






1. 相关术语解释
| 正例 | 负例 | |
|---|---|---|
| 预测正 | 真正例 (true positive, TP) | 假正例 (false positive, FP) |
| 预测负 | 假负例 (false negative, FN) | 真负例 (true negative, TN) |
- 真正例率 (true positive ratio) :
,表示的是所有正例中被预测为正例的比例
- 假正例率 (false positive ratio):
,表示所有负例中被错误地预测为正例的比例
- 精确度 (precision):
,表示所有预测为正的样本中真正为正样本的比例
- 召回率 (recall):
,表示的是所有正例中被预测为正例的比例
2. ROC-AUC 与 PR-AUC
2.1 定义及计算
ROC,Receiver Operation Characteristics
AUC,Area Under Curve
ROC-AUC 指的是 ROC 曲线下的面积
通过在 [0, 1] 范围内选取阈值 (threshold) 来计算对应的 TPR 和 FPR,最终将所有点连起来构成 ROC 曲线。
一个没有任何分类能力的模型,意味着 TPR 和 FPR 将会相等 (所有正例将会有一半被预测为正例,所有负例也将会有一半被预测为正例),这时 ROC 曲线将会如下图蓝色虚线所示。
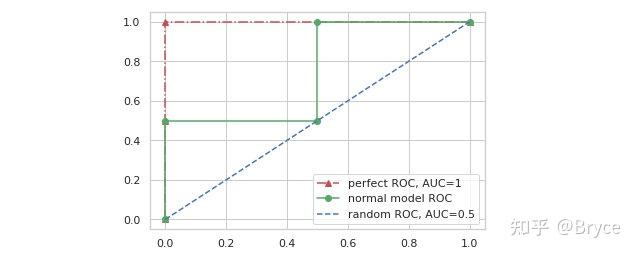
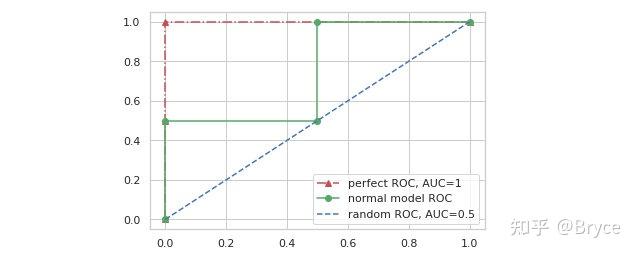
那么在 ROC-AUC 的衡量下,一个理想模型的输出应该是怎样的呢?可以从 TPR 和 FPR 的定义出发,我们肯定是希望理想中的模型在面对正样本时预测为正的概率一定比面对负样本时预测为正的概率大,假设有样本标签和模型预测概率如下:
y = np.array([0, 0, 1, 1])
pred = np.array([0.1, 0.4, 0.45, 0.8])现在分别选择 5 个阈值 0,0.3,0.42,0.6,1,TPR 和 FPR 如下:
- 阈值等于 0 时:
2. 阈值等于 0.3 时:
3. 阈值等于 0.42 时:
4. 阈值等于 0.6 时:
5. 阈值等于 1 时:
连接以上 5 个点,得到上图中红色点划线,显然,此曲线下的面积等于 1,是 ROC-AUC 所能取到的最大值,这个例子对应的模型就是我们理想中的模型,所有正例对应的模型输出都大于负例的模型输出。绿色实现代表了某个我们训练的这是模型,其 ROC-AUC 值介于 0-1 之间。
PR-AUC 的构造和上述过程基本一致,只是需要再计算出 Precision 和 Recall。PR 曲线可能如下图所示:
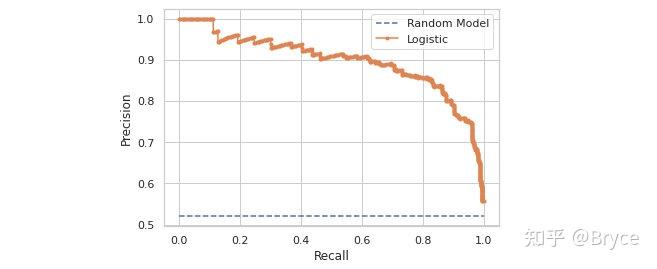

黄色对应逻辑回归模型的能力,比较正常没什么特别,按照前面的计算方式计算出来就可以得到。蓝色水平虚线代表的是完全随机的未经过学习的模型,为什么水平呢?举个例子,假设现在有 m 个正样本,n 个负样本,现在分别取阈值 0,1/3,0.5
- 阈值为 0 时:
- 阈值为 1/3 时:
- 阈值为 0.5 时:
