文章目录
- 一、ROC 曲线与 AUC 值
- 1. ROC 曲线绘制方法与 AUC 值计算方法
- 2. ROC-AUC 基本性质
- 接下来,我们进一步讨论关于ROC曲线AUC值的相关内容。
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from ML_basic_function import *
一、ROC 曲线与 AUC 值
1. ROC 曲线绘制方法与 AUC 值计算方法
- 除了 F1-Score 以外,还有一类指标也可以很好的评估模型整体分类效力,即 ROC 曲线与 AUC 值。
- 当然这二者其实是一一对应的,ROC(全称为Receiver operating characteristic,意为受试者特征曲线)是一个二维平面空间中一条曲线,而 AUC 则是曲线下方面积(Area Under Curve)的计算结果,是一个具体的值,例如下图所示:
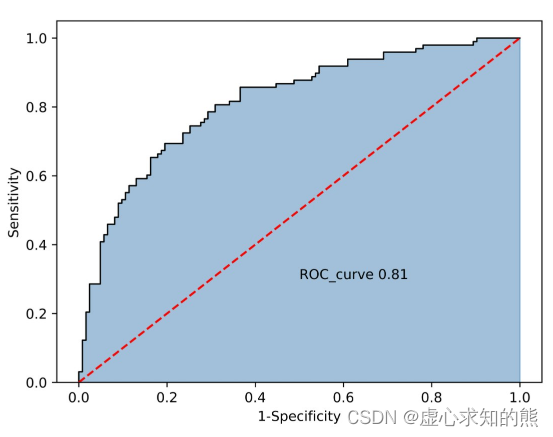
- 其实 ROC 和 AUC 是一一对应的,因此二者其实是同一个评估指标。
- ROC 曲线同样也是基于混淆矩阵衍生的二级指标来进行构建,该指标的计算有些类似于交叉熵的计算过程,会纳入分类模型的分类概率来进行模型性能的评估。
- 例如此前所说,对正例样本概率越大、负例样本概率越小,则模型性能越好。
- ROC 曲线绘制与 AUC 面积计算
- 接下来,我们来讨论 ROC 曲线的绘制过程。首先,假设逻辑回归对某一组数据分类结果如下,我们按照预测概率从大到小进行排序:
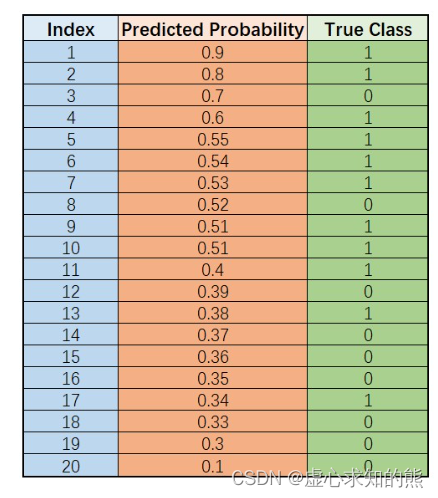
- 数据总共 20 条样本,11 条 1 类样本、9 条 0 类样本。
- 此时,我们从 1 开始逐渐降低阈值。
- 在阈值取值范围为 0.9-1 之间时,模型将判别所有样本都属于 0 类,对于上述数据集来说,有混淆矩阵计算结果如下:
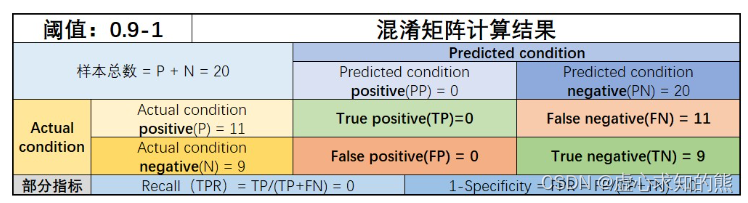
- 此时,我们令 FDR 为平面坐标的横坐标点、TPR 作为平面坐标的纵坐标点,就可以绘制出 ROC 曲线上的第一个点:(0, 0) 点。
- 当然,从此结果上仍然看不出其模型评估价值,为了绘制 ROC 曲线,我们还需要进一步调整阈值。
- 此时我们不断降低阈值,当阈值跨过 0.9 时,即介于 0.8 和 0.9 之间时,上述混淆矩阵计算结果将发生变化,此时模型将判别概率为 0.9 的样本为 1 类,其余样本为 0 类,此时上述混淆矩阵计算结果如下:

- 而此时我们就计算出了 ROC 曲线上的第二个点:(0, 0.09)。
- 如果我们进一步降低阈值,当阈值移动到 0.7 和 0.8 之间时,模型判别结果又将发生变化,我们可以继续计算此时的 TPR 和 FDR。
