







小目标检测 FPN(一)
小目标的介绍:有两种定义方式,一种是相对尺寸大小,如目标尺寸的长宽是原图像尺寸的0.1,即可认为是小目标,另外一种是绝对尺寸的定义,即尺寸小于32*32像素的目标即可认为是小目标。
方法一:FPN
论文:feature pyramid networks for object detection
主要思想:
在FPN之前,大多数目标检测的方法和分类网络一样,用特征提取网络的最后一层来进行回归和预测。
缺点:这种方法只用到高层的语义信息,对于前面特征提取的信息,利用率非常低。在目标检测中位置幸喜尤为重要。位置信息主要在网络的底层,语义信息主要存在于高层。该文章采用不同特征层多尺度融合的方法(特征融合)来进行预测。
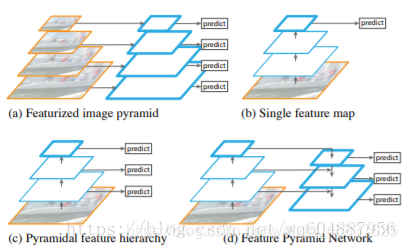
a. 第一幅图是典型的图像金字塔形象,该方法主要是将图像生成不同的尺寸,在每一个尺寸上生成相应的特征图,在每一个特征层上面都要进行预测。
缺点:占用的内存和时间都是比较大的,比较浅的特征层没有必要这样做。
b. 这个和yolov1,比较相似,faster rcnn 一样,在最后一层进行预测,和常见的分类网络也一样。
缺点:对于前面的特征层信息丢失严重。
c. 这个就是单阶段SSD网络了,利用了多层特征层来进行预测,与a比较,不是利用全部特征层来进行预测,与b比较利用多层来进行预测。
缺点:在预测的过程中,每一个尺度都相对独立,没有配合使用。
d. 这个就是FPN层,将小的特征层经过上采样之后与大的特征层进行尺度融合之后再做预测。这样就既可以利用到高层的语义信息,又可以利用到底层的位置信息。
Ps:这个方法在yolov3上面完美体现。
def DarknetConv2D(*args, **kwargs):
darknet_conv_kwargs = {'kernel_regularizer': l2(5e-4)}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2,2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
#---------------------------------------------------#
# 卷积块
# DarknetConv2D + BatchNormalization + LeakyReLU
#---------------------------------------------------#
def DarknetConv2D_BN_Leaky(*args, **kwargs):
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
LeakyReLU(alpha=0.1))
#---------------------------------------------------#
# 卷积块
# DarknetConv2D + BatchNormalization + LeakyReLU
#---------------------------------------------------#
def resblock_body(x, num_filters, num_blocks):
x = ZeroPadding2D(((1,0),(1,0)))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (3,3), strides=(2,2))(x)
for i in range(num_blocks):
y = DarknetConv2D_BN_Leaky(num_filters//2, (1,1))(x)
y = DarknetConv2D_BN_Leaky(num_filters, (3,3))(y)
x = Add()([x,y])
return x
#---------------------------------------------------#
# darknet53 的主体部分
#---------------------------------------------------#
def darknet_body(x):
x = DarknetConv2D_BN_Leaky(32, (3,3))(x)
x = resblock_body(x, 64, 1)
x = resblock_body(x, 128, 2)
x = resblock_body(x, 256, 8)
feat1 = x
x = resblock_body(x, 512, 8)
feat2 = x
x = resblock_body(x, 1024, 4)
feat3 = x
return feat1,feat2,feat3`














 1186
1186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









