import numpy as np
t11 = np.array([1,2,3,4])
type(t1)
numpy.ndarray
t22 = np.array(range(10))
print("t2=np.array(range(10)) = ",t2)
print("type(t2)=",type(t2))
t33 = np.arange(10)
print("t3=np.arange(10) = ",t3)
print("type(t3)=",type(t3))
t2=np.array(range(10)) = [[4394029 320053 5931 46245]
[7860119 185853 26679 0]
[5845909 576597 39774 170708]
...
[ 142463 4231 148 279]
[2162240 41032 1384 4737]
[ 515000 34727 195 4722]]
type(t2)= <class 'numpy.ndarray'>
t3=np.arange(10) = [0 1 2 3 4 5 6 7 8 9]
type(t3)= <class 'numpy.ndarray'>
t22.reshape(2,5)
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
us_file_path = "./youtube_video_data/US_video_data_numbers.csv"
uk_file_path = "./youtube_video_data/GB_video_data_numbers.csv"
t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int",unpack=True)
t2 = np.loadtxt(us_file_path,delimiter=",",dtype="int")
print('t1:',t1,'\n')
print('t2',t2,'\n')
print("*"*20)
t1: [[4394029 7860119 5845909 ... 142463 2162240 515000]
[ 320053 185853 576597 ... 4231 41032 34727]
[ 5931 26679 39774 ... 148 1384 195]
[ 46245 0 170708 ... 279 4737 4722]]
t2 [[4394029 320053 5931 46245]
[7860119 185853 26679 0]
[5845909 576597 39774 170708]
...
[ 142463 4231 148 279]
[2162240 41032 1384 4737]
[ 515000 34727 195 4722]]
********************
t22+1
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
t22**2
array([ 0, 1, 4, 9, 16, 25, 36, 49, 64, 81])
t=np.arange(24).reshape(4,6)
t
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
t<12
array([[ True, True, True, True, True, True],
[ True, True, True, True, True, True],
[False, False, False, False, False, False],
[False, False, False, False, False, False]])
t[t<12]=1
t
array([[ 1, 1, 1, 1, 1, 1],
[ 1, 1, 1, 1, 1, 1],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
np.where(t<12,0,12)
array([[ 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0],
[12, 12, 12, 12, 12, 12],
[12, 12, 12, 12, 12, 12]])
t
array([[ 1, 1, 1, 1, 1, 1],
[ 1, 1, 1, 1, 1, 1],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
t.clip(12,19)
array([[12, 12, 12, 12, 12, 12],
[12, 12, 12, 12, 12, 12],
[12, 13, 14, 15, 16, 17],
[18, 19, 19, 19, 19, 19]])
t[3,3:6]=9999
t
array([[ 1, 1, 1, 1, 1, 1],
[ 1, 1, 1, 1, 1, 1],
[ 12, 13, 14, 15, 16, 17],
[ 18, 19, 20, 9999, 9999, 9999]])
t
array([[ 1, 1, 1, 1, 1, 1],
[ 1, 1, 1, 1, 1, 1],
[ 12, 13, 14, 15, 16, 17],
[ 18, 19, 20, 9999, 9999, 9999]])
t.sum()
30153
t.sum(axis=0)
array([ 32, 34, 36, 10016, 10017, 10018])
t.sum(0)
array([ 32, 34, 36, 10016, 10017, 10018])
t.sum(axis=1)
array([ 6, 6, 87, 30054])
t.sum(1)
array([ 6, 6, 87, 30054])
- 中值mean 和 平均值median没有必然的关系。
- 中值是将所给的一组数从小到大或从大到小排列,奇数个数的话取中间的数字,偶数个数的话取中间两个数的平均数;而平均值就是把这组数相加,然后除以这组数的个数。
- 中值的优点是不受偏大或偏小数据的影响,很多情况下用它代表全体数据的一般水平更合适。如果数列中存在极端变量值,用中位数做代表值就比平均数更好。
t.mean()
1256.375
t.mean(0)
array([ 8. , 8.5 , 9. , 2504. , 2504.25, 2504.5 ])
t.mean(1)
array([1.000e+00, 1.000e+00, 1.450e+01, 5.009e+03])
np.median(t)
6.5
np.median(t,axis=0)
array([6.5, 7. , 7.5, 8. , 8.5, 9. ])
np.median(t,axis=1)
array([1.0000e+00, 1.0000e+00, 1.4500e+01, 5.0095e+03])
t
array([[ 1, 1, 1, 1, 1, 1],
[ 1, 1, 1, 1, 1, 1],
[ 12, 13, 14, 15, 16, 17],
[ 18, 19, 20, 9999, 9999, 9999]])
t.max()
9999
t.max(axis=0)
array([ 18, 19, 20, 9999, 9999, 9999])
t.min()
1
t.min(axis=0)
array([1, 1, 1, 1, 1, 1])
np.ptp(t)
9998
np.ptp(t,axis=0)
array([ 17, 18, 19, 9998, 9998, 9998])
t.std()
3304.409324580567
t.std(axis=0)
array([ 7.31436942, 7.79422863, 8.27647268, 4327.24404211,
4327.10026317, 4326.95652278])
t.std(axis=1)
array([0.00000000e+00, 0.00000000e+00, 1.70782513e+00, 4.99000003e+03])
import numpy as np
from matplotlib import pyplot as plt
uk_file_path = "./youtube_video_data/GB_video_data_numbers.csv"
t_uk = np.loadtxt(uk_file_path,delimiter=",",dtype="int")
print('最初的t_uk:',t_uk)
print('t_uk[:,1]<=500000:',t_uk[:,1]<=500000)
print('t_uk[t_uk[:,1]<=500000]:',t_uk[t_uk[:,1]<=500000])
t_uk = t_uk[t_uk[:,1]<=500000]
print('t_uk:',t_uk)
t_uk_comment = t_uk[:,-1]
t_uk_like = t_uk[:,1]
plt.figure(figsize=(20,8),dpi=80)
plt.scatter(t_uk_like,t_uk_comment)
plt.show()
最初的t_uk: [[7426393 782040 13548 705]
[ 494203 2651 1309 0]
[ 142819 13119 151 1141]
...