- 在不断调整阈值的过程中,阈值每跨越一个样本的预测概率,FDR 和 TPR 就会发生变化,最终,我们将阈值从 1 逐渐降低到 0 的过程中的所有计算结果放在数据表中进行观察:
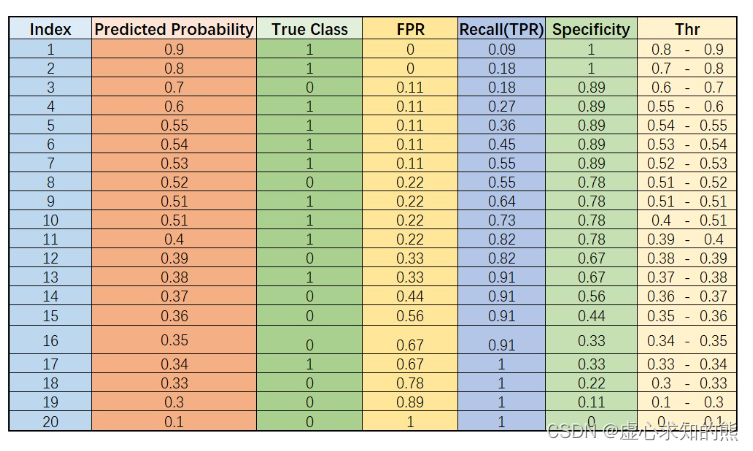
- 当然,我们也可以简单验证上述结果是否正确。例如,当阈值取值范围在 0.4-0.51 之间时,有一半样本被预测 1、另一半被预测为 0,此时混淆矩阵计算结果为:
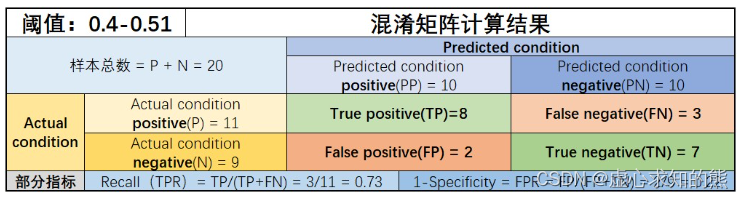
- 能够发现与表格中结果计算结果一致。
- 当然,FPR 和 TPR 计算结果还有另一个理解角度,那就是我们可以将 FPR 计算结果视作 0 类概率累计结果,TPR 视作 1 类概率累计结果。
- 对于上述数据,1 类数据共有 11 条,0 类数据共有 9 条,假设当阈值移动到某个位置时,阈值以上总共有 m 条 1 类样本、n 条 0 类样本,则此时 FPR=n/9,TPR=m/11。
- 例如当阈值移动到 0.6-0.7 之间时,m=2、n=1,此时 FPR=1/9=1.1,TPR=2/18。
- 当阈值完整从 1 移动 0 之后,我们即可把上述所有由 (FPR,TPR) 所组成的点绘制成一张折线图,该折线图就是 ROC 曲线图:
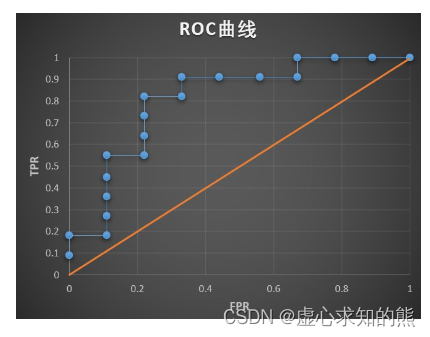
- 而此时,ROC 曲线下方面积就是 AUC 值。
- 根据上述描述,FPR 实际上是 0 类概率累计,TPR 实际上是 1 类概率累计,则自上而下观察 True Class 这一列,在原点为起始点时,每当出现一个 1 时,点就沿着 Y 轴正方向移动 0.9,每当出现一个 0 时,点就沿着 X 轴正方向移动 0.11,依次类推,最终从原点移动到 (1,1) 这个点的过程,就构成了 ROC 曲线。
2. ROC-AUC 基本性质
- 首先,由于 FPR 和 TPR 都是在 [0,1] 区间范围内取值,因此 ROC 曲线上的点分布在横纵坐标都在 [0,1] 范围内的二维平面区间内。
- 其次,对于任意模型来说,ROC 曲线越靠近左上方、ROC 曲线下方面积越大,则模型分类性能越好。
- 根据点的移动轨迹构成 ROC 曲线角度来理解,刚开始移动时,是朝向 X 还是 Y 轴正向移动,其实是有模型输出概率最高的几个样本决定的,如果这几个样本被判别错了(即实际样本类别为 0),则刚开始从原点移动就将朝着X轴正方向移动,此时曲线下方面积会相对更小(相比刚开始朝着Y轴正方向移动的情况)。
- 根据此前介绍的理论,此时由于模型对于“非常肯定”的样本都判错了,证明模型本身判别性能欠佳;而反之,如果输出概率最高的头部几条样本都判断正确,样本真实类别确实属于 1,则点开始移动时将朝向 Y 轴正方向移动,此时曲线下方面积就将相对更大,模型判别性能也将相对较好。此处可以举例说明:
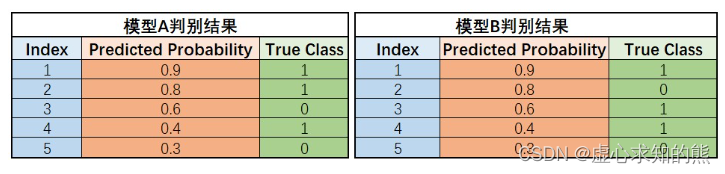
