






hi,大家好!
我是小李
目前研0
让我们一起探索深度学习吧!
二、线性模型
1. 数据集DateSet
在机器学习和深度学习中,通常会将数据集划分为测试数据集和训练数据集。
- 训练数据集主要用于模型的训练过程。模型通过在训练数据集上学习数据的模式、特征和规律,不断调整自身的参数以达到更好的性能表现。
- 训练数据集通常会进一步细分为两份,主要是:训练集:这是用来实际训练模型的主要部分,模型通过在训练集上的学习来调整参数和优化模型结构。验证集:用于在训练过程中评估模型的性能,比如验证模型在不同训练阶段的效果,以便确定合适的超参数、判断是否出现过拟合等。通过验证集的反馈,我们可以对模型进行调整和改进,它起到了一个中间监测和调整的作用。
- 测试数据集则用于评估训练好的模型的性能。它独立于训练数据集,通过在测试数据集上进行预测或评估,来检验模型的泛化能力、准确性、召回率等指标,以了解模型在新数据上的实际表现效果,这样可以更客观地判断模型的优劣。
1.1 难题--过拟合
过拟合是指模型在训练数据上表现得非常好,但在面对新数据或测试数据时,性能却显著下降的现象。
1.2 泛化
泛化能力指的是模型对未见过的数据(即不在训练集中的数据)的预测或处理能力。一个具有良好泛化能力的模型,不仅能够在训练数据上表现出色,而且能够准确地对新的、未曾接触过的数据进行合理的预测或分析。 理想情况下,我们希望模型能够从训练数据中学习到一般性的规律和模式,而不是仅仅记住训练数据中的具体细节,这样它在面对新数据时才能做出准确的推断。如果模型的泛化能力差,就容易出现过拟合等问题,导致其在实际应用中表现不佳。评估和提高模型的泛化能力是机器学习研究和实践中的关键任务之一。
1.3 Training Loss
“训练损失”(Training Loss)通常指在机器学习或深度学习模型训练过程中,用于衡量模型预测结果与真实值之间差异程度的一个指标。 它反映了模型在训练集上的误差情况,通过计算某种损失函数(如均方误差、交叉熵等)的值来表示。随着训练的进行,目标是逐渐减小训练损失,以提高模型的性能和准确性。
