







目录
1.1 搜索引擎怎么工作
google baidu ……
索引存在库中
蜘蛛爬取
对视频图像等——将图片变成数字,在对比。
多模态搜索
数据量大:批量召回(先构建索引)、粗排(TF-IDF、相似度筛选)、精排
TF:词频 (文章信息的局部信息)
IDF:逆文本频率指数 (系统的全局信息)
1.2 统计学让搜索速度起飞
把语言向量化
TF-IDF(它使用词语的重要程度与独特性来代表每篇文章,然后通过对比搜索词与代表的相似性,给你提供最相似的文章列表)
TF-IDF:不是神经网络或者深度学习,是基于统计学的方法,这种方法在文档量巨大时,搜索速度很快。
TF-IDF数学表达形式:向量
cos距离计算两个文章的夹角
1.2.1 TF-IDF的计算代码:
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
tf_idf = vectorizer.fit_transform(docs)
print("idf: ", [(n, idf) for idf, n in zip(vectorizer.idf_, vectorizer.get_feature_names())])
print("v2i: ", vectorizer.vocabulary_)
计算夹角代码
q = "I get a coffee cup"
qtf_idf = vectorizer.transform([q])
res = cosine_similarity(tf_idf, qtf_idf)
res = res.ravel().argsort()[-3:]
print("\ntop 3 docs for '{}':\n{}".format(q, [docs[i] for i in res[::-1]]))1.3 搜索的扩展
IDF带有某个领域的全局信息。如果恰好要做一个领域的搜索,又恰好有这个领域的IDF分布,就省去了很多数据收集的烦恼。
在机器学习中神经网络模型方面,迁移学习正好就是这个道理。
集群版搜索——ElasticSearch(BM25)
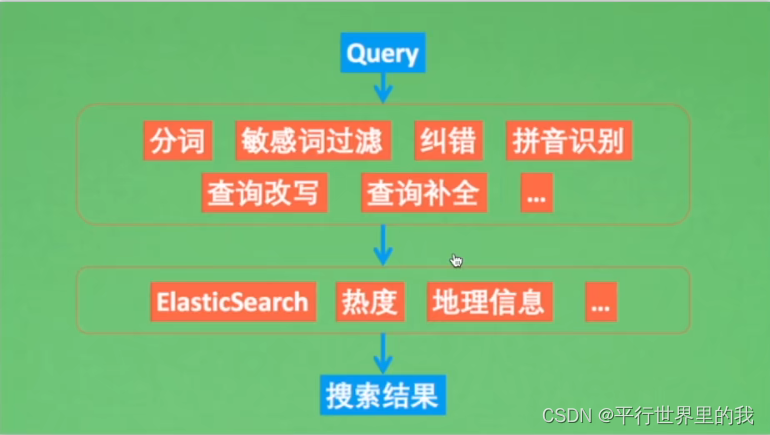
一个完整的搜索流程:
首先输入搜索问句,然后对其进行预处理,包括分词、敏感词过滤、纠错等等;再通过各种召回策略,比如TF-IDF、ElasticSearch召回等,得到候选答案;最后再做一些业务层面的过滤处理,才能得到你的搜索展示框的内容。















 869
869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