- 上述两个模型对于同一组数据的建模结果差异,可以简单看成模型 A 中概率结果为 0.8 和 0.6 的两条样本,在模型 B 中被识别为 0.6 和 0.8,两条样本结果互换。
- 例如,在 0.5 为阈值的情况下,模型 A 和 B 同样准确率是 80%,但模型 A 是将概率为 0.6 的 1 类样本误判为 0 类、将概率为 0.4 的样本误判为 1 类,尚且有情可原,毕竟 0.6 和 0.4 的模型输出结果代表着模型其实并没有对这两类样本的所属情况有非常强的肯定。
- 但对于模型 B 来说,有一条概率结果为 0.8 的样本被误判,则说明模型 B 对于一条“非常肯定”属于 1 类的样本判断是错误的,B 模型的“错误”更加“严重”,模型判别性能相对较弱,ROC 曲线下方面积相对较小。
- 我们可以在 ROC 曲线上能够进行非常清楚的展示,接下来就可以通过代码实现上述两个模型的 ROC 曲线绘制:
- 从这个角度来看,ROC-AUC 对模型的分类性能评估和交叉熵计算结果类似。
thr_l = np.linspace(1, 0, 100)
yhat_A = np.array([0.9, 0.8, 0.6, 0.4, 0.3]).reshape(-1, 1)
y_A = np.array([1, 1, 0, 1, 0]).reshape(-1, 1)
yhat_B = np.array([0.9, 0.8, 0.6, 0.4, 0.3]).reshape(-1, 1)
y_B = np.array([1, 0, 1, 1, 0]).reshape(-1, 1)
y_cla = logit_cla(yhat_A, thr=0.5)
P = y_cla[y_A == 1]
TPR = P.mean()
TPR
logit_cla(yhat_A, thr=0.5)
y_A
3 [0]])
[y_A == 1]
logit_cla(yhat_A, thr=0.5)[y_A == 1].mean()
N = y_cla[y_A == 0]
FPR = N.mean()
FPR
y_cla = logit_cla(yhat_A, thr=0.5)
y_cla
y_A
[y_A == 0]
y_cla[y_A == 0].mean()
def ROC_curve(yhat, y, thr_l, label='ROC_curve'):
"""
ROC绘制曲线函数:
:param yhat: 模型输出的类别概率判别结果
:param y: 样本真实类别
:param thr_l:阈值取值列表
:param label:折线图的图例
:return :ROC曲线绘制图
"""
TPR_l = []
FPR_l = []
for i in thr_l:
y_cla = logit_cla(yhat, thr=i)
P = y_cla[y == 1]