通过以上几个阈值可以发现一个随机模型的 PR 曲线 Precision 值为正样本占总样本的比例,Recall 的范围在 0-1之间。当阈值取 1 或者说大于 1 时,此时 TP 等于 0,,这个点对于蓝色水平虚线像一个异常点,实际上使用 sklearn 中的 api 计算可以发现使用的 thresholds 中没有大于等于 1 的,全部小于 1,这点和 ROC-AUC 不同。以上解释了随机模型的 PR-AUC 为什么是一条水平线。
2.2 分析
所以,ROC-AUC 衡量的是模型排序的能力,并不取决于某一个阈值,不像 accuracy、precision、recall、f1 等指标。提到 ROC-AUC 大家的第一反应可能是当数据集不平衡时使用这个指标较好,但事实真的如此吗?PR-AUC 同样不依赖于阈值。
假设现在有 100 个正样本,10000 个负样本,常举的一个例子是,模型只要全部预测为负样本,accuracy 就可以达到 0.99,看上去非常 nice,但实际上模型啥也没学到,此时 ROC 的 TPR 等于 0、 FPR 等于 0,结果非常糟糕。再考虑 Precision 和 Recall,显然它们也都是 0,同样能够反映出模型的真实能力。
此时可能我们会对负样本进行下采样,然后训练好的模型可能不会再那么愚蠢了,此时存在一个问题:使用下采样前的样本进行评估还是下采样后的样本呢?分析一下 TPR 和 FPR 的表达式,此时模型已经训练好,它的能力是不会发生改变的,我们采样的也只是负样本,所以 TPR 不会受到采样的影响。再看 FPR,实际上 FPR 也只是在负样本中进行计算,采样对 FP 和 TN 带来的影响是一样的,下采样会导致它们同比例下降,所以下采样对于 FPR 也不会有影响。综上,ROC-AUC 的评估并不会随着样本比例发生改变。
那 Precision 和 Recall 呢?Recall 等于 TPR 保持不变,而 Precision 分母中的 FP 会因为进行下采样而减小,Precision 因此会增大,所以如果用下采样后的样本评估 Precision 和 F1,它们都会被高估。
现在考虑另外一个问题,假设模型目前能够正确预测出 100 个正样本中的 80 个,10000 个负样本中的 9000 个,此时:
假设现在模型能力提升了,模型目前能够正确预测出 100 个正样本中的 80 个,10000 个负样本中的 9900 个,此时:
模型的提升在 ROC-AUC 的坐标轴上体现非常小,FPR 从 0.1 降低到 0.01,而在 PR 曲线上 P 从 0.074 增加到 0.444。虽然在数值的倍数上看,FPR 是提高了 100 倍,更大,但是体现在曲线上,由于其数量级太小,并不会给人观感上提升的感觉;相反,PR-AUC 上的数量级比 ROC-AUC 大得多,有着肉眼可见的提升。所以在面对不平衡数据集的时候,ROC-AUC 貌似并不是最佳的选择,PR-AUC 更能体现出模型的性能提升。
3. 使用场景和 Python 计算
所以当类别相对来说较均衡时,可以使用 ROC-AUC,当类别极其不均衡时使用 PR-AUC 较好。
那为什么不只使用 PR-AUC 呢?ROC-AUC 对于分类模型来说存在的意义是什么?
