







目录
复习优化器
SGD(随机梯度下降)
SGD是最基本的一种方法,先初始化参数,计算梯度,往梯度的反方向走一步到达
,因为拐点的方向L是增加的,所以要往它的反方向走一步,继续计算
处的梯度,再往其反方向走,每一个time_step都是计算梯度之后往其反方向走一步。

SGD with momentum
和SGD一样,一开始都要初始化参数,不同的是设置一个movement即
=0,计算
处的梯度,取其反方向作为需要更新的方向,movement计算更新的步长更新
▽L(
),同时
=
+
。

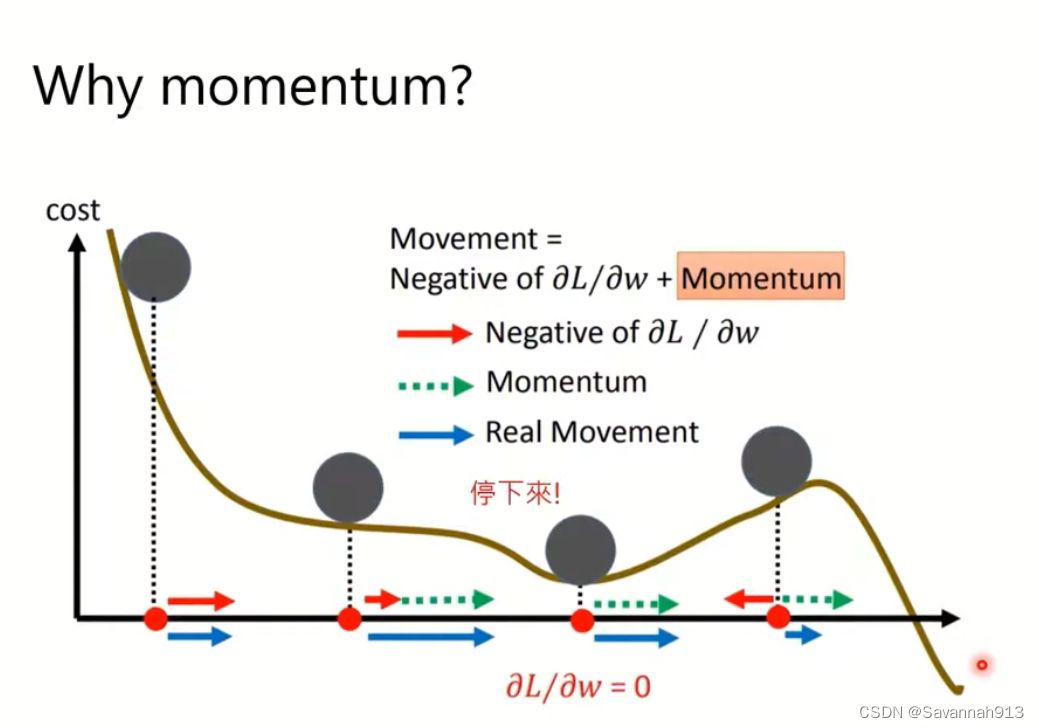
加入moment的好处就在于,即使当前步骤的梯度为0,由于前一项的移动会累加到下一步,所以movement的步长还会有一定的大小,下图中,最后一个点的移动,由于计算出来梯度的方向是如绿色箭头所示,理论上会选择红色箭头(绿色箭头的反方向),但是由于之前的计算有一个movement的累加,那么就会选择更有可能存在最小值的右侧,而不是像之前的SGD一样趋近左侧梯度为0的值。
Adagard
如果一开始的梯度很大,那么开始就会暴走,很有可能走到更差的位置,加上分母,即除以过去所有拐点的和,即如果前几步走很大步,那么作为分母之后,下一步就会变小步。

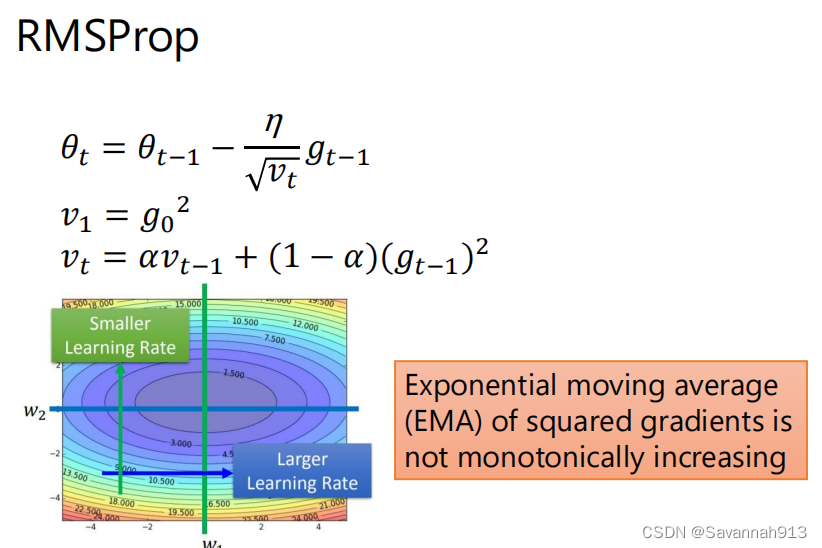
RMSProp
与SGD with movement差不多,都采用了作为步长,但是RMSprop采用的是加权平均的方式。但是并没有改变SGD中卡在一个梯度为0的位置的问题。
Adam
Adam = SGDM+RMSprop(具体见笔记)另外还多了偏差修正,
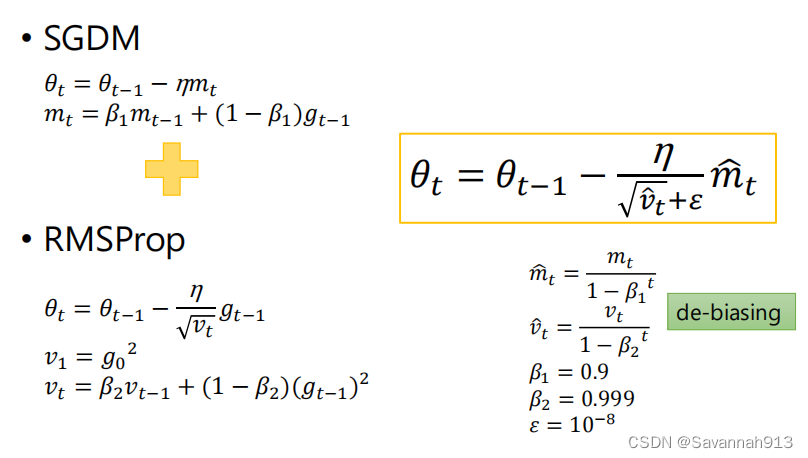

Adam与SGDM
Adam:训练速度快,落差较大,比较不稳定。
SGDM:比较稳定,落差比较小,相对较稳定,最后的时候能够收敛到较小的值。
![]()
神经网络的表示方法

最后这个图就是一个神经网络架构,input是,通过计算得到
,这个
会被拿去和
计算损失函数L(
,
)。
优化器的作用就是找到一组参数θ,使得所有损失函数的和最小。















 1369
1369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









