







两部分
Part One 绕绕,可以不看
Cross entropy loss function又称交叉熵损失,是基于one_hot编码的。
举个例子,我们现在来完成一个判别任务,是cat则1,否则为0。那么我们输入一张图片,会面临以下两种概率,其中yhat代表概率,并且只代表cat的概率。
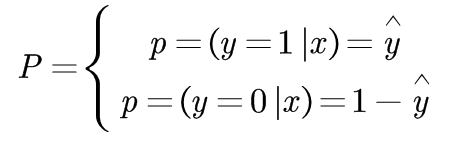
然后根据最大似然知识,我们得出下面式子。
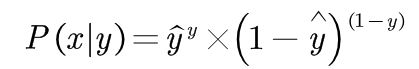
其他博客都略过了这里,所以我来尝试解释一下最大似然估计吧,根据概率论知识最大似然估计是用来估计yhat取某值的可能性的,例如我们现在随便设yhat=0.5,当p(x|y)=0的时候,说明yhat不可能等于0.5,当p(x|y)=1的时候说明yhat就等于0.5。但是现在比较特殊的情况是,当图片有猫,我们只能或只愿意设yhat=1,但是我自己说yhat等于1,孤证不立呀。所以我得拉拢p(x|y)来帮助我,p(x|y)的值越大,我就越有说服力。当p(x|y)=0.8的时候,yhat=1的概率就等于0.8。你们发现了没有,p(x|y)的概率就是最后的预测概率呀。也就是绕了一大个圈,p(x|y)意为判断正确的概率。那我们当然希望p(x|y)越大越好。
上面这一段话很绕,很难懂,建议手推一下。好了,那我们再将最大似然那条式子取对数代进去。我们熟悉的Cross entropy loss function就出来了。
Part Two 清晰易懂,一定要看
下面是针对判断是否有(有无cat的二分类),其中y表示是否是该物体(有则y=1,无则y=0),yhat代表是该物体的概率。
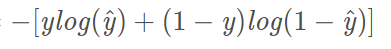
对于多分类,同理我们扩展了以下这个公式,其中y表示是否是该物体,yhat代表是该物体的概率,m代表物体的种类数目。
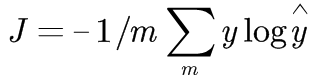
还需要说明的是:yhat是输入x经过神经网络,再经过softmax之后输出的概率。
最后是Pytorch的实现,需要注意的是无论是cat,dog还是其他animals,都必须转化为1,2,3之类的标签。这样系统才可以自行转化为one_hot进行训练。
loss_function = nn.CrossEntropyLoss()
















 767
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











