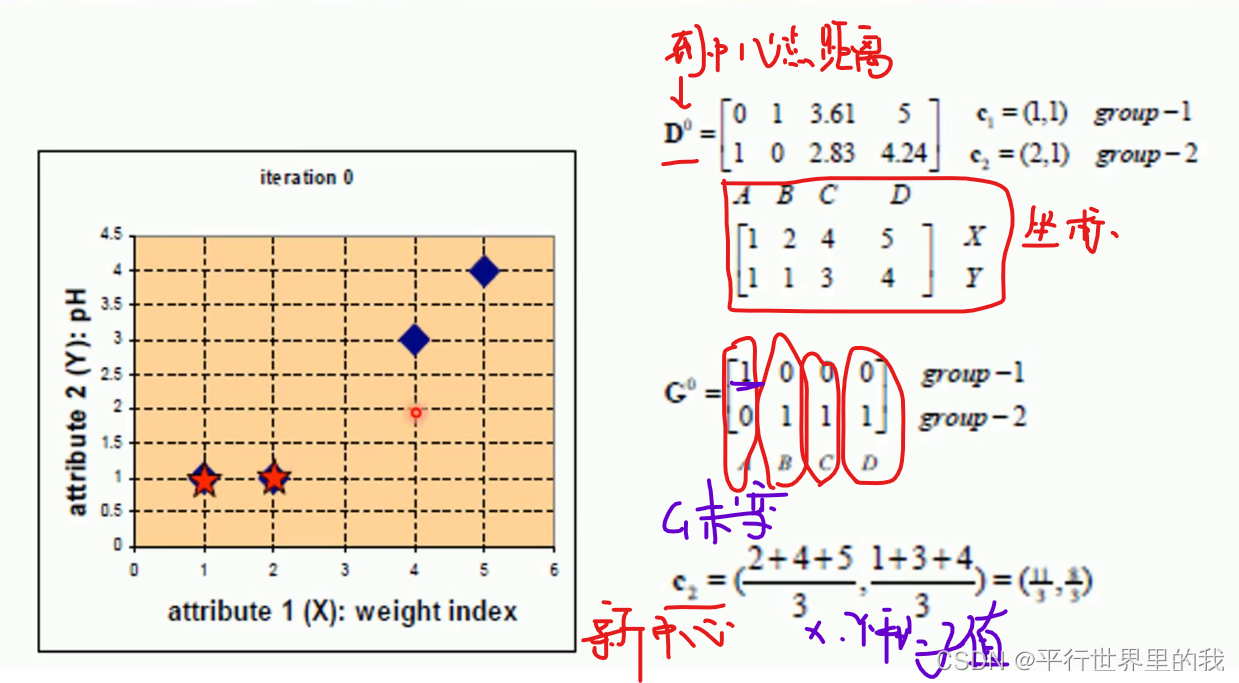
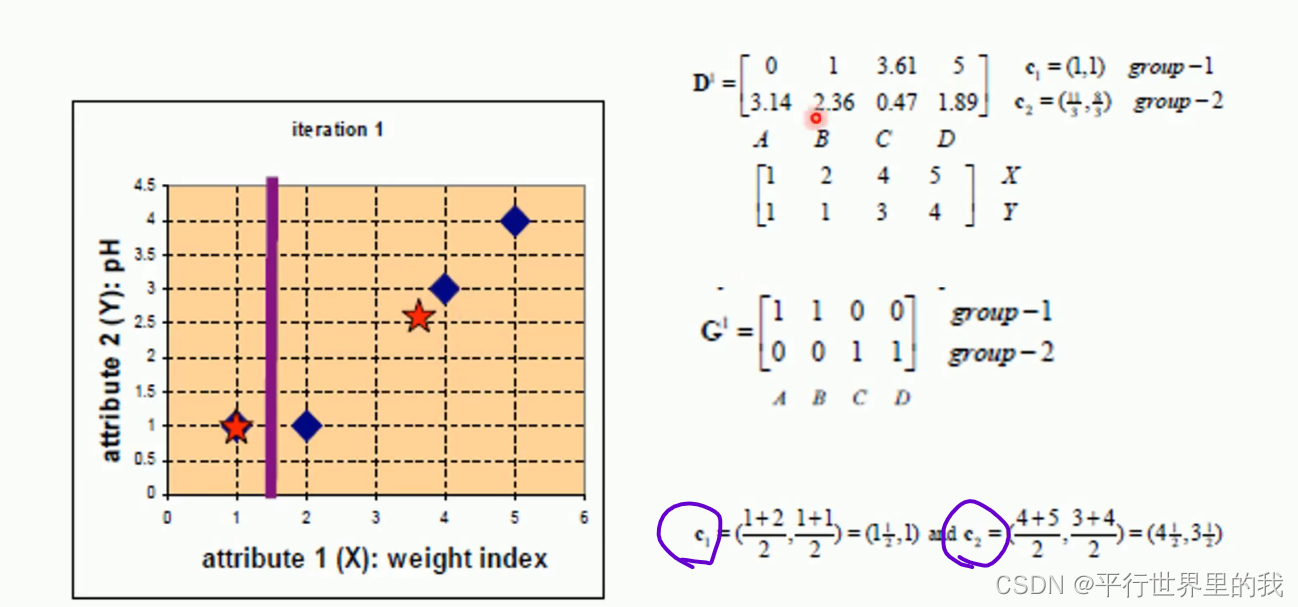
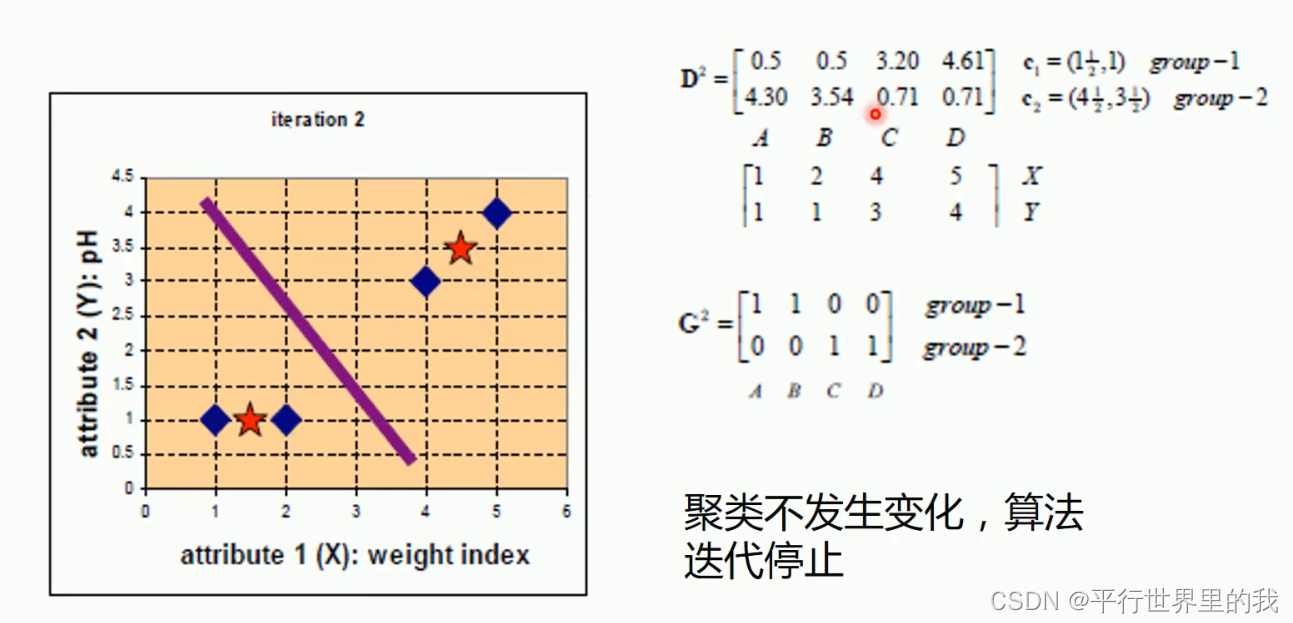
2. KMeans模型代码
2.1 python实现
画出散点图大概看可以分几类
# 载入数据
data = np.genfromtxt("kmeans.txt", delimiter=" ")
plt.scatter(data[:,0],data[:,1])
plt.show()数据一共有80个样本,每个样本有2个特征
import numpy as np
import matplotlib.pyplot as plt
# 载入数据
data = np.genfromtxt("kmeans.txt", delimiter=" ")
plt.scatter(data[:,0],data[:,1])
plt.show()
print(data.shape)
# (80, 2)
# 训练模型
# 计算距离
def euclDistance(vector1, vector2):
return np.sqrt(sum((vector2 - vector1) ** 2))
# 初始化质心
def initCentroids(data, k):
numSamples, dim = data.shape
# k个质心,列数跟样本的列数一样
centroids = np.zeros((k, dim))
# 随机选出k个质心
for i in range(k):
# 随机选取一个样本的索引
index = int(np.random.uniform(0, numSamples))
# 作为初始化的质心
centroids[i, :] = data[index, :]
return centroids
# 传入数据集和k的值
def kmeans(data, k):
