






问题
当集群分片数达到140K以上时,ES的_cat/nodes被调用后协调节点出现写入性能下降的问题
原因分析
- 根据硬件资源分析
FGC time有突增,CPU、IO指标没有变化,进一步查看细粒度的GC指标(jstat -gcutil)。可以看出在调用_cat/nodes后内存逐步上升,发生了一次长达7秒的FGC
怀疑点: - _cat/nodes返回的结果过大占用的很多内存
- _cat/nodes执行过程创建了大量对象
- 对象分配分析
方法:通过使用async-profiler生成_cat/nodes执行过程中协调节点上的对象分配火焰图,查看_cat/nodes执行过程中对象分配情况,确定上述的怀疑点是否成立
结果:cat/nodes执行过程中创建对象的大小仅占总大小的3.77%,上述怀疑点不成立
方法(交叉验证):使用MAT分析接口调用时的堆内存,查看是否有_cat/nodes执行过程创建的大对象
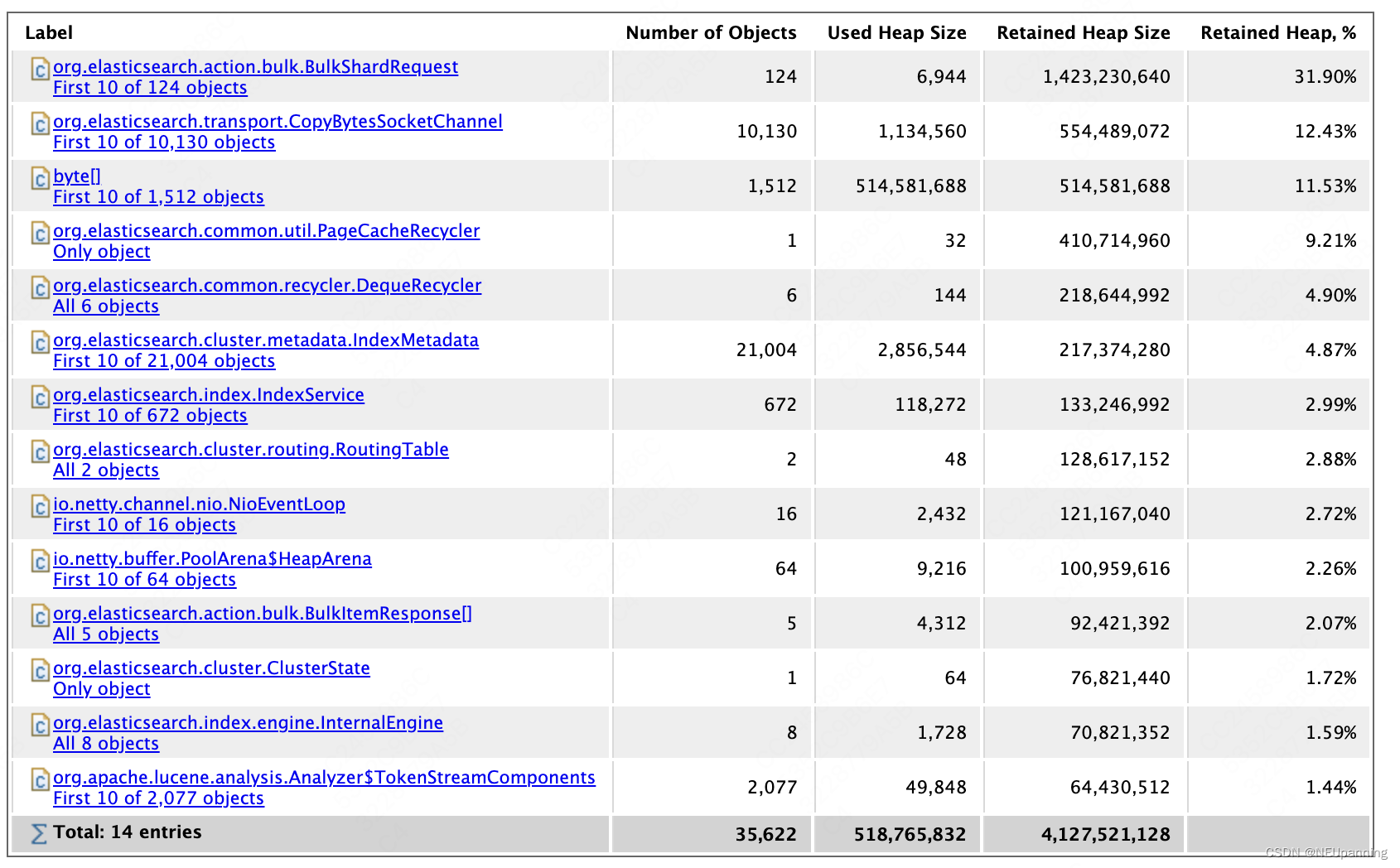
结果:没有找到_cat/nodes创建的任何大对象
代码路径分析
_cat/nodes接口执行流程如下:
- 协调节点向Master发起请求获取集群元数据
- Master节点从内存获取元数据返回给协调节点
