







 本文通过线性回归模型预测小红书用户的销售额,分析了包括用户年龄、性别、购买历史等指标,并针对数据的缺失值进行了处理。尽管模型解释力度有限,但在累计购买金额上发现了与销售额的正相关关系。
本文通过线性回归模型预测小红书用户的销售额,分析了包括用户年龄、性别、购买历史等指标,并针对数据的缺失值进行了处理。尽管模型解释力度有限,但在累计购买金额上发现了与销售额的正相关关系。
数据:
数据链接
提取码: j4cd
仅作为个人数据分析成长之路记录
1.指标解释
revenue :用户的下单购买金额
3rd_party_stores: 用户过往在app中从第三方商家购买的数量,0表示购买的自营产品
gender:男1 女0 空缺unkown
age :年龄 空缺unkown
engaged_last_30:最近30天在app上有参与重点活动
lifecycle :生命周期A:注册6个月内
B:一年内
C:两年内
days_since_last_order 最近一次下单距今的天数(小于1表示当天有下单)
previous_order_amount 累计的用户购买金额
2.数据概述
2.1 前期准备工作——导入数据和相关包
import pandas as pd #导入pandas
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
from statsmodels.formula.api import ols #导入经典线性模型包
from sklearn.linear_model import LinearRegression
#导入文件
red=pd.read_csv('week2.redbook.csv')
2.2 数据描述
red.info()
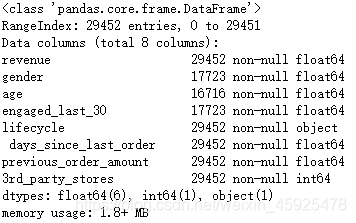
结果显示共有29452行数据,其中gender、age、engaged_last_30三列有缺失值,需要对其进行数据处理
或者用下列代码统计缺失值个数
red.isnull().sum()

离散程度描述
red.describe()
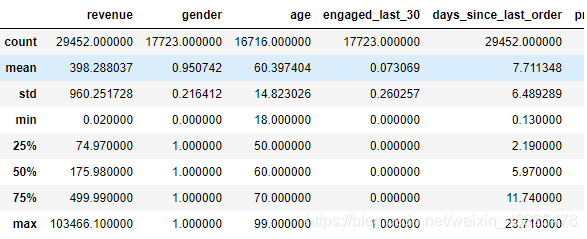
性别一列竟然有75%的消费用户是男性,age一列中年龄最大的有99
2.3 缺失值处理
对于连续变量,可以用均值、中位数或者根据其他数据模型填充;
对于类别变量,则可以把变量拆解为哑变量,再删除重复或没有意义的变量
将age选择按中位数填充
将性别的缺失值先标记为unknown,再变为哑变量
将engaged缺失值替换为unknown,再变为哑变量
red['age']=red['age'].fillna(red['age'].median())#将age 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1002
1002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