# 计算样本个数
numSamples = data.shape[0]
# 样本的属性,第一列保存该样本属于哪个簇,第二列保存该样本跟它所属簇的误差
clusterData = np.array(np.zeros((numSamples, 2)))
# 决定质心是否要改变的变量
clusterChanged = True
# 初始化质心
centroids = initCentroids(data, k)
while clusterChanged:
clusterChanged = False
# 循环每一个样本
for i in range(numSamples):
# 最小距离
minDist = 100000.0
# 定义样本所属的簇
minIndex = 0
# 循环计算每一个质心与该样本的距离
for j in range(k):
# 循环每一个质心和样本,计算距离
distance = euclDistance(centroids[j, :], data[i, :])
# 如果计算的距离小于最小距离,则更新最小距离
if distance < minDist:
minDist = distance
# 更新最小距离
clusterData[i, 1] = minDist
# 更新样本所属的簇
minIndex = j
# 如果样本的所属的簇发生了变化
if clusterData[i, 0] != minIndex:
# 质心要重新计算
clusterChanged = True
# 更新样本的簇
clusterData[i, 0] = minIndex
# 更新质心
for j in range(k):
# 获取第j个簇所有的样本所在的索引
cluster_index = np.nonzero(clusterData[:, 0] == j)
# 第j个簇所有的样本点
pointsInCluster = data[cluster_index]
# 计算质心
centroids[j, :] = np.mean(pointsInCluster, axis=0)
# showCluster(data, k, centroids, clusterData)
return centroids, clusterData
# 显示结果
def showCluster(data, k, centroids, clusterData):
numSamples, dim = data.shape
if dim != 2:
print("dimension of your data is not 2!")
return 1
# 用不同颜色形状来表示各个类别
mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']
if k > len(mark):
print("Your k is too large!")
return 1
# 画样本点
for i in range(numSamples):
markIndex = int(clusterData[i, 0])
plt.plot(data[i, 0], data[i, 1], mark[markIndex])
# 用不同颜色形状来表示各个类别
mark = ['*r', '*b', '*g', '*k', '^b', '+b', 'sb', 'db', '<b', 'pb']
# 画质心点
for i in range(k):
plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize=20)
plt.show()
# 设置k值
k = 4
# centroids 簇的中心点
# cluster Data样本的属性,第一列保存该样本属于哪个簇,第二列保存该样本跟它所属簇的误差
centroids, clusterData = kmeans(data, k)
if np.isnan(centroids).any():
print('Error')
else:
print('cluster complete!')
