






变形金刚代理是一个实验性的 API,随时可能发生变化。代理返回的结果可能会随着 API 或底层模型的变化而变化。
变形金刚版本 v4.29.0,建立在和探员的工具概念上。你可以在里面this colab玩。
简而言之,它在 Transformers 之上提供了一个自然语言 API:我们定义了一组精选工具,并设计了一个代理来解释自然语言并使用这些工具。它在设计上是可扩展的;我们策划了一些相关工具,但我们将向你展示如何轻松扩展该系统以使用社区开发的任何工具。
让我们从几个例子开始,看看这个新的 API 可以实现什么。当涉及到多模式任务时,它的功能特别强大,所以让我们用它来生成图像并大声朗读文本。
agent.run(“为下面的图像添加标题”,image=image)
| Input | 输出 |
|---|---|
 | A beaver is swimming in the water |
agent.run(“大声朗读以下文本”,text=text)
| Input | 输出 |
|---|---|
| 一只海狸在水里游泳 | |
| 你的浏览器不支持音频元素。 |
|
代理.运行(
“In the following `document`, where will the TRRF Scientific Advisory Council Meeting take place?”, document=document,
)
| Input | 输出 |
|---|---|
 | ballroom foyer |
快速启动
在能够使用 agent.run 之前,你需要实例化一个代理,它是一个大型语言模型(LLM)。我们为 OpenAI 模型以及 BigCode 和 OpenAssistant 的开源替代方案提供支持。OpenAI 模型性能更好(但需要你拥有 OpenAI API 密钥,因此不能免费使用);Hugging Face 为 BigCode 和 OpenAssistant 模型提供对端点的免费访问。
首先,请安装 agents Extras 以安装所有默认依赖项。
PIP 安装转换器 [代理 ]
要使用 OpenAI 模型,请在安装 openai 依赖项OpenaiAgent后实例化:
从 Transformers 导入 OpenAIagent
代理 =OpenAIAgent(模型 =“Text-Davinci-003 ”,API_ 关键字 =“<your_api_key>”)
要使用 BigCode 或 OpenAssistant,首先登录以访问推理 API:
从 HuggingFace_ 中心导入登录
登录(“<YOUR_TOKEN>”)
然后,实例化代理
从变压器导入 HFAgent
#StarCoder agent=hfagent(“https://api-inference.huggingface.co/models/bigcode/starcoder ”)#StarCoderBase#agent=hfagent(“https://api-inference.huggingface.co/models/bigcode/starcoderbase ”)#OpenAssistant#agent=HFagent(URL_endpoint=“https://api-inference.huggingface.co/models/openassistant/oasst-sft-4-pythia-12b-epoch-3.5 ”)
这使用的是拥抱脸目前免费提供的推理 API.如果你对此模型(或另一个模型)有自己的推理端点,则可以将上面的 URL 替换为你的 URL 端点。
StarCoder 和 OpenAssistant 可以免费使用,并且在简单的任务上表现得非常出色。但是,在处理更复杂的提示时,检查点不起作用。如果你正面临这样的问题,我们建议你尝试 OpenAI 模型,虽然它不是开源的,但在这个特定的时间表现更好。
你现在可以走了!让我们深入了解一下你现在可以使用的两个 API.