1.4 Mean Squared Error
均方误差,它是一种常用的用于衡量预测值与真实值之间平均差异程度的指标。具体计算是将预测值与真实值的差值的平方进行平均。均方误差越小,说明模型的预测效果越好。

2. 代码及相关包
2.1 numpy
numpy详细教程(涵盖全部,看这一篇就够了)_numpy教程-CSDN博客
2.2 matplotlib
2.3 代码
2.3.1 课堂实践代码
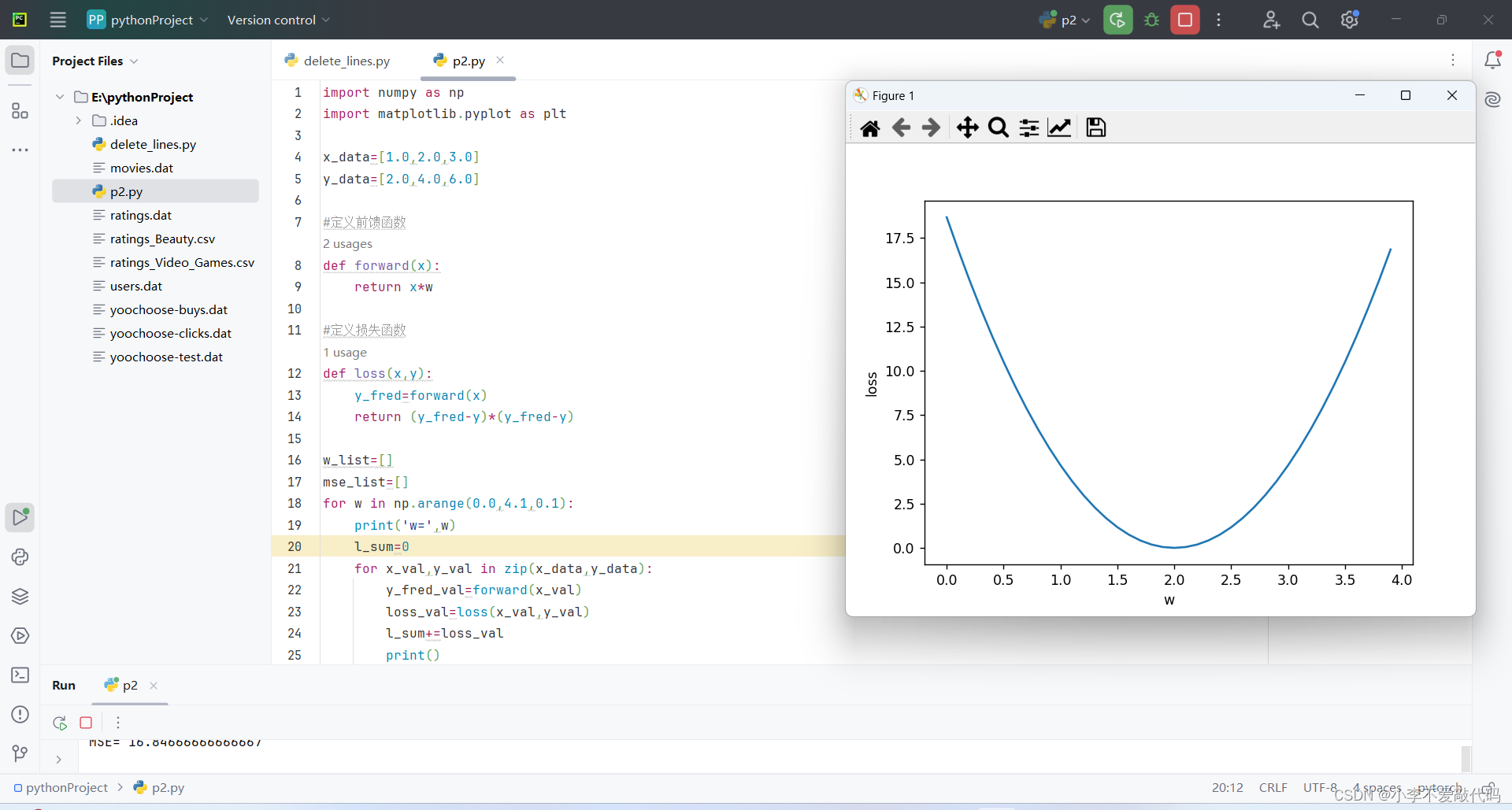
import numpy as np
import matplotlib.pyplot as plt
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
#定义前馈函数
def forward(x):
return x*w
#定义损失函数
def loss(x,y):
y_fred=forward(x)
return (y_fred-y)*(y_fred-y)
w_list=[]
mse_list=[]
for w in np.arange(0.0,4.1,0.1):
print('w=',w)
l_sum=0
for x_val,y_val in zip(x_data,y_data):
y_fred_val=forward(x_val)
loss_val=loss(x_val,y_val)
l_sum+=loss_val
print()
print(x_val,y_val,y_fred_val,loss_val)
print('MSE=',l_sum/3)
w_list.append(w)
mse_list.append(l_sum/3)
plt.plot(w_list,mse_list)
plt.ylabel('loss')
plt.xlabel('w')
plt.show()
2.3.2 作业