TPR = P.mean()
TPR_l.append(TPR)
N = y_cla[y == 0]
FPR = N.mean()
FPR_l.append(FPR)
plt.plot(FPR_l, TPR_l, label=label)
thr_l
ROC_curve(yhat_A, y_A, thr_l, label='Model A')
ROC_curve(yhat_B, y_B, thr_l, label='Model B')
plt.plot([0, 1], [0, 1], 'r--')
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.title('ROC_curve')
plt.legend(loc = 4)
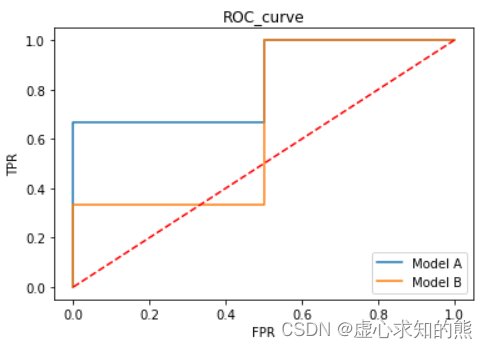
- 不难发现,模型 A 的 ROC 曲线整体更加趋于空间左上方,并且曲线下方面积更大,说明模型 A 实际判别性能更好。
- 当然,我们也可以针对此前介绍的逻辑回归模型预测结果来进行 ROC 曲线绘制。
np.random.seed(24)
f, l = arrayGenCla(num_class = 2, deg_dispersion = [4, 2], bias = True)
mean_ = f[:, :-1].mean(axis=0)
std_ = f[:, :-1].std(axis=0)
f[:, :-1] = (f[:, :-1] - mean_) / std_
np.random.seed(24)
batch_size = 50
num_epoch = 200
lr_init = 0.2
n = f.shape[1]
w = np.random.randn(n, 1)
lr_lambda = lambda epoch: 0.95 ** epoch
for i in range(num_epoch):
w = sgd_cal(f, w, l, logit_gd, batch_size=batch_size, epoch=1, lr=lr_init*lr_lambda(i))
yhat = sigmoid(f.dot(w))
ROC_curve(yhat, l, thr_l)
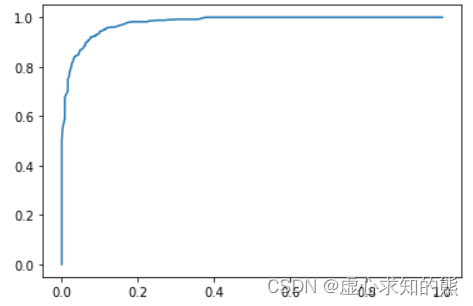
- 由于构成 ROC 曲线的点分布在一个平面面积为 1 的空间内,因此 ROC 曲线下方面积——AUC 的取值范围在 0-1 之间,并且,当 AUC 大于 0.5 时,模型对于该分类问题有一定的分类效力,分类结果好于盲猜;而当 AUC 取值为 0.5 时,则说明模型分类效果和忙猜差不了太多,此时极有可能出现如下情况:
[1, 0, 0, 1]*5
np.linspace(1, 0, 40)
y = np.array([1, 0, 0, 1]*10).reshape(-1, 1)
