






一、卷积神经网络的应用
基本应用:分类、检索、检测、分割
人脸识别
人脸表情识别
图像生成
自动驾驶
二、传统神经网络vs卷积神经网络
1.深度学习的三部曲
- 搭建神经网络结构
- 找到一个合适的损失函数(cross entropy loss,MSE,...)
- 找到一个合适的优化函数,更新参数 (BP,SGD,...)
2.损失函数

3.卷积神经网络的优势
传统的神经网络采用全连接网络,全连接网络处理图像带来的问题是参数太多,权重矩阵的参数太多容易导致过拟合。
而卷积神经网络使得局部关联,参数共享,大大减少了参数的数量。
4.卷积神经网络的结构

CONV layer:卷积层
RELU layer:RELU激活层
POOL layer:池化层
FC layer:全连接层
三、卷积神经网络的基本组成结构
1.卷积

卷积是对两个实变函数的一种数学操作。
在图像处理中,图像是以二维矩阵的形式输入到神经网络的,因此需要二维卷积。
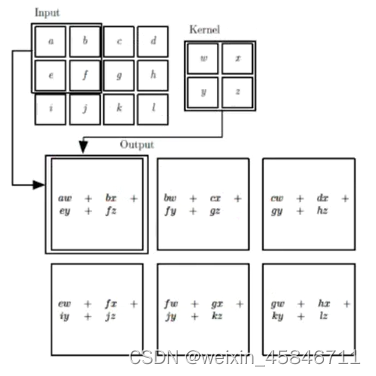
涉及到的基本概念:
input:输入
kernel/filter:卷积核/滤波器
weights:权重(就是kernel/filter中的每个参数,如图中的w,x,y,z)
receptive field:感受野(每一步kernel所对应的input里的矩阵)
activation map或feature map:特征图(经过一次卷积之后输出的矩阵)
padding 填充
depth/channel:深度
output:输出
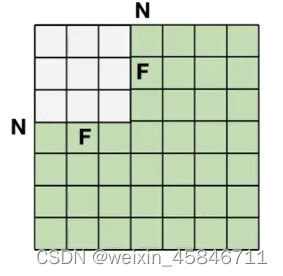
(未加padding)输出的特征图大小:(N-F)/stride+1
有padding时输出的特征图大小:(N+padding*2-F)/stride+1
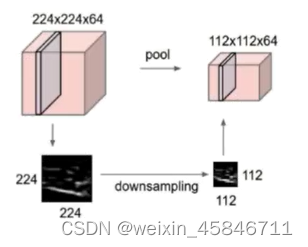
2.池化
Pooling:
保留了主要特征的同时减少参数和计算量,防止过拟合,提高模型泛化能力。
它一般处于卷积层与卷积层之间,全连接层与全连接层之间。
Pooling的类型:
Max pooling:最大值池化
Average pooling:平均池化
3.全连接
- 两层之间所有神经元都有权重连接
- 通常全连接层在卷积神经网络尾部
- 全连接层参数量通常最大
四、卷积神经网络的典型结构
1.AlexNet
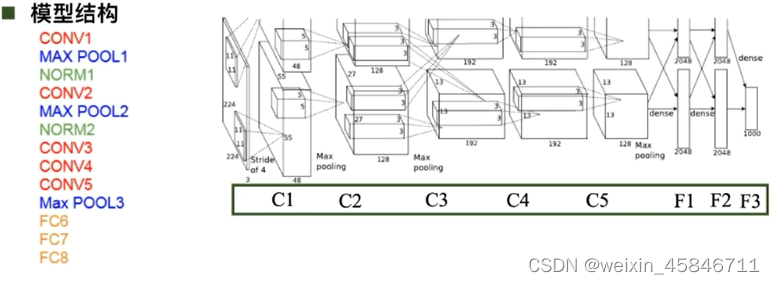
AlexNet之所以能够成功,深度学习之所以能重回历史舞台,原因在于:
- 大数据训练:百万级的ImageNet图像数据
- 非线性激活函数:ReLU(解决了梯度消失的问题,计算速度快,收敛速度远快于sigmoid)
- 防止过拟合:Dropout(训练时随机关闭部分神经元测试时整合所有神经元),Data augmentation
- 其他:双GPU实现

2.ZFNet

3.VGG
VGG是一个更深的网络
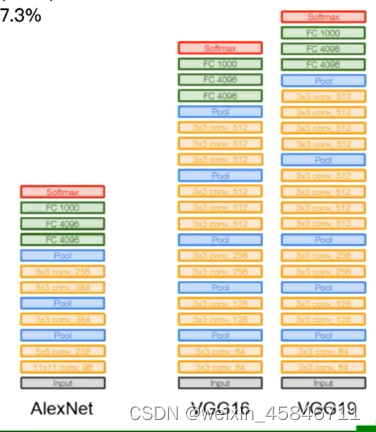
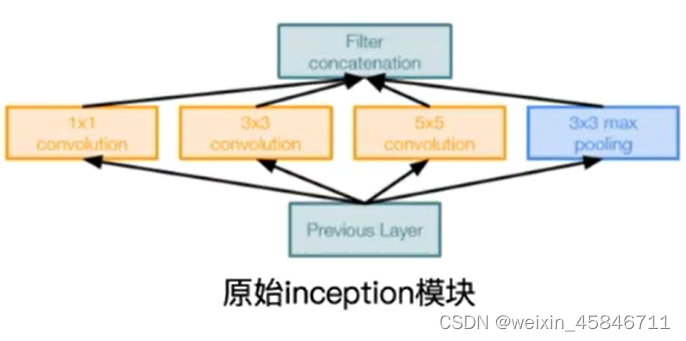
4.GoogleNet