# 显示结果
showCluster(data, k, centroids, clusterData)
print(centroids)
# 做预测
x_test = [0,1]
print(np.tile(x_test,(k,1)))
# 误差平方
print((np.tile(x_test,(k,1))-centroids)**2)
# 误差平方和
print(((np.tile(x_test,(k,1))-centroids)**2).sum(axis=1))
# 最小值所在的索引号
print(np.argmin(((np.tile(x_test,(k,1))-centroids)**2).sum(axis=1)))
def predict(datas):
return np.array([np.argmin(((np.tile(data,(k,1))-centroids)**2).sum(axis=1)) for data in datas])
# 画出簇的作用区域
# 获取数据值所在的范围
x_min, x_max = data[:, 0].min() - 1, data[:, 0].max() + 1
y_min, y_max = data[:, 1].min() - 1, data[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
z = predict(np.c_[xx.ravel(), yy.ravel()])# ravel与flatten类似,多维数据转一维。flatten不会改变原始数据,ravel会改变原始数据
z = z.reshape(xx.shape)
# 等高线图
cs = plt.contourf(xx, yy, z)
# 显示结果
showCluster(data, k, centroids, clusterData)2.2 Sklearn实现
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
# 载入数据
data = np.genfromtxt("kmeans.txt", delimiter=" ")
# 设置k值
k = 4
# 训练模型
model = KMeans(n_clusters=k)
model.fit(data)
# 分类中心点坐标
centers = model.cluster_centers_
print(centers)
# 预测结果
result = model.predict(data)
print(result)
print(model.labels_)
# 画出各个数据点,用不同颜色表示分类
mark = ['or', 'ob', 'og', 'oy']
for i, d in enumerate(data):
plt.plot(d[0], d[1], mark[result[i]])
# 画出各个分类的中心点
mark = ['*r', '*b', '*g', '*y']
for i, center in enumerate(centers):
plt.plot(center[0], center[1], mark[i], markersize=20)
plt.show()
# 获取数据值所在的范围
x_min, x_max = data[:, 0].min() - 1, data[:, 0].max() + 1
y_min, y_max = data[:, 1].min() - 1, data[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
z = model.predict(np.c_[xx.ravel(), yy.ravel()]) # ravel与flatten类似,多维数据转一维。flatten不会改变原始数据,ravel会改变原始数据
z = z.reshape(xx.shape)
# 等高线图
cs = plt.contourf(xx, yy, z)
# 显示结果
# 画出各个数据点,用不同颜色表示分类
mark = ['or', 'ob', 'og', 'oy']
for i, d in enumerate(data):
plt.plot(d[0], d[1], mark[result[i]])
# 画出各个分类的中心点
mark = ['*r', '*b', '*g', '*y']
for i, center in enumerate(centers):
plt.plot(center[0], center[1], mark[i], markersize=20)
plt.show()3. Kmeans算法存在的四个问题
3.1 初始质心的选取
对k个初始质心的选择比较敏感,容易陷入局部最小值。
例如,我们上面的算法运行的时候,有可能会得到不同的结果,如下面这两种情况。K-means也是收敛了,只是收敛到了局部最小值。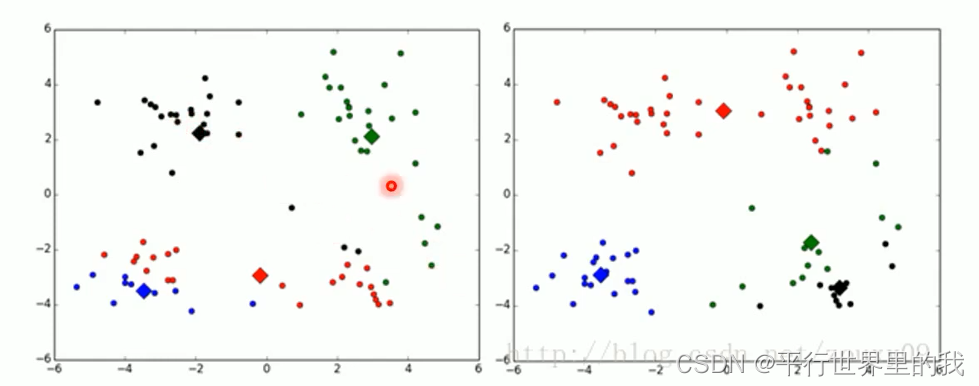
3.1.1 解决方法:
使用多次的随机初始化,计算每一次建模得到的代价函数的值,选取代价函数最小结果作为聚类结果。

3.1.2 优化代码实现:
import numpy as np
import matplotlib.pyplot as plt
# 载入数据
data = np.genfromtxt("kmeans.txt", delimiter=" ")
plt.scatter(data[:,0],data[:,1])
plt.show()
print(data.shape)
