






1. BaseInfo
| Title | CTA-Net: A CNN-Transformer Aggregation Network for Improving Multi-Scale Feature Extraction |
| Adress | https://arxiv.org/pdf/2410.11428 |
| Journal/Time | 2024.10 |
| Author | 复旦 |
| Code | 暂未开源 |
| Read | 241110 |
2. Creative Q&A
- CNN + Transformer
- 轻量级多尺度特征融合多头自注意力(LMF-MHSA)模块:Light Weight Multi-Scale Feature Fusion Multi-Head SelfAttention (LMF-MHSA) 效多尺度特征集成,同时降低了参数数量。
- 反向重构卷积-变体(RRCV)模块 Reverse Reconstruction CNN-Variants (RRCV) : 增强了在 Transformer 架构中CNN的嵌入。
在典型的聚合结构中,CNN和Transformer被组织成两个独立的分支,分别学习后进行融合。本文是在 Transformer 的架构中进行 CNN 加入。
3. Concrete
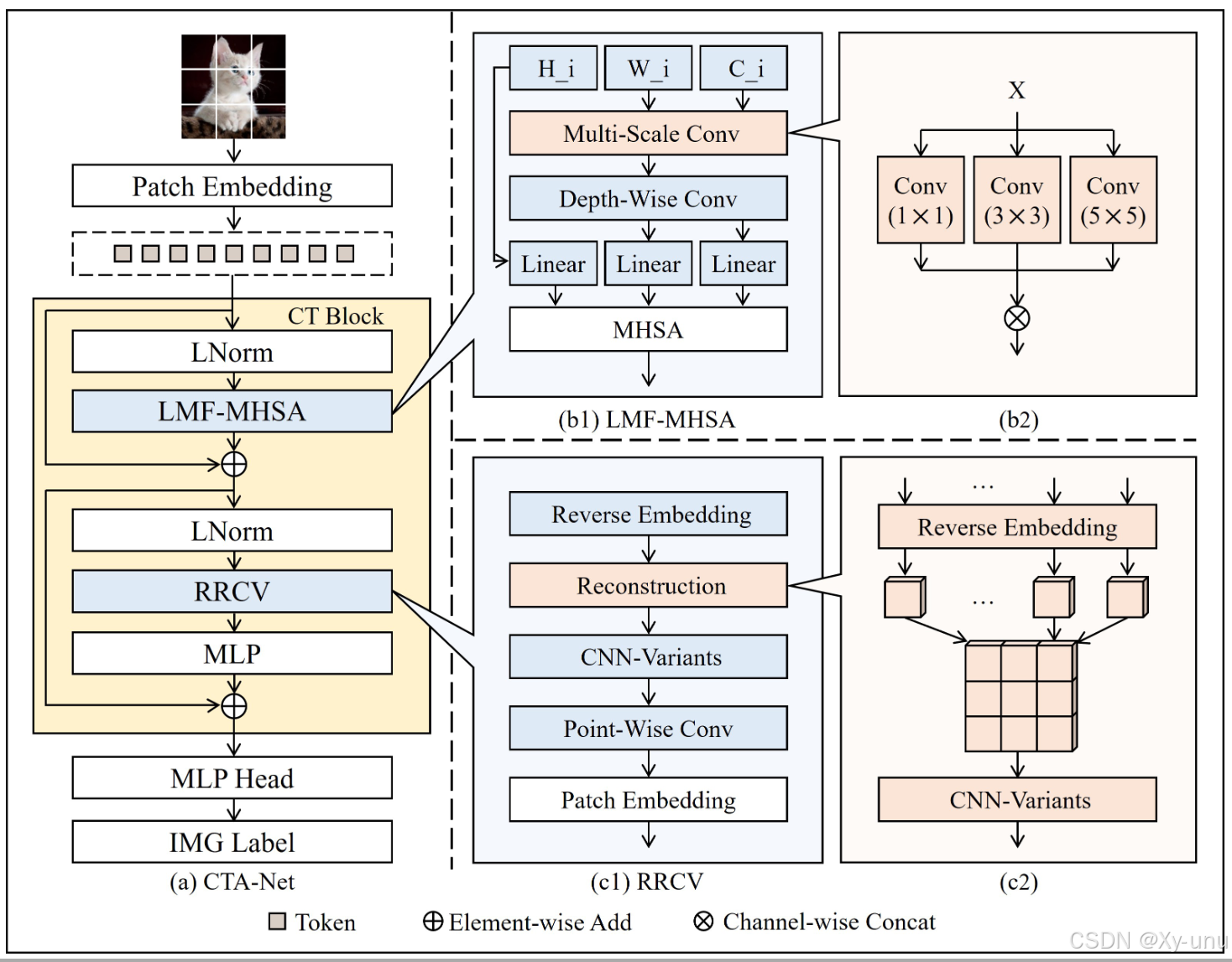
黄色部分是 CT Block 是 Transformer 的结构和结合CNN 的部分。
和 ViT 类似的结构,先分成 Patches
LMF-MHSA 是 卷积 + 多头自注意力
RRCV 反向嵌入。这个光看图有点不太懂。将 Transformer 的输出重构为 CNN 能输入的特征图形式。再进行点卷积。