[ 109222 4840 35 212]
[ 626223 22962 532 1559]
[ 99228 1699 23 135]]
t_uk[:,1]<=500000: [False True True ... True True True]
t_uk[t_uk[:,1]<=500000]: [[ 494203 2651 1309 0]
[ 142819 13119 151 1141]
[1580028 65729 1529 3598]
...
[ 109222 4840 35 212]
[ 626223 22962 532 1559]
[ 99228 1699 23 135]]
t_uk: [[ 494203 2651 1309 0]
[ 142819 13119 151 1141]
[1580028 65729 1529 3598]
...
[ 109222 4840 35 212]
[ 626223 22962 532 1559]
[ 99228 1699 23 135]]
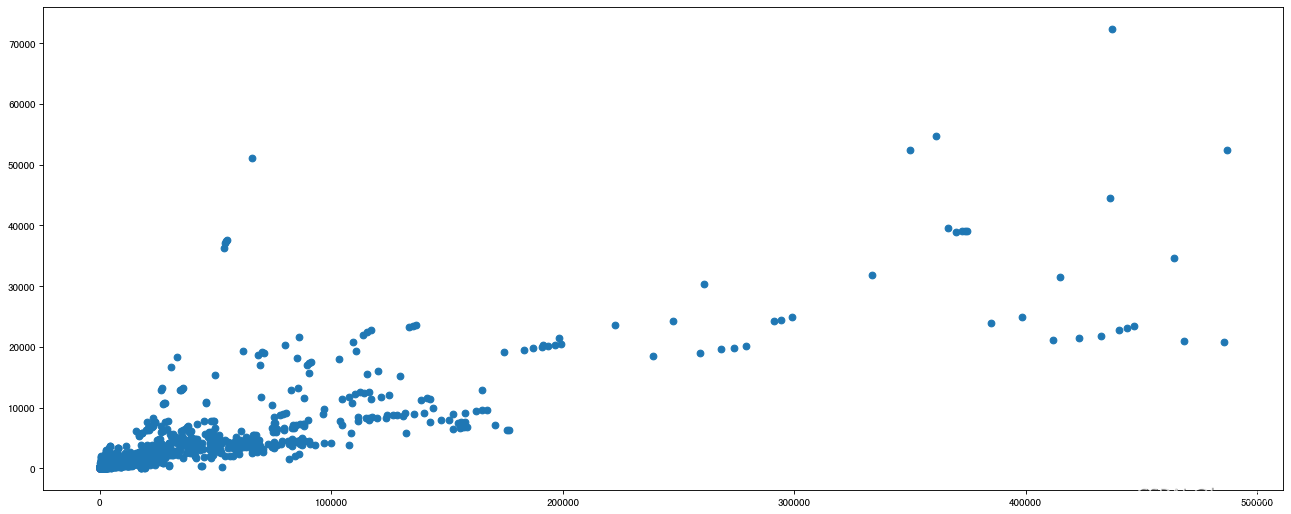
数据拼接
t33=np.arange(12).reshape(2,6)
t44=np.arange(12,24).reshape(2,6)
print('t33:\n',t33,'\n\n','t44:\n',t44)
t33:
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]]
t44:
[[12 13 14 15 16 17]
[18 19 20 21 22 23]]
np.vstack((t33,t44))
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
np.hstack((t33,t44))
array([[ 0, 1, 2, 3, 4, 5, 12, 13, 14, 15, 16, 17],
[ 6, 7, 8, 9, 10, 11, 18, 19, 20, 21, 22, 23]])
t
array([[ 1, 1, 1, 1, 1, 1],
[ 16, 13, 15, 12, 14, 17],
[ 1, 1, 1, 1, 1, 1],
[9999, 19, 9999, 18, 20, 9999]])
t[[1,2],:]=t[[2,1],:]
t
array([[ 1, 1, 1, 1, 1, 1],
[ 1, 1, 1, 1, 1, 1],
[ 16, 13, 15, 12, 14, 17],
[9999, 19, 9999, 18, 20, 9999]])
t[:,[0,4]]=t[:,[4,0]]
t
array([[ 1, 1, 1, 1, 1, 1],
[ 1, 1, 1, 1, 1, 1],
[ 14, 13, 15, 12, 16, 17],
[ 20, 19, 9999, 18, 9999, 9999]])
np.argmax(t)
20
np.argmax(t,axis=0)
array([3, 3, 3, 3, 3, 3])
np.argmax(t,axis=1)
array([0, 0, 5, 2])
np.argmin(t,axis=1)
array([0, 0, 3, 3])
np.zeros((3,4))
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
np.ones((3,4))
array([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
np.eye(3)
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
np.random.rand(2,3,2)
array([[[0.35950567, 0.08177032],
[0.89808166, 0.73285583],
[0.23462587, 0.46792952]],
[[0.02080821, 0.55948812],
[0.25205097, 0.75559711],
[0.93791326, 0.24709769]]])























 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