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
x_data = [1.0, 2.0, 3.0]
y_data = [4.0, 6.0, 8.0]
def forward(x):
return x * w + b
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) * (y_pred - y)
wb_list = []
mse_list = []
# f = open("res_Model_xw+b.txt", 'w+')
for w in np.arange(0.0, 4.1, 0.1):
for b in np.arange(0.0, 4.1, 0.1):
# print('w =', w, ', b =', b, file=f)
print('w =', w, ', b =', b)
l_sum = 0
loss_val = 0
for x_val, y_val in zip(x_data, y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val, y_val)
l_sum += loss_val
# print('\t', x_val, y_val, y_pred_val, loss_val, file=f)
print('\t', x_val, y_val, y_pred_val, loss_val)
# print('MSE =', l_sum / 3, file=f)
print('MSE =', l_sum / 3)
wb_list.append([w, b])
mse_list.append(l_sum / 3)
# Paint the 3D graph
w, b = np.meshgrid(np.arange(0.0, 4.1, 0.1), np.arange(0.0, 4.1, 0.1))
l_sum = 0
for x_val, y_val in zip(x_data, y_data):
loss_val = loss(x_val, y_val)
l_sum += loss_val
mse = l_sum / 3
#绘图
fig = plt.figure()
ax = Axes3D(fig)
fig.add_axes(ax)
ax.plot_surface(w, b, mse, ## x,y,z二维矩阵(坐标矩阵xv,yv,zv)
rstride=1, ## retride(row)指定行的跨度
cstride=1, ## retride(column)指定列的跨度
cmap='rainbow') ## 设置颜色映射
#设置标题
plt.title('y_hat = x * w + b')
plt.xlabel('w')
plt.ylabel('b')
plt.show()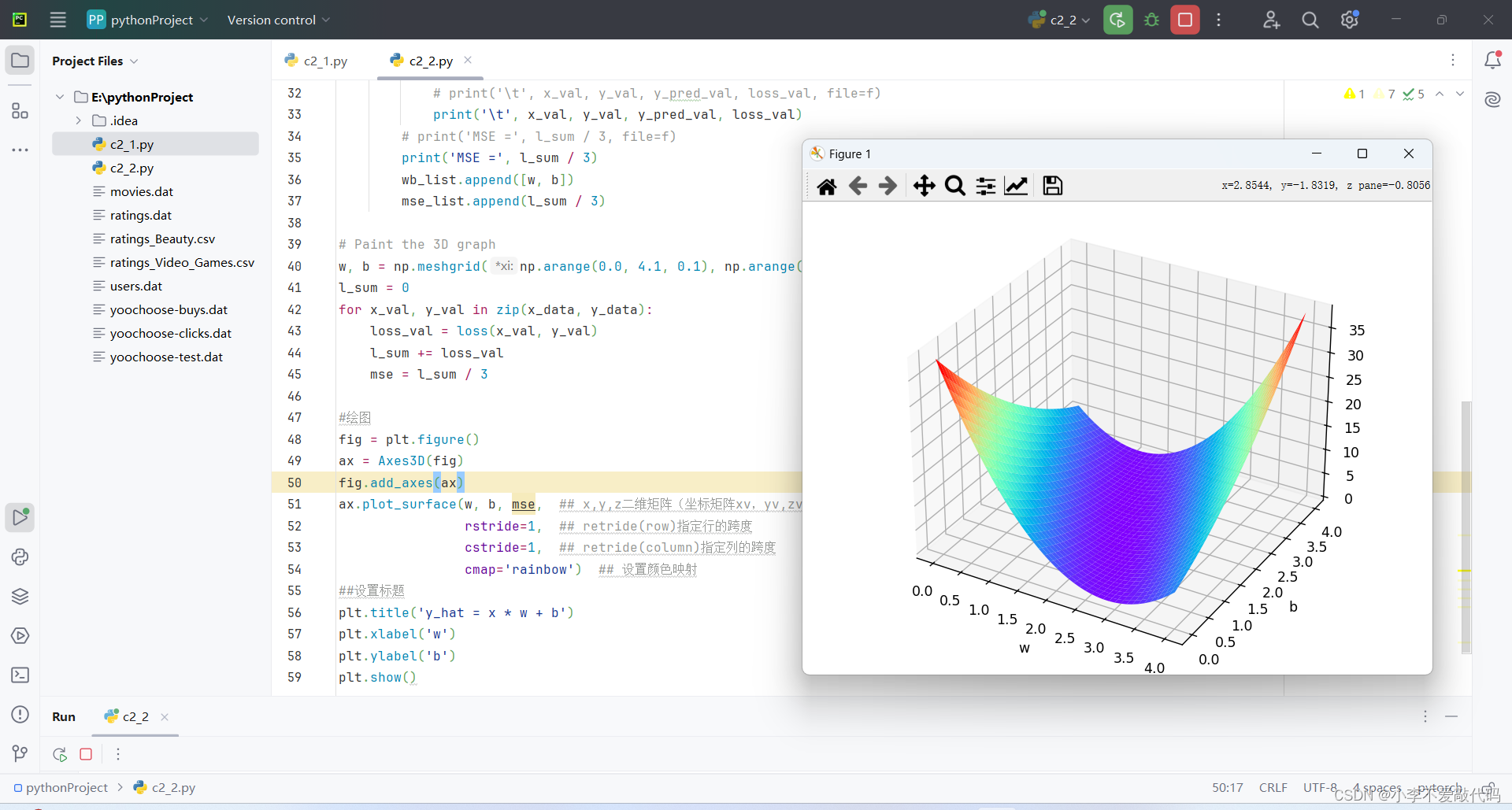
三、梯度下降算法
1.梯度下降概念
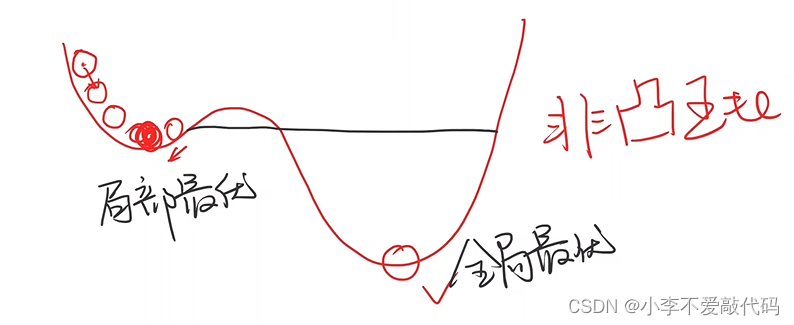
梯度下降算法是一种用于优化目标函数的迭代算法。该算法从一个初始点开始,通过不断沿着目标函数的负梯度方向移动来逐步逼近目标函数的最小值。在机器学习中,梯度下降算法常用于训练神经网络等模型,以最小化损失函数。
假设目标函数为 f(x),则梯度下降算法的基本步骤如下:
1. 选择一个初始点 x0。
2. 计算目标函数在当前点 xk 的梯度 gradf(xk)。
3. 沿着负梯度方向移动,即更新当前点 xk+1 = xk - lr * gradf(xk),其中 lr 是学习率,控制每次移动的步长。
4. 重复步骤 2 和 3,直到满足终止条件,例如达到最大迭代次数或目标函数的值收敛到一定范围内。
梯度下降算法有多种变体,例如随机梯度下降算法和小批量梯度下降算法等。这些变体在计算梯度时使用不同的方法,以提高算法的效率和准确性。 需要注意的是,梯度下降算法可能会陷入局部最小值而无法找到全局最小值。此外,学习率的选择也非常重要,如果学习率过大,算法可能会不稳定或发散;如果学习率过小,算法可能会收敛速度过慢。因此,在实际应用中,需要根据具体情况选择合适的学习率和算法变体。