Naive Inception:多卷积核增加特征多样性,但最终的输出量会比较大。
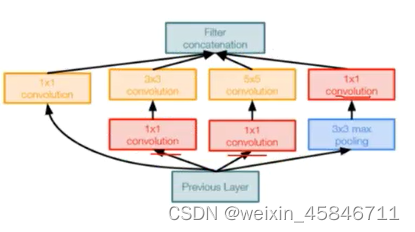
Inception V2:插入1*1卷积核进行降维
Inception V3:进一步对V2的参数数量进行降低
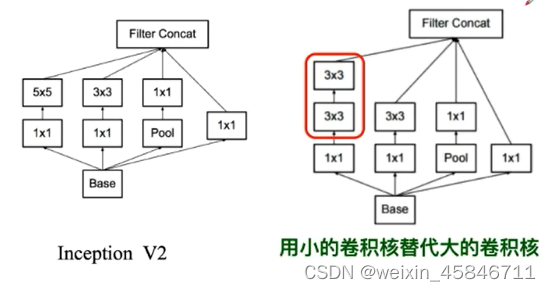
- 降低参数量
- 增加非线性激活函数:使网络产生更多独立特征,表征能力更强,训练更快。
5.ResNet(残差学习网络,deep residual learning network)
深度有152层。

残差的思想:去掉相同的主体部分,从而突出微小的变化。
可以被用来训练非常深的网络。
除了输出层之外,没有其他的全连接层。
五、代码练习
1.MNIST数据集分类
首先加载数据,加载结果为:
读取部分数据集中的图像显示:
接着创建网络结构,定义训练和测试函数;
在小型全连接网络上进行训练,训练结果为:
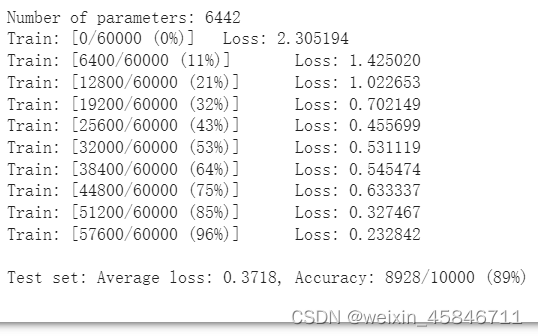
在卷积神经网络上进行训练,CNN与全连接网络拥有相同数量的模型参数,训练结果为:

通过上面两种结果对比,相同参数的CNN训练效果要明显优于全连接网络,是因为CNN能够更好地挖掘图像中的信息,主要通过两个手段:卷积与池化。
考虑到CNN在卷积与池化上的优良特性,如果我们把图像中的像素打乱顺序,这样卷积和池化就难以发挥作用了,为了验证这个想法,打乱像素顺序再次在两个网络上进行训练与测试。
首先打乱图像中的像素顺序:

重新定义训练与测试函数,首先在全连接网络上进行训练与测试:

在卷积神经网络上进行训练与测试:

很明显,打乱像素顺序后,全连接网络的性能基本没有变化,但是卷积神经网络的性能明显下降,因为卷积神经网络利用的是像素的局部关系,打乱顺序以后,像素间的关系无法在卷积神经网络上使用。
2.CIFAR10数据集分类
首先加载数据集,展示数据集中的部分图片:

定义网络,损失函数和优化器,训练网络,从测试集中取出8张图片:
把图片输入模型,

可以看到,还是会有一些识别错误的,网络在整个数据集上的表现:

3.使用VGG16对CIFAR10分类
下载数据集:

创建网络结构:
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.cfg = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M']
self.features = self._make_layers(self.cfg)
self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)验证测试准确率:

问题:
1.dataloader 里面 shuffle 取不同值有什么区别?
shuffle取True时,代表要将数据集中的数据打乱顺序,增加多样性,取False则没有这种效果。
2.transform 里,取了不同值,这个有什么区别?
transform, 一种函数或变换,输入PIL图片,返回变换之后的数据。
transforms.RandomCrop():采用随机图像差值方式,对图像进行裁剪、缩放;包括Scale Jittering方法(VGG及ResNet模型使用)或者尺度和长宽比增强变换。
transforms.RandomHorizontalFlip()是做水平翻转。
pytorch的图像处理库 torchvision 的 transforms 集成了随机翻转、旋转、增强对比度、转化为tensor、转化为图像等功能,用于数据增强。
3.epoch 和 batch 的区别?
epoch指训练次数;
batch指每次训练用到的数据数量大小。
4.1x1的卷积和 FC 有什么区别?主要起什么作用?
FC要求的input是一个向量,因此要将输入的矩阵拉直为一维向量,而1X1的卷积直接进行维度的变换,1X1的卷积主要是起到升维或者降维的作用。
5.residual leanring 为什么能够提升准确率?
残差学习网络中,不但有效解决了梯度消失的问题,还增加了网络的深度。
6.代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
LeNet采用均值池化,代码二的网络采用最大值池化;LeNet 采用的激活函数是 tanh,代码二网络使用 ReLU激活函数。
7.代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
使用一个1X1的卷积核将输入缩小到相同的尺寸。
8.有什么方法可以进一步提升准确率?
增加epoch的次数, 优化网络的结构。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