单次执行(运行)
单一执行方法是在使用run()代理的方法时:
agent.run(“给我画一幅河流和湖泊的图画。”)

它会自动选择适合你要执行的任务的工具(或多个工具),并适当地运行它们。它可以在同一指令中执行一个或多个任务(尽管指令越复杂,代理失败的可能性就越大)。
agent.run(“给我画一张海的图片,然后转换图片以添加一个岛屿”)

每个run()操作都是独立的,因此你可以使用不同的任务连续运行几次。
请注意,你的 agent 只是一个大型语言模型,因此提示符中的微小变化可能会产生完全不同的结果。尽可能清楚地解释你要执行的任务是很重要的。我们更深入地研究如何写出好的提示语here。
如果你希望在执行过程中保持状态或将非文本对象传递给代理,则可以通过指定希望代理使用的变量来实现。例如,你可以生成河流与湖泊的第一个图像,并要求模型通过执行以下操作来更新该图片以添加岛屿:
Picture=agent.run(“生成河流和湖泊的图片。”)已更新 _Picture=agent.run(“转换中 picture\ 的图像,以向其中添加岛屿。”,PICTURE=picture)
当模型无法理解你的请求并混合工具时,这会很有帮助。一个例子是:
agent.run(“给我画一只在海里游泳的水豚”)
在这里,模型可以用两种方式解释:
- 让他们
text-to-image生成一只在海里游泳的水豚。 - 或者,
text-to-image生成水豚,然后使用image-transformation工具让它在海里游泳
如果你想强制执行第一个场景,可以将提示符作为参数传递给它:
agent.run(“给我画一幅画 prompt\”,prompt=“一只在海里游泳的水豚”)
基于聊天的执行(Chat)
代理还具有基于聊天的方法,使用以下chat()方法:
agent.chat(“生成江湖图”)
agent.chat(“转换图片,使其中有一块石头”)

当你想要跨指令保持状态时,这是一种有趣的方法。它更适合实验,但往往更适合单个指令,而不是复杂指令(该run()方法更适合处理复杂指令)。
如果你希望传递非文本类型或特定提示,此方法还可以接受参数。
远程执行
出于演示目的,并且为了使它可以用于所有设置,我们为代理可以访问的几个默认工具创建了远程执行器。这些是使用推理端点创建的。要了解如何自己设置远程执行器工具,我们建议你阅读自定义工具指南。
要使用远程工具运行,只需将指定 remote=True 为run()或chat()即可。
例如,以下命令可以在任何设备上高效运行,而不需要大量的 RAM 或 GPU:
agent.run(“给我画一幅江湖图”,remote=true)
这同样适用于chat():
agent.chat(“给我画一幅江湖图”,remote=true)
这里发生了什么事?什么是工具,什么是代理?
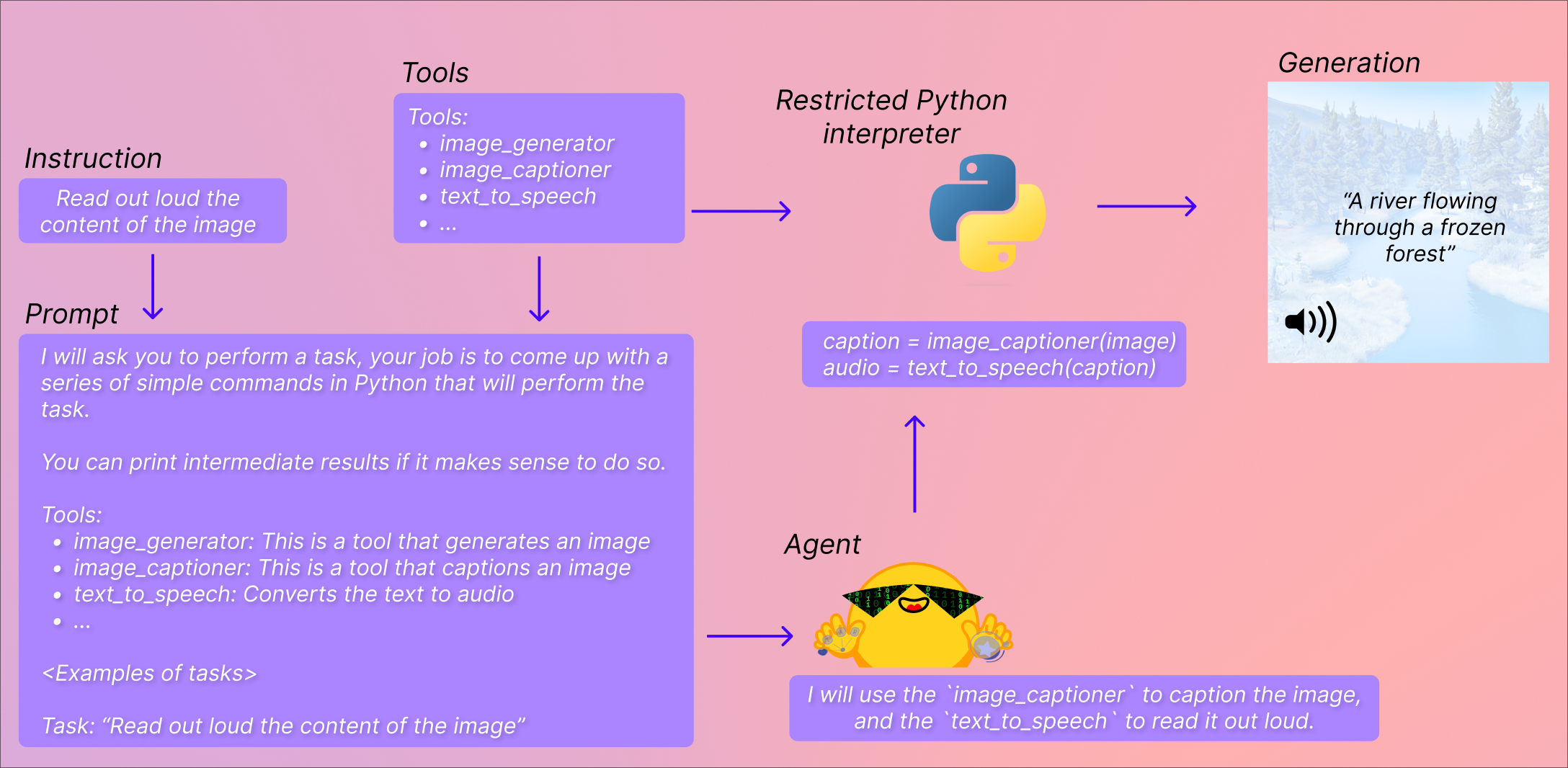
探员
这里的“代理”是一个大型语言模型,我们正在提示它,以便它可以访问一组特定的工具。
LLM 非常擅长生成小的代码样本,因此该 API 通过提示 LLM 给出使用一组工具执行任务的小代码样本来利用这一点。然后,此提示将由你为代理提供的任务和你为其提供的工具的描述来完成。通过这种方式,它可以访问你正在使用的工具的文档,特别是它们的预期输入和输出,并可以生成相关代码。
工具。