公式:

2. 代码
2.1 课堂实践代码1
import matplotlib.pyplot as plt
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
w=1.0
#定义前馈函数
def forward(x):
return x*w
#定义损失值
def cost(xs,ys):
cost=0
for x,y in zip(xs,ys):
y_fred = forward(x)
cost+=(y_fred - y)**2
return cost/len(xs)
def gradient(xs,ys):
grad=0
for x, y in zip(xs, ys):
grad=2*x*(x*w-y)
return grad/len(xs)
epoch_array=[]
cost_array=[]
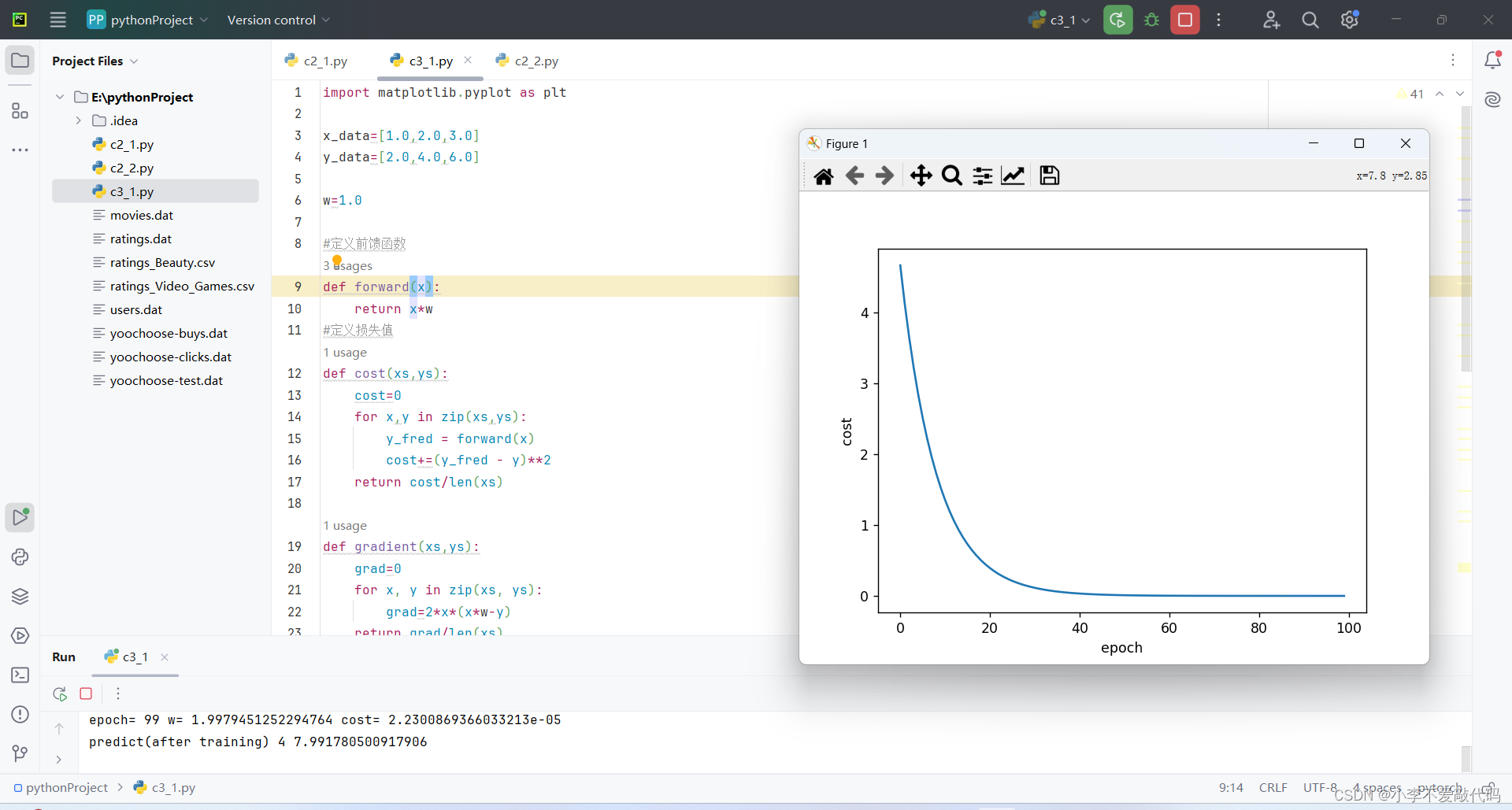
print("predict(before training)",4,forward(4))
for epoch in range(100):
cost_val=cost(x_data,y_data)
grad_val=gradient(x_data,y_data)
w-=0.01*grad_val
print('epoch=',epoch,'w=',w,'cost=',cost_val)
epoch_array.append(epoch)
cost_array.append(cost_val)
print("predict(after training)",4,forward(4))
#绘图
plt.plot(epoch_array,cost_array)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.show()