# (80, 2)
# 训练模型
# 计算距离
def euclDistance(vector1, vector2):
return np.sqrt(sum((vector2 - vector1) ** 2))
# 初始化质心
def initCentroids(data, k):
numSamples, dim = data.shape
# k个质心,列数跟样本的列数一样
centroids = np.zeros((k, dim))
# 随机选出k个质心
for i in range(k):
# 随机选取一个样本的索引
index = int(np.random.uniform(0, numSamples))
# 作为初始化的质心
centroids[i, :] = data[index, :]
return centroids
# 传入数据集和k的值
def kmeans(data, k):
# 计算样本个数
numSamples = data.shape[0]
# 样本的属性,第一列保存该样本属于哪个簇,第二列保存该样本跟它所属簇的误差
clusterData = np.array(np.zeros((numSamples, 2)))
# 决定质心是否要改变的变量
clusterChanged = True
# 初始化质心
centroids = initCentroids(data, k)
while clusterChanged:
clusterChanged = False
# 循环每一个样本
for i in range(numSamples):
# 最小距离
minDist = 100000.0
# 定义样本所属的簇
minIndex = 0
# 循环计算每一个质心与该样本的距离
for j in range(k):
# 循环每一个质心和样本,计算距离
distance = euclDistance(centroids[j, :], data[i, :])
# 如果计算的距离小于最小距离,则更新最小距离
if distance < minDist:
minDist = distance
# 更新最小距离
clusterData[i, 1] = minDist
# 更新样本所属的簇
minIndex = j
# 如果样本的所属的簇发生了变化
if clusterData[i, 0] != minIndex:
# 质心要重新计算
clusterChanged = True
# 更新样本的簇
clusterData[i, 0] = minIndex
# 更新质心
for j in range(k):
# 获取第j个簇所有的样本所在的索引
cluster_index = np.nonzero(clusterData[:, 0] == j)
# 第j个簇所有的样本点
pointsInCluster = data[cluster_index]
# 计算质心
centroids[j, :] = np.mean(pointsInCluster, axis=0)
# showCluster(data, k, centroids, clusterData)
return centroids, clusterData
# 显示结果
def showCluster(data, k, centroids, clusterData):
numSamples, dim = data.shape
if dim != 2:
print("dimension of your data is not 2!")
return 1
# 用不同颜色形状来表示各个类别
mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']
if k > len(mark):
print("Your k is too large!")
return 1
# 画样本点
for i in range(numSamples):
markIndex = int(clusterData[i, 0])
plt.plot(data[i, 0], data[i, 1], mark[markIndex])
# 用不同颜色形状来表示各个类别
mark = ['*r', '*b', '*g', '*k', '^b', '+b', 'sb', 'db', '<b', 'pb']
# 画质心点
for i in range(k):
plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize=20)
plt.show()
# 设置k值
k = 4
min_loss = 10000
min_loss_centroids = np.array([])
min_loss_clusterData = np.array([])
for i in range(50):
# centroids 簇的中心点
# cluster Data样本的属性,第一列保存该样本属于哪个簇,第二列保存该样本跟它所属簇的误差
centroids, clusterData = kmeans(data, k)
loss = sum(clusterData[:, 1]) / data.shape[0]
if loss < min_loss:
min_loss = loss
min_loss_centroids = centroids
min_loss_clusterData = clusterData
# print('loss',min_loss)
print('cluster complete!')