工具非常简单:它们只是一个函数,只有一个名称和一个描述。然后,我们使用这些工具的描述来提示代理。通过提示,我们向代理展示了它如何利用工具来执行查询中所请求的内容。
这是使用全新的工具,而不是管道,因为代理使用非常原子化的工具编写更好的代码。管道的重构程度更高,通常将多个任务组合在一起。工具应该只专注于一个非常简单的任务。
代码执行?!
然后,使用我们的小型 Python 解释器对与你的工具一起传递的输入集执行此代码。我们听到你在后面大喊“任意代码执行!”,但让我们解释一下为什么不是这样。
唯一可以调用的函数是你提供的工具和打印函数,因此你可以执行的内容已经受到限制。如果仅限于抱脸工具,你应该是安全的。
然后,我们不允许任何属性查找或导入(无论如何都不需要将输入/输出传递给一小组函数),因此所有最明显的攻击(并且你无论如何都需要提示 LLM 输出它们)都不应该成为问题。如果你希望非常安全,可以使用附加参数 return_code=true 来执行 run()方法,在这种情况下,代理将只返回要执行的代码,你可以决定是否这样做。
执行将在尝试执行非法操作的任何行停止,或者如果代理生成的代码存在常规 Python 错误,则执行将停止。
一套精选的工具
我们确定了一套工具,可以增强这些代理的能力。以下是我们已集成 transformers 的工具的更新列表:
- 文档问题回答:给定一个图像格式的文档(如 PDF),回答有关此文档的问题(Donut)
- 文字问答:给定一篇长文和一个问题,回答文中的问题(Flan-T5)
- 无条件图像字幕:为图像添加标题!()BLIP
- 图像问答:给定一个图像,回答有关此图像的问题(VILT)
- 图像分割:给定图像和提示符,输出该提示符的分割掩码(CLIPSeg)
- 语音到文本:给定一个人说话的音频记录,将语音转录为文本(Whisper)
- 文本到语音转换:将文本转换为语音(SpeechT5)
- 零拍摄文本分类:给定文本和标签列表,确定文本最对应于哪个标签(BART)
- 文本摘要:用一句或几句话概括一篇长文章(BART)
- 翻译:将文本翻译成指定语言(NLLB)
这些工具集成在变压器中,也可以手动使用,例如:
从变压器导入加载 _ 工具
工具 = 加载 _ 工具(“文本到语音转换”)音频 = 工具(“这是一个文本到语音转换工具”)
自定义工具
虽然我们确定了一套精选的工具,但我们坚信该实现提供的主要价值是快速创建和共享自定义工具的能力。
通过将工具的代码推送到拥挤面空间或模型库,你可以直接使用代理来利用该工具。我们已将一些变压器-不可知论者工具添加到 [ huggingface-tools 组织](https://huggingface.co/huggingface-tools)中:
- 文本下载器:从 Web URL 下载文本
- 文本到图像:根据提示生成图像,利用稳定扩散
- 图像变换:在给定初始图像和提示的情况下,利用指令 PIX2PIX 稳定扩散修改图像
- 文本到视频:根据提示生成小视频,利用 Damo-VILAB
我们从一开始就使用的文本到图像转换工具是一个远程工具*HuggingFace 工具/文本到图像 *。我们将继续在这个组织和其他组织上发布这样的工具,以进一步增强这种实现。
默认情况下,代理可以访问 [ huggingface-tools](https://huggingface.co/huggingface-tools)上的工具。我们将向你介绍如何编写和共享你的工具,以及如何利用中遵循指南的 Hub 上驻留的任何自定义工具。