看了许多文章多采用一个说法:从各自两个指标来看,TPR 和 FPR 分别聚焦于模型对正样本和负样本的分类能力,而 Precision 和 Recall 都是针对正样本的指标,没有考虑负样本。所以当我们希望模型在正负样本上都能表现较好时使用 ROC-AUC 衡量,如果我们只关注模型对正样本的分辨能力使用 PR-AUC 更好。但是菜鸟本鸟我并没能理解 ,这个坑先放着。
- ROC-AUC 相关代码:
# roc curve and auc
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
from matplotlib import pyplot
# generate 2 class dataset
X, y = make_classification(n_samples=1000, n_classes=2, random_state=1)
# split into train/test sets
trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.5, random_state=2)
# generate a no skill prediction (majority class)
ns_probs = [0 for _ in range(len(testy))]
# fit a model
model = LogisticRegression(solver='lbfgs')
model.fit(trainX, trainy)
# predict probabilities
lr_probs = model.predict_proba(testX)
# keep probabilities for the positive outcome only
lr_probs = lr_probs[:, 1]
# calculate scores
ns_auc = roc_auc_score(testy, ns_probs)
lr_auc = roc_auc_score(testy, lr_probs)
# summarize scores
print('No Skill: ROC AUC=%.3f' % (ns_auc))
print('Logistic: ROC AUC=%.3f' % (lr_auc))
# calculate roc curves
ns_fpr, ns_tpr, _ = roc_curve(testy, ns_probs)
lr_fpr, lr_tpr, _ = roc_curve(testy, lr_probs)
# plot the roc curve for the model
pyplot.plot(ns_fpr, ns_tpr, linestyle='--', label='No Skill')
pyplot.plot(lr_fpr, lr_tpr, marker='.', label='Logistic')
# axis labels
pyplot.xlabel('False Positive Rate')
pyplot.ylabel('True Positive Rate')
# show the legend
pyplot.legend()
# show the plot
pyplot.show()- PR-AUC 相关代码:
# precision-recall curve and f1
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import f1_score
from sklearn.metrics import auc
from matplotlib import pyplot
# generate 2 class dataset
X, y = make_classification(n_samples=1000, n_classes=2, random_state=1)
# split into train/test sets
trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.5, random_state=2)
# fit a model
model = LogisticRegression(solver='lbfgs')
model.fit(trainX, trainy)
# predict probabilities
lr_probs = model.predict_proba(testX)
# keep probabilities for the positive outcome only
lr_probs = lr_probs[:, 1]
# predict class values
yhat = model.predict(testX)
lr_precision, lr_recall, _ = precision_recall_curve(testy, lr_probs)
lr_f1, lr_auc = f1_score(testy, yhat), auc(lr_recall, lr_precision)
# summarize scores
print('Logistic: f1=%.3f auc=%.3f' % (lr_f1, lr_auc))
# plot the precision-recall curves
no_skill = len(testy[testy==1]) / len(testy)
pyplot.plot([0, 1], [no_skill, no_skill], linestyle='--', label='No Skill')
pyplot.plot(lr_recall, lr_precision, marker='.', label='Logistic')
# axis labels
pyplot.xlabel('Recall')
pyplot.ylabel('Precision')
# show the legend
pyplot.legend()
# show the plot
pyplot.show()参考:
- 如何理解机器学习和统计中的AUC?
- F1 Score vs ROC AUC vs Accuracy vs PR AUC: Which Evaluation Metric Should You Choose?
- Precision-Recall AUC vs ROC AUC for class imbalance problems
- Precision - Recall Curve, a Different View of Imbalanced Classifiers
- Imbalanced data & why you should NOT use ROC curve
- 深入理解AUC
- How to Use ROC Curves and Precision-Recall Curves for Classification in Python
- ROC vs precision-and-recall curves















 734
734











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