centroids = min_loss_centroids
clusterData = min_loss_clusterData
# 显示结果
showCluster(data, k, centroids, clusterData)
print(centroids)
# 做预测
x_test = [0,1]
print(np.tile(x_test,(k,1)))
# 误差平方
print((np.tile(x_test,(k,1))-centroids)**2)
# 误差平方和
print(((np.tile(x_test,(k,1))-centroids)**2).sum(axis=1))
# 最小值所在的索引号
print(np.argmin(((np.tile(x_test,(k,1))-centroids)**2).sum(axis=1)))
def predict(datas):
return np.array([np.argmin(((np.tile(data,(k,1))-centroids)**2).sum(axis=1)) for data in datas])
# 画出簇的作用区域
# 获取数据值所在的范围
x_min, x_max = data[:, 0].min() - 1, data[:, 0].max() + 1
y_min, y_max = data[:, 1].min() - 1, data[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
z = predict(np.c_[xx.ravel(), yy.ravel()])# ravel与flatten类似,多维数据转一维。flatten不会改变原始数据,ravel会改变原始数据
z = z.reshape(xx.shape)
# 等高线图
cs = plt.contourf(xx, yy, z)
# 显示结果
showCluster(data, k, centroids, clusterData)3.2 K值的选取
k值的选择是用户指定的,不同的k得到的结果会有挺大的不同,如下图所示,左边是k=3的结果,蓝色的簇太稀疏了,蓝色的簇应该可以再划分成两个簇。右边是k=5的结果,红色和蓝色的簇应该合并为一个簇。
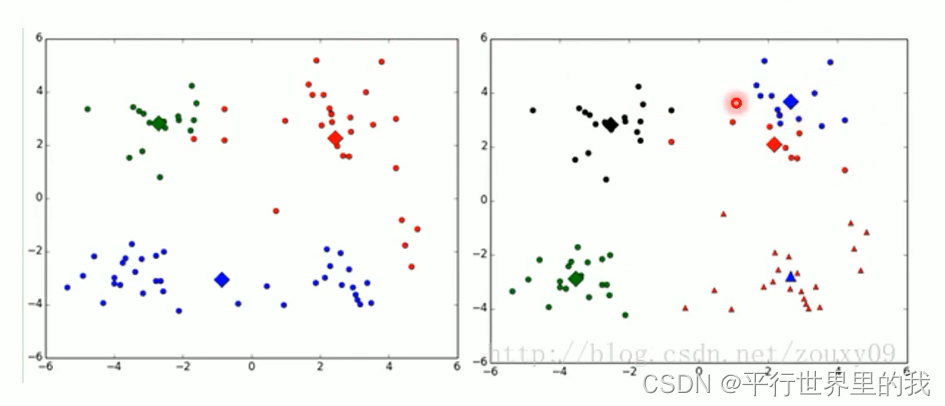
3.2.1 解决方法:
有两种——①肘部法则
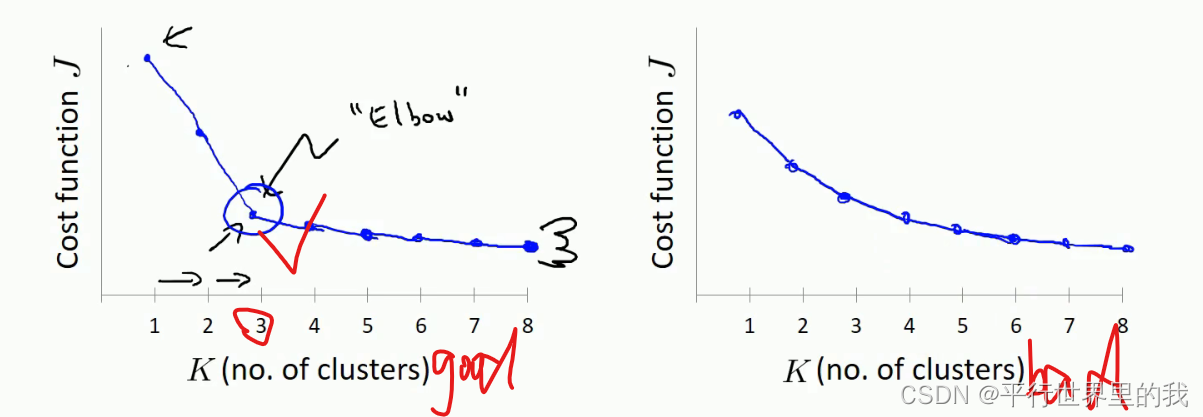
3.2.2 肘部法则代码:
在前面代价函数基础上改进:
list_lost = []
for k in range(2,10):
min_loss = 10000
min_loss_centroids = np.array([])
min_loss_clusterData = np.array([])
for i in range(50):
# centroids 簇的中心点
# cluster Data样本的属性,第一列保存该样本属于哪个簇,第二列保存该样本跟它所属簇的误差
centroids, clusterData = kmeans(data, k)
loss = sum(clusterData[:,1])/data.shape[0]
if loss < min_loss:
min_loss = loss
min_loss_centroids = centroids
min_loss_clusterData = clusterData
list_lost.append(min_loss)
print(list_lost)
plt.plot(range(2,10),list_lost)
plt.xlabel('k')
plt.ylabel('loss')
plt.show()3.3 存在局限性
对于非球状的数据分布无法分类
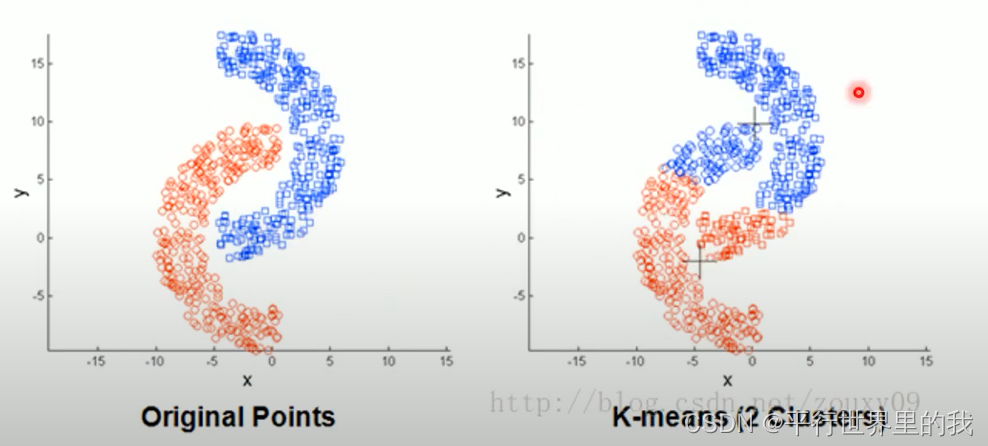