代码生成
到目前为止,我们已经展示了如何使用代理为你执行操作。但是,代理只生成代码,然后我们使用非常受限制的 Python 解释器执行这些代码。如果你希望使用在不同设置中生成的代码,可以提示代理返回代码,以及工具定义和准确的导入。
例如,以下指令
agent.run(“给我画一幅河湖图”,return_code=true)
返回以下代码
从变压器导入加载 _ 工具
图像 _ 生成器 = 加载 _ 工具(“Huggingface-tools/text-to-image ”)
Image= 图像 _ 生成器(Prompt=“Rivers and Lakes ”)
理返回代码,以及工具定义和准确的导入。
例如,以下指令
agent.run(“给我画一幅河湖图”,return_code=true)
返回以下代码
从变压器导入加载 _ 工具
图像 _ 生成器 = 加载 _ 工具(“Huggingface-tools/text-to-image ”)
Image= 图像 _ 生成器(Prompt=“Rivers and Lakes ”)
然后你可以自己修改和执行。
-- 编码:UTF-8--
“”"变形金刚无所不能。
由实验室自动生成。
原始文件位于
https://colab.research.google.com/drive/1c7MHD-T1forUPGcC_jlwsIptOzpG3hSj
变形金刚无所不能
Transformers 版本 V4.29 引入了一个新的 API:和探员的 API工具
它在 Transformers 上提供了一个自然语言 API:我们定义了一套精选工具,并设计了一个代理来解释自然语言并使用这些工具。它在设计上是可扩展的;我们策划了一些相关工具,但我们将向你展示如何轻松扩展该系统以使用任何工具。
让我们从几个例子开始,看看这个新的 API 可以实现什么。当涉及到多模式任务时,它的功能特别强大,所以让我们用它来生成图像并大声朗读文本。
#@title 设置转换器 _version=“v4.29.0 ”#@param[“main ”,“v4.29.0 ”]{allow-input:true}
打印(f “使用变形金刚版本设置所有内容 {变形金刚 _ 版本}”)
!pip 安装 HuggingFace_Hub>=0.14.1 Git+https://github.com/huggingface/transformers@$Transformers_ 版本-Q 扩散器加速数据集 Torch SoundFile SentencePiece OpenCV-Python OpenAI
导入 IPython 将声音文件导入为 SF
def 播放 _ 音频(音频):
sf.write(“speech_converted.wav”, audio.numpy(), samplerate=16000) return IPython.display.Audio(“speech_converted.wav”)
从 HuggingFace_HUB 导入笔记本 _ 登录笔记本 _ 登录()
“”"# 用变形金刚做任何事
我们将从实例化开始代理人,这是一个大型语言模型(LLM)。
我们建议使用 OpenAI 以获得最佳效果,但也可以使用完全开源的模型,如 StarCoder 或 OpenAssistant.