- 协调节点向所有节点发起请求获取nodes/info(包含indices,jvm,os,http,process等初始信息,无论请求是否标识了获取该信息)
- 所有节点从内存中直接获取nodes/info并返回给协调节点,nodes/info在节点启动时已初始化,无需计算
- 协调节点收到其他节点的响应后将返回值保存到内存
- 协调节点向所有节点发起请求获取nodes/states(包含indices,jvm,os,http,process等所有的运行时信息,无论请求是否标识了获取该信息)
- 所有节点检查节点的运行信息是否需要刷新(根据刷新间隔判断)。如果需要则调用API获取运行信息,否则直接返回上次获取的运行信息
- 协调节点收到其他节点的响应后将返回值保存到内存
- 将上面获得的三部分信息和请求参数(指定获取的指标)进行格式化并返回给客户端
结论:从代码流程来看,_cat/nodes过程中协调节点没有创建大量对象,但对于节点响应的处理次数和节点数量相关,所以怀疑_cat/nodes过程占用了较多的CPU
再次回到硬件指标
上文观测的CPU指标为有写入流量情况下的分钟级粒度的CPU load/CPU使用率指标,可能由于该指标存在的局限性导致结论有误,局限性如下
- _cat/nodes接口的执行时长少于1分钟,CPU使用率是瞬时值,获取CPU使用率时可能ES没有在执行_cat/nodes。顺便说一句,GC指标为当前GC总时间瞬时值减去上一分钟GC总时间瞬时值,所以不会有这个问题。
- CPU load指标的计算口径是1分钟内的平均值,_cat/nodes带来的CPU影响会被均摊或减弱。GC指标不会有这个问题
因此,我们需要观测秒级的CPU使用率指标,并且关闭写入流量来排除写入带来的影响。指标获取语句:top -b -p 437645 -n 1 | awk ‘NR>7’ >> top_output.txt
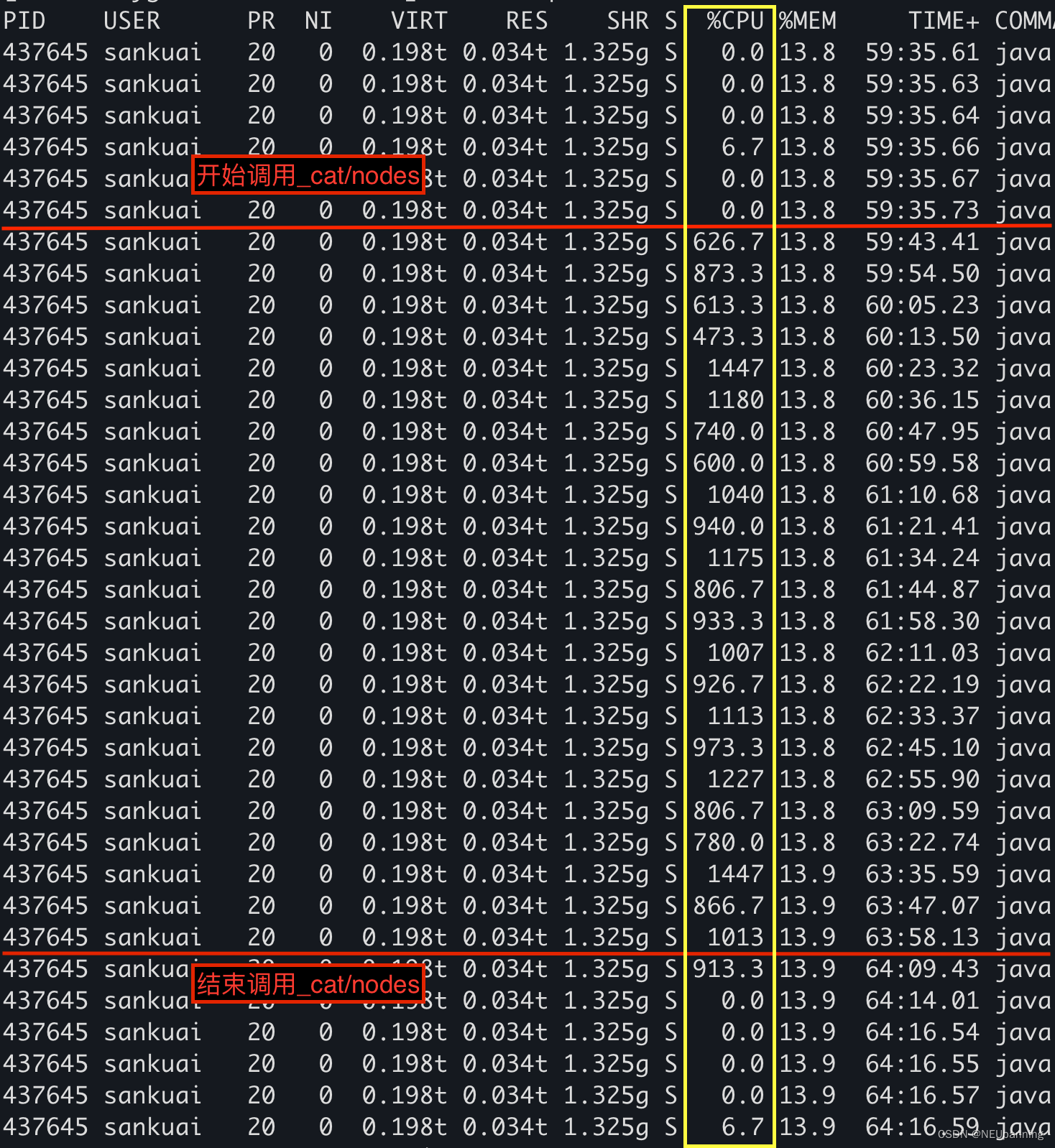
结论:_cat/nodes接口调用后,CPU使用率突增6.7% -> [600% ~ 1447%]。
CPU分析
火焰图中NioEventLoop.run栈帧及其上面栈帧为_cat/nodes执行过程中调用的,NioEventLoop.run方法调用的方法可以分为三个部分NodeStats.,NodeInfoRequest.writeTo和NodeStatsRequest.writeTo分别对应代码路径分析中的3.b,2,3部分

为什么上述方法的CPU占用和集群规模相关?