CNN-Variants模块:
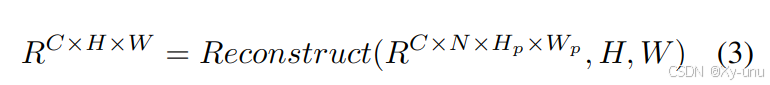
3.2. Training
3.2.1. Resource
所有实验均在配备80 GB内存的NVIDIA Tesla A100 GPU上运行。
3.2.2 Dataset
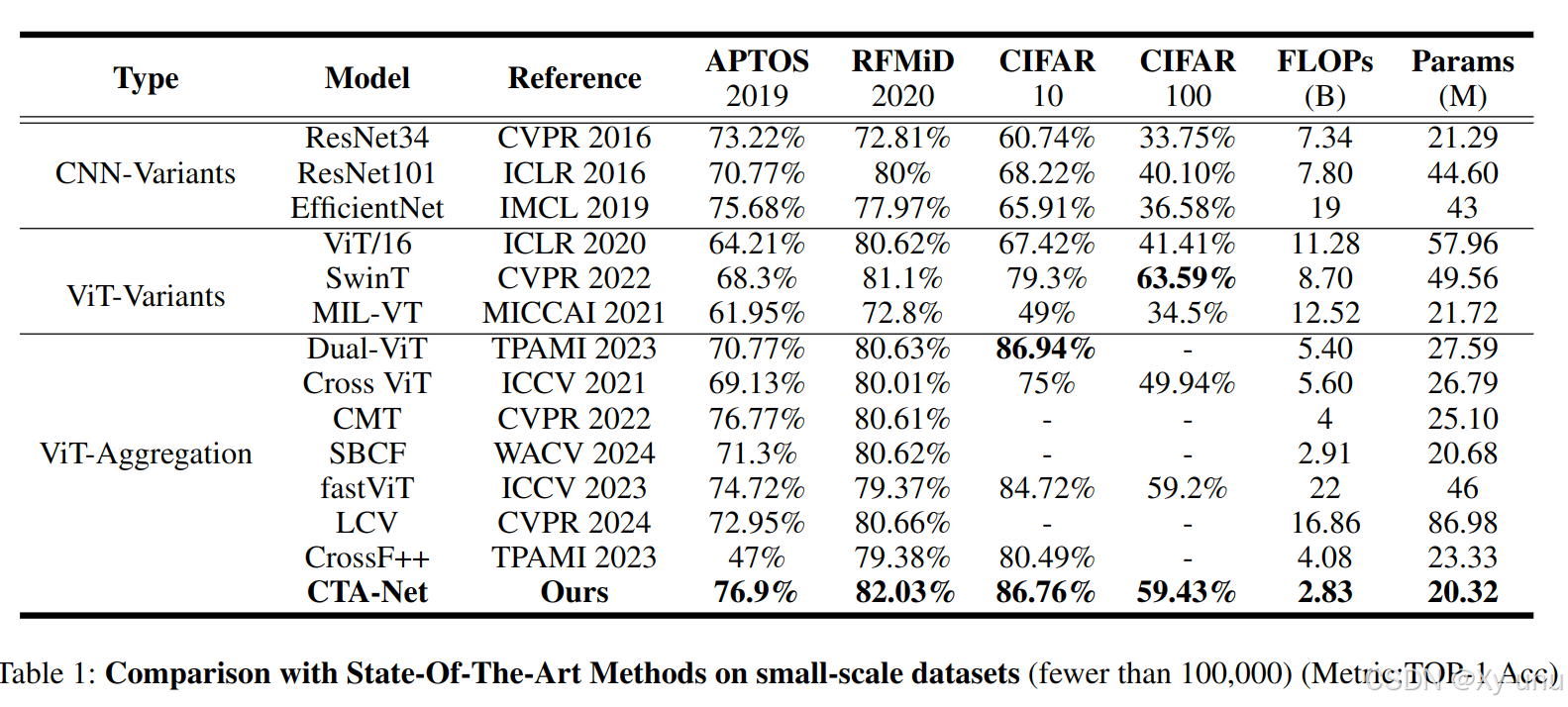
四个开源小型数据集包括CIFAR-10,CIFAR-100(Krizhevsky,Hinton等人,2009年),APTOS 2019盲视力检测(APTOS2019)(Mohanty等人,2023年),以及2020视网膜多疾病图像数据集(RFMiD2020)(Pachade等人,2021年)。
3.3. Eval
使用Top-1准确率(Top-1 Acc)作为分类准确性的衡量标准,同时测量计算效率,包括每秒浮点运算次数(FLOPs)和参数数量(Params)。
3.4. Ablation
- 证明相对于加 RRCV 加了 LMF-MHSA 的效果会好一些。
- 标准CNN、残差模块和深度可分卷积模块,残差连接是有效的。
- LMF - MHSA 的参数量和FLOPs 都比 MHSA 少。
- LMF-MHSA 的 1 3 5 卷积核,多尺度特征提取在提高模型在不同视觉模式之间泛化能力方面的关键作用。
4. Reference
5. Additional
最近在做实验,晕头转向的,好久没好好读过论文了。
说有附录,但没看见附录。

















 3202
3202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