y_hat = np.linspace(1, 0, 40).reshape(-1, 1)
ROC_curve(yhat=y_hat, y=y, thr_l=thr_l)
plt.plot([0, 1], [0, 1], 'r--')
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.title('AUC≈0.5')
plt.legend(loc = 4)
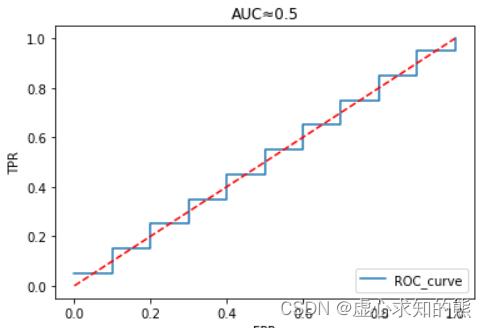
- 即对于某条样本来说,无论输出概率结果如何(无论模型预测概率多少),从最终和真实标签的比对结果来看,某条样本被模型判断正确或者错误的概率都是 50%,也就和盲猜的结果接近,此时模型并没有任何判别效力。
- 而在某些情况下,AUC 的取值会小于 0.5,此时 ROC 曲线将出现在平面对角线的下方,而当这种情况发生时,往往说明大多数样本的真实类别都和模型判别类别正好相反。并且,越是高概率样本真实标签为 0,ROC 曲线就越贴近空间右下方、AUC 值就越小。
np.array(([0]*10 + [1]*10) * 5)
y = np.array(([0]*10 + [1]*10) * 5).reshape(-1, 1)
y_hat = np.linspace(1, 0, 100).reshape(-1, 1)
ROC_curve(yhat=y_hat, y=y, thr_l=thr_l)
plt.plot([0, 1], [0, 1], 'r--')
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.title('AUC less than 0.5')
plt.legend(loc = 4)
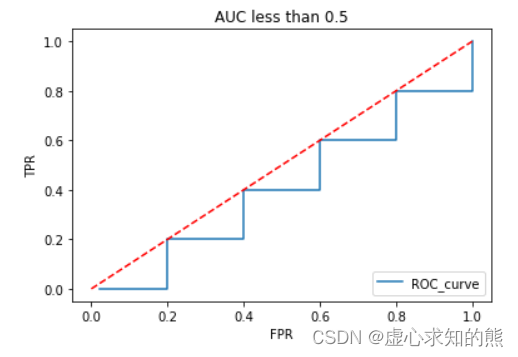
- 值得注意的是,尽管当 AUC 取值小于 0.5 时,模型输出的概率结果本身并不可用,但此时“大多数样本都正好判别错误”其实也说明模型具有一定的判别效力,因此我们“或许”可以考虑通过将模型判别结果进行“反向处理”,即模型判别结果 0、1 互换。
- 然后用这组数值进行预测。但需要注意的是,这样的结果哪怕有一定的预测作用但也没有任何的理论依据作为支撑,因此此时的模型仍然不可用。
- ROC 的概率敏感特性与偏态数据判别
- 此外,如果数据是偏态数据,由于 ROC 是对概率敏感的判别曲线(根据概率结果而非类别判别结果进行识别),因此 ROC 能够对模型对于偏态数据中少量样本的识别能力进行评估。
- 例如,假设一个包含十条数据的小样本数据集,其中包含 9 条 0 类样本、1 条 1 类样本,同样我们利用两个模型进行判别,模型判别结果如下所示:
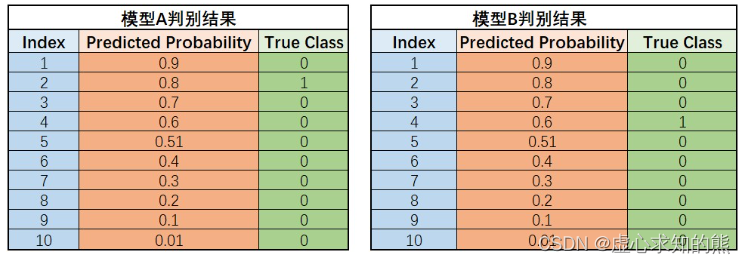