NodeStats.分析
该方法CPU占用较多且最底层的方法是ShardStats.,ShardStats.被调用的时机为根据其他节点的响应反序列化每个分片的指标,每个节点返回给协调节点它拥有的分片指标。ShardStats.方法的触发次数为集群总分片数。因此ShardStats.的时间复杂度=O(分片数)。
NodeInfoRequest.writeTo和NodeStatsRequest.writeTo分析
这两个方法很相似所以放在一起分析。方法被调用的时机是协调节点将NodeInfoRequest或NodeStatsRequest进行序列化过程中,序列化后将请求发送给集群里的其他节点。这两个方法CPU占用较多且最底层的方法是DiscoveryNode.writeTo,该方法是将请求中的DiscoveryNode对象序列化,DiscoveryNode是ES节点的抽象,一个请求中包含所有节点的DiscoveryNode对象。DiscoveryNode.writeTo方法的触发次数为节点数请求数=节点数节点数。因此NodeInfoRequest.writeTo和NodeStatsRequest.writeTo的时间复杂度=O(节点数^2)。
原因验证
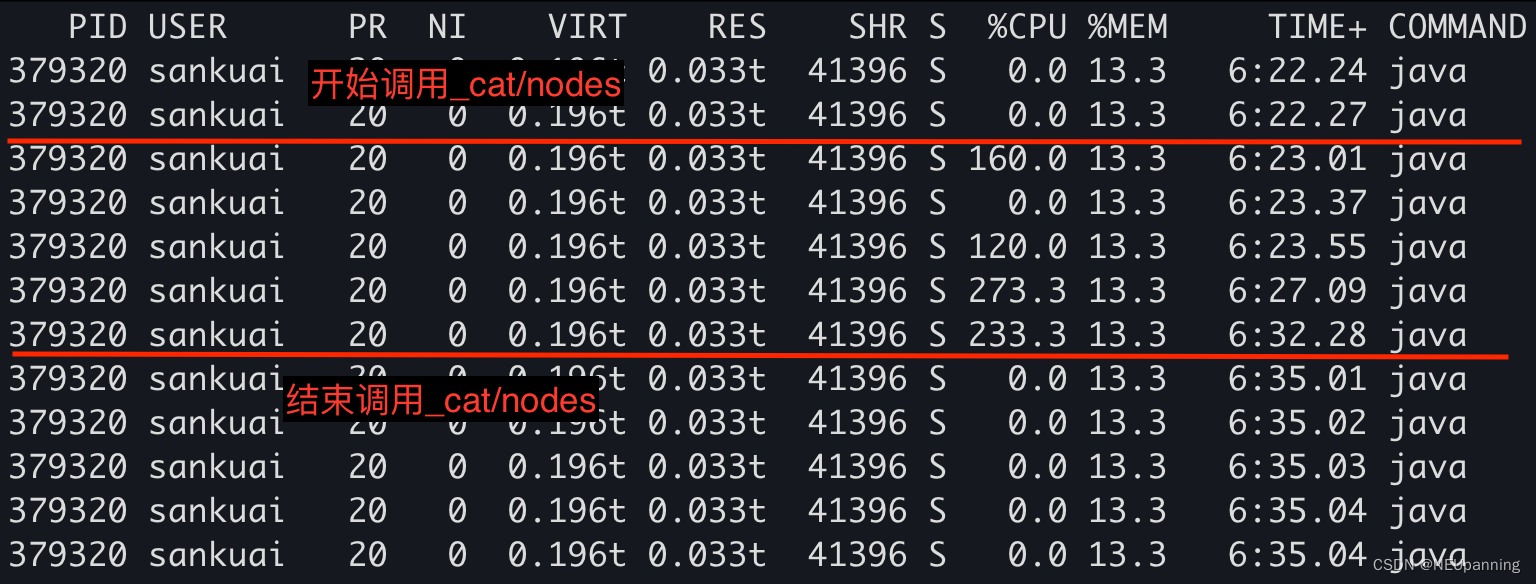
验证方法:通过侵入代码去除ShardStats.和DiscoveryNode.writeTo过程,观察协调节点执行_cat/nodes过程的CPU使用情况和Full GC情况
验证结果:
-
无写入流量时的CPU使用情况
-
有写入流量时的Full GC情况和写入延时无异常
结论:_cat/nodes接口被调用后协调节点触发的请求序列化(主要是节点列表数据结构)和分片级别指标反序列化产生了大量的CPU开销,导致写入性能受到影响
提issue给社区
#99744
问题解决
a. DiscoveryNode部分 #99990 #99938
b. Shards stats部分 #100466.















 2581
2581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