3.3.1 解决方法:
密度聚类算法
DBSCAN:Density Based Spatial Clustering of Applications with Noise
特点:将具有足够高密度的区域划分为簇,并可以发现任何形状的聚类。
特有定义:
①邻域:给定对象半径
内的区域称为该对象的
邻域。
②核心对象: 如果给定邻域内的样本点数大于等于Minpoints,则该对象为核心对象。
③直接密度可达:给定一个对象集合D,如果p在q的邻域内,且q是一个核心对象,则我们说对象p从q出发是直接密度可达的(directly density reachable)
④密度可达:集合D,存在一个对象链p1,p2,……pn,p1=q,pn=p,pi+1是从pi关于和Minpoints直接密度可达,则称点p是从q关于
和Minpoints密度可达的。
⑤密度相连: 集合D存在点o,使得点p、q是从o关于和 Minpoints密度可达,那么点p、q是关于
和Minpoints密度相连的。
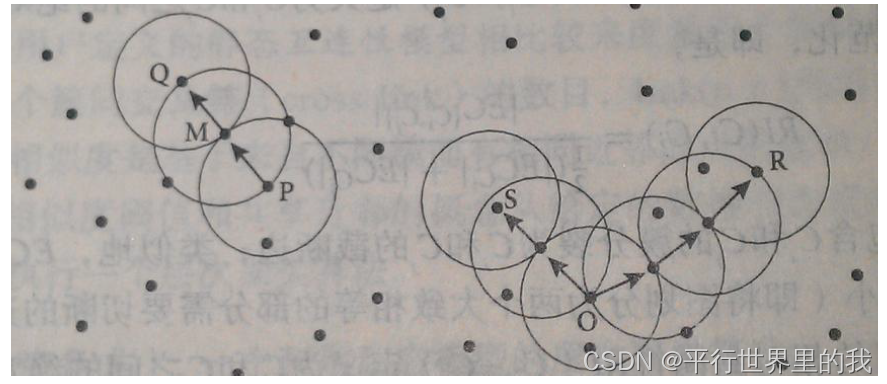
算法思想:
- 指定合适的
和Minpoints。
- 计算所有的样本点,如果点p的
- 反复寻找这些核心点直接密度可达(之后可能是密度可达)的点,将其加入到相应的簇,对于核心点发生“密度相连”状况的簇,给予合并。
- 当没有新的点可以被添加到任何簇时,算法结束。
缺点:
- 当数据量增大时,要求较大的内存支持与I/O消耗也很大。
- 当空间聚类的密度不均匀、聚类间距相差很大时,聚类质量较差。
DBSCAN和Kmeans比较:
- DBSCAN不需要输入聚类个数;
- 聚类簇的形状没有要求;
- 可以在需要时输入过滤噪声的参数——即
3.3.2 sklearn_DBSCAN代码
from sklearn.cluster import DBSCAN
import numpy as np
import matplotlib.pyplot as plt
# 载入数据
data = np.genfromtxt("kmeans.txt", delimiter=" ")
# 训练模型
# eps距离阈值,min_samples核心对象在eps领域的样本数阈值
model = DBSCAN(eps=1.5, min_samples=4)
model.fit(data)
result = model.fit_predict(data)
print(result)
# 画出各个数据点,用不同颜色表示分类
mark = ['or', 'ob', 'og', 'oy', 'ok', 'om']
for i, d in enumerate(data):
plt.plot(d[0], d[1], mark[result[i]])
plt.show()
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
x1, y1 = datasets.make_circles(n_samples=2000, factor=0.5, noise=0.05)
x2, y2 = datasets.make_blobs(n_samples=1000, centers=[[1.2,1.2]], cluster_std=[[.1]])
x = np.concatenate((x1, x2))
plt.scatter(x[:, 0], x[:, 1], marker='o')
plt.show()
from sklearn.cluster import DBSCAN
y_pred = DBSCAN().fit_predict(x)
plt.scatter(x[:, 0], x[:, 1], c=y_pred)
plt.show()
y_pred = DBSCAN(eps = 0.2, min_samples=50).fit_predict(x)