- 则对于这两个模型来说,在阈值为 0.5 的情况下,准确率都是 60%,且 F1-Score 都是 0.33。
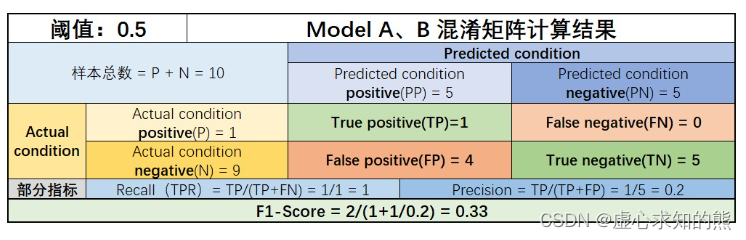
- 但由于 ROC 是概率敏感的评估指标,对于不同的两个模型,只要在不同类别的概率计算结果分布上有所差异,最终 ROC 的绘制情况都会不同。
- 对于上述两个模型来说,我们可以通过如下方式绘制两个不同模型的 ROC 曲线:
yhat = np.array([0.9, 0.8, 0.7, 0.6, 0.51, 0.4, 0.3, 0.2, 0.1, 0.01]).reshape(-1, 1)
np.eye(10)
y_A = np.eye(10)[:,1:2]
y_A
y_B = np.eye(10)[:,3:4]
y_B
ROC_curve(yhat, y_A, thr_l, label='Model A')
ROC_curve(yhat, y_B, thr_l, label='Model B')
plt.plot([0, 1], [0, 1], 'r--')
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.title('ROC_curve')
plt.legend(loc = 4)
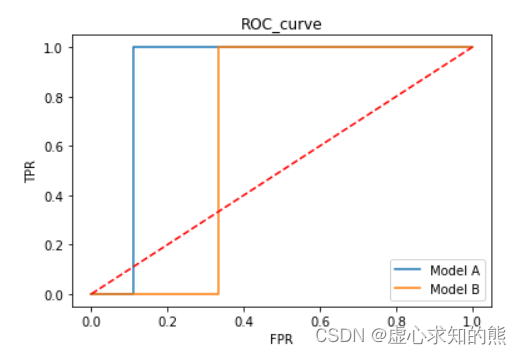
- 很明显,从最终 AUC 面积来看,模型 A 效果好于模型 B,对概率敏感,也使得 ROC 在很多情况下具有比 F1-Score 更加敏感的模型性能的识别精度。
- 从上述结果中能够看出,ROC 和 F1-Score 类似,少数的 1 类样本的判别结果会很大程度影响 AUC 的计算结果,因此 ROC-AUC 也能用于判别模型在偏态样本上的分类能力。
- ROC 排序敏感
- 其实,如果我们更加深入的进行思考和观察,我们会发现,ROC-AUC 其实是对根据模型预测的概率结果降序排序后的数据真实标签的各元素位置敏感。
- 例如,对于下述 A、B 两个模型,尽管在部分样本的预测概率不同,但由于最终的按照预测概率降序排序的真实标签排序相同,因此两个模型最终绘制的 ROC 曲线相同。
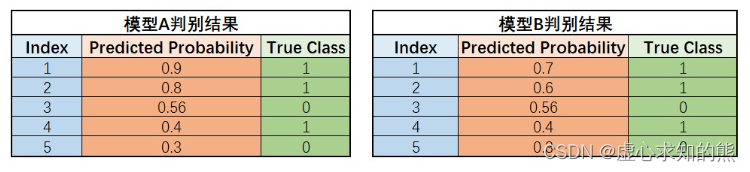
thr_l = np.linspace(1, 0, 100)
yhat_A = np.array([0.9, 0.8, 0.56, 0.4, 0.3]).reshape(-1, 1)
y_A = np.array([1, 1, 0, 1, 0]).reshape(-1, 1)
yhat_B = np.array([0.7, 0.6, 0.56, 0.4, 0.3]).reshape(-1, 1)
y_B = np.array([1, 1, 0, 1, 0]).reshape(-1, 1)