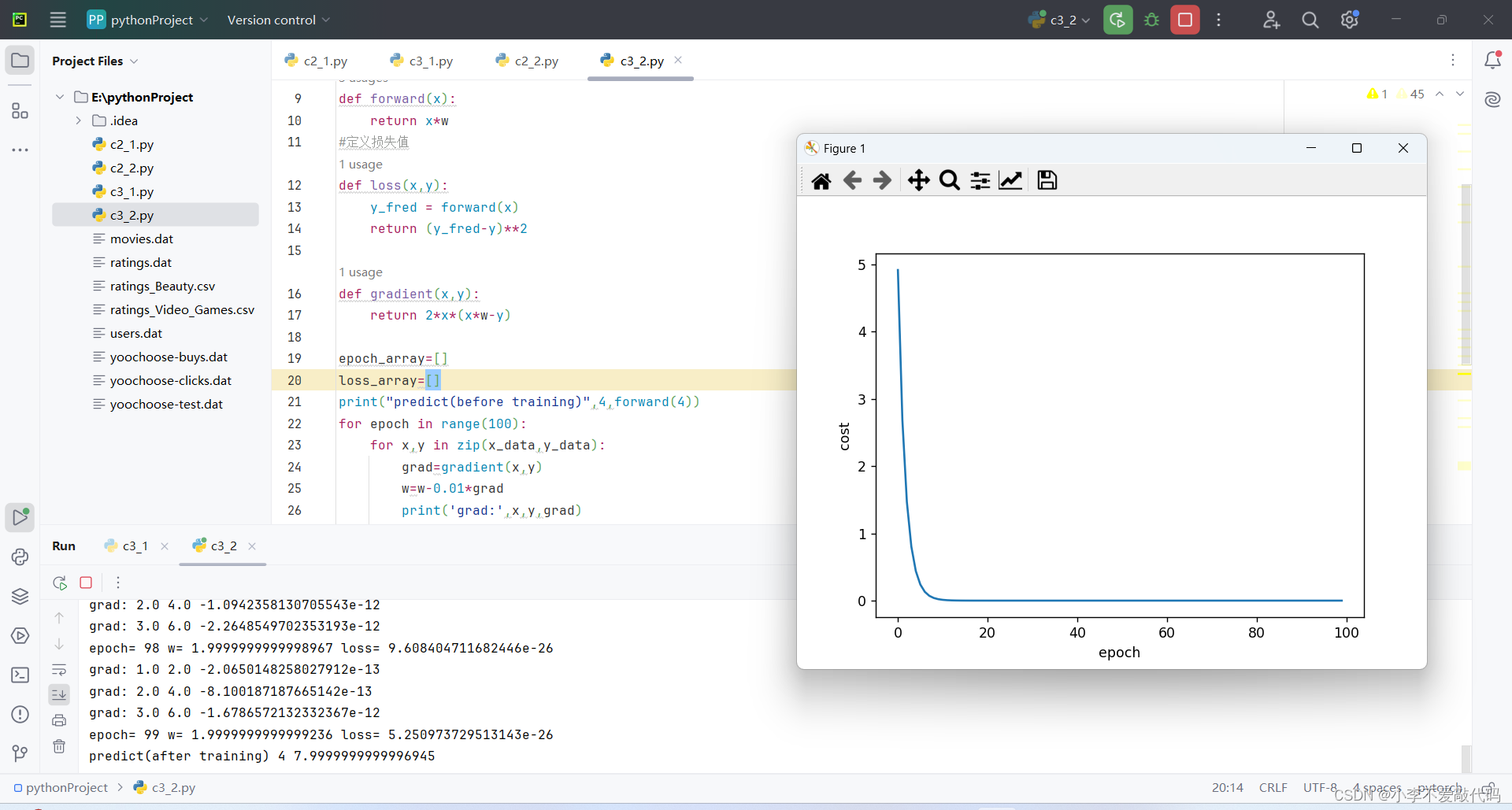
2.2 课堂实践代码2
import matplotlib.pyplot as plt
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
w=1.0
#定义前馈函数
def forward(x):
return x*w
#定义损失值
def loss(x,y):
y_fred = forward(x)
return (y_fred-y)**2
def gradient(x,y):
return 2*x*(x*w-y)
epoch_array=[]
loss_array=[]
print("predict(before training)",4,forward(4))
for epoch in range(100):
for x,y in zip(x_data,y_data):
grad=gradient(x,y)
w=w-0.01*grad
print('grad:',x,y,grad)
l=loss(x,y)
print('epoch=',epoch,'w=',w,'loss=',l)
epoch_array.append(epoch)
loss_array.append(l)
print("predict(after training)",4,forward(4))
#绘图
plt.plot(epoch_array,loss_array)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.show()
四、 反向传播
1. 矩阵计算公式------matrix-cook-book.pdf (pku.edu.cn)
2.















 463
463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