plt.scatter(x[:, 0], x[:, 1], c=y_pred)
plt.show()
3.4 数据较大,收敛较慢
3.4.1 解决方法:
Mini Banch Kmeans
Mini Batch K-Means算法是Kmeans算法的变种,采用小批量的数据子集减少计算时间。这里所谓的小批量是指每次训练算法时随机抽取的数据子集,采用这些随机产生的子集进行训练算法,大大减小了计算时间,结果一般只略差于标准算法。
该算法的迭代步骤有两步:
- 从数据集中随机抽取一些数据形成小批量,把他们分配给最近的质心
- 更新质心:与K均值算法相比,数据的更新是在每一个小的样本集上。Mini Batch K-Means比K-Means有更快的收敛速度,但同时也降低了聚类的效果,但是在实际项目中却表现得不明显。
3.4.2 Mini Batch KMeans代码
和Kmeans几乎一样
from sklearn.cluster import MiniBatchKMeans
import numpy as np
import matplotlib.pyplot as plt
# 载入数据
data = np.genfromtxt("kmeans.txt", delimiter=" ")
# 设置k值
k = 4
# 训练模型
model = MiniBatchKMeans(n_clusters=k)
model.fit(data)
# 分类中心点坐标
centers = model.cluster_centers_
print(centers)
# 预测结果
result = model.predict(data)
print(result)
print(model.labels_)
# 画出各个数据点,用不同颜色表示分类
mark = ['or', 'ob', 'og', 'oy']
for i, d in enumerate(data):
plt.plot(d[0], d[1], mark[result[i]])
# 画出各个分类的中心点
mark = ['*r', '*b', '*g', '*y']
for i, center in enumerate(centers):
plt.plot(center[0], center[1], mark[i], markersize=20)
plt.show()
# 获取数据值所在的范围
x_min, x_max = data[:, 0].min() - 1, data[:, 0].max() + 1
y_min, y_max = data[:, 1].min() - 1, data[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
z = model.predict(np.c_[xx.ravel(), yy.ravel()]) # ravel与flatten类似,多维数据转一维。flatten不会改变原始数据,ravel会改变原始数据
z = z.reshape(xx.shape)
# 等高线图
cs = plt.contourf(xx, yy, z)
# 显示结果
# 画出各个数据点,用不同颜色表示分类
mark = ['or', 'ob', 'og', 'oy']
for i, d in enumerate(data):
plt.plot(d[0], d[1], mark[result[i]])
# 画出各个分类的中心点
mark = ['*r', '*b', '*g', '*y']
for i, center in enumerate(centers):
plt.plot(center[0], center[1], mark[i], markersize=20)
plt.show()















 9860
9860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