ROC_curve(yhat_A, y_A, thr_l, label='Model A')
ROC_curve(yhat_B, y_B, thr_l, label='Model B')
plt.plot([0, 1], [0, 1], 'r--')
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.title('ROC_curve')
plt.legend(loc = 4)
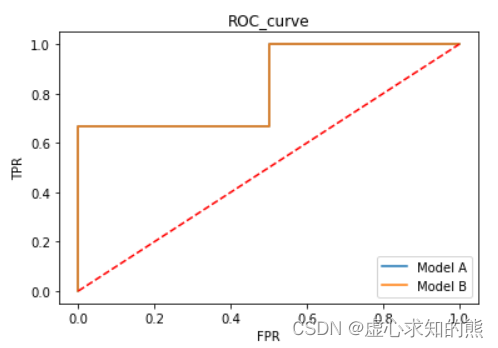
- 当然,ROC 这种排序特性会导致其在某些情况下失去判别效力。
- 首先,在以交叉熵作为损失函数建模时,对于性能较好的模型有时会有过拟合倾向,而由于 ROC 只对排序敏感,因此有时也会消除这种过拟合倾向;其次,我们也可以通过适当调整阈值来手动让其变得概率敏感。
- ROC 的类别对称性与 F1-Score 指标的比较
- 据上述讨论,我们已经知道 ROC 由于是概率敏感,所以相比 F1-Socre,ROC 其实能够对模型的判别能力有更深刻的评判。此外,ROC 还有另外一个特性——那就是类别对称性。
- 在此前介绍 F1-Socre 的时候,我们讨论,F1-Score 并不是类别对称的,而是更加侧重于评估模型在识别 1 类样本时的整体性能,但 ROC 却是类别对称的,即如果我们将数据中的 0 和 1 类互换。
- 而模型原先预测 1 的类概率就变成了现在预测 0 类的概率,此时 ROC 曲线会参照
x
+
y
=
1
x+y=1
x+y=1 的直线进行对称变换,但 AUC 面积不变,即模型性能评估数值仍然不会发生变化。
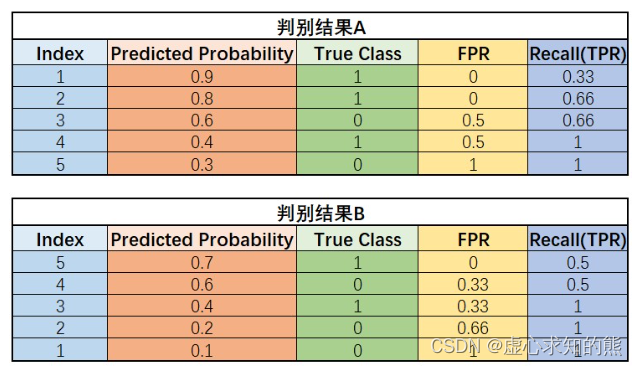
- 我们可以通过如下实验来进行验证,对于同样一组数据,采用模型分别对原数据和翻转后数据进行判别,得到结果 A 和 B:
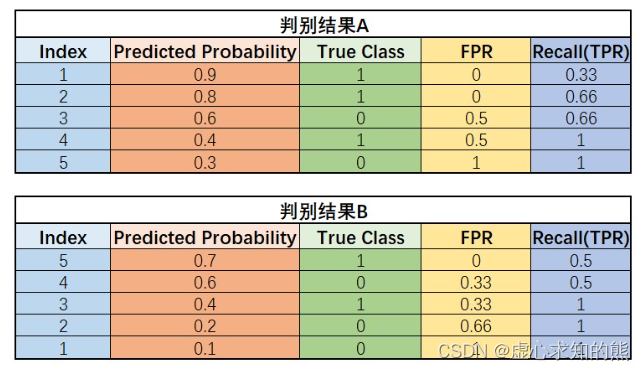
thr_l = np.linspace(1, 0, 100)
yhat_A = np.array([0.9, 0.8, 0.6, 0.4, 0.3]).reshape(-1, 1)
y_A = np.array([1, 1, 0, 1, 0]).reshape(-1, 1)
ROC_curve(yhat_A, y_A, thr_l, label='Result A')
plt.plot([0, 1], [0, 1], 'r--')
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.title('ROC_curve')
plt.legend(loc = 4)
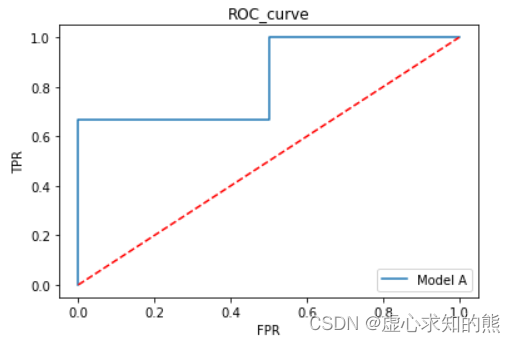
yhat_B = np.array([0.7, 0.6, 0.4, 0.2, 0.1]).reshape(-1, 1)
y_B = np.array([1, 0, 1, 0, 0]).reshape(-1, 1)
ROC_curve(yhat_B, y_B, thr_l, label='Result B')
plt.plot([0, 1], [0, 1], 'r--')
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.title('ROC_curve')
plt.legend(loc = 4)
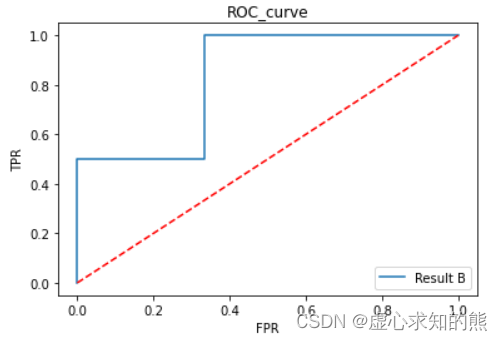
plt.subplot(121)
ROC_curve(yhat_A, y_A, thr_l, label='Result A')
plt.legend(loc = 4)
plt.subplot(122)
ROC_curve(yhat_B, y_B, thr_l, label='Result B')
plt.legend(loc = 4)
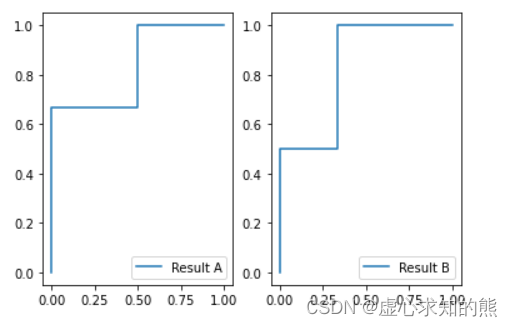
- 结合上述两组结果的 FPR 和 TPR 计算结果,我们不难发现,二者的 AUC 计算结果都是
1
−
0.5
∗
(
1
−
0.66
)
=
0.83
1−0.5∗(1−0.66)=0.83
1−0.5∗(1−0.66)=0.83 ,而这也正是由于两个 ROC 曲线围绕
x
+
y
=
1
x+y=1
x+y=1 对称所导致的。
- 因此,尽管同样是衡量模型整体评估性能,但相比之下,F1-Score 更加倾向于判别模型对 1 类样本的识别能力,而 ROC-AUC 则没有这方面的倾向性。
- 因此,ROC-AUC 和 F1-Score 之间的选取问题,同样也需要根据业务需要来进行选择,如果需要重点考虑 1 类是否被正确识别,则更加倾向选择 F1-Score,但如果没有其他特殊要求,则一般会考虑使用 ROC-AUC 作为模型评估指标。








 文章详细介绍了ROC曲线和AUC值的概念及其关系,包括ROC曲线的绘制方法、AUC值的计算以及它们的基本性质。通过实例展示了ROC曲线的绘制过程,解释了AUC值如何反映模型分类性能,并与F1-Score进行了对比。ROC曲线的类别对称性和概率敏感性是其重要特性,适合评估模型在偏态数据上的表现。
文章详细介绍了ROC曲线和AUC值的概念及其关系,包括ROC曲线的绘制方法、AUC值的计算以及它们的基本性质。通过实例展示了ROC曲线的绘制过程,解释了AUC值如何反映模型分类性能,并与F1-Score进行了对比。ROC曲线的类别对称性和概率敏感性是其重要特性,适合评估模型在偏态数据上的表现。


















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