“”"
#@title 代理初始化代理 _ 名称 =“OpenAI(API 密钥)”#@param[“StarCoder(HF 令牌)”,“OpenAssistant(HF 令牌)”,“OpenAI(API 密钥)”]
导入 GetPass
如果代理 _ 名称 ==“StarCoder(HF 令牌)”:
from transformers.tools import HfAgent agent = HfAgent(“https://api-inference.huggingface.co/models/bigcode/starcoder”) print(“StarCoder is initialized 💪”)
elif 代理 _ 名称 ==“OpenAssistant(HF 令牌)”:
from transformers.tools import HfAgent agent = HfAgent(url_endpoint=“https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5”) print(“OpenAssistant is initialized 💪”)
如果代理 _ 名称 ==“OpenAI(API 密钥)”:
from transformers.tools import OpenAiAgent pswd = getpass.getpass(‘OpenAI API key:’) agent = OpenAiAgent(model=“text-davinci-003”, api_key=pswd) print(“OpenAI is initialized 💪”)
“”"## 使用代理
代理已初始化!我们现在可以获得它所能获得的工具的全部力量。
让我们使用它
“”"
boat=agent.run(“生成船和狗在水中的图像”)boat
“”“如果你想将对象(或以前的结果!)传递给代理,你可以通过直接传递一个变量,并在反引号之间提及所传递的变量的名称来实现。例如,如果我想重新使用以前的船代:“””
caption=agent.run(“Can you caption the boat_image?”,boat_image=boat)caption
“”“代理人的能力和他们同时处理几个指令的能力各不相同;然而,它们中最强大的(如 OpenAI)能够处理复杂的指令,如以下三部分指令:“””
audio=agent.run(可以生成船的图像吗?请稍后大声读出图像内容)播放 _ 音频(Audio)
“”"当你的查询暗示使用你没有直接描述的工具时,这是非常有效的。这方面的一个例子是下面的问题:“大声朗读 HF.Co 的摘要”
在这里,我们要求模型同时执行三个步骤:
- 获取网站https://huggingface.co
- 总结一下
- 将文本翻译成语音
“”"
AUDIO=agent.run(朗读播放 _ 音频(AUDIO)的http://hf.co") 摘要
“”"使用最好的代理效果很好
聊天模式
到目前为止,我们一直在使用它的 .run 命令来使用代理。但这并不是它可以访问的唯一命令。它可以访问的第二个命令是 .chat,它允许在聊天模式中使用它。
两者之间的区别是相对于它们的记忆而言的:
.run不会跨运行保留内存,但对于一次多个操作(例如从给定指令连续运行两个或三个工具),执行效果更好。- 跨运行
.chat保持内存,但在单个指令上执行得更好。
让我们在聊天模式中使用它!
“”"
agent.chat(“给我看一张狗和水豚的图片”)
“”“如果我们想改变图像中的某些内容,该怎么办?例如,将水豚移动到多雪的环境“””
agent.chat(“变换图像使其下雪”)
“”“现在,如果我们想把水豚移走,换成别的东西呢?我们可以要求它向我们展示图像中水豚的面具:“””
agent.chat(“给我看看雪豚的面具”)
“”“可以访问过去的历史记录,以便在给定的提示上重复迭代。然而,它有它的局限性,有时你想有一个干净的历史。为此,可以使用以下方法:“””
代理。准备 _ 的 _ 新 _ 聊天()
“”"## 工具
到目前为止,我们一直在使用代理可以访问的工具。这些工具如下:
- 文档问题回答:给定图像格式的文档(如 PDF),回答有关此文档的问题(圆环)
- 文字问答:给定一篇长文章和一个问题,回答文章中的问题(FLAN-T5)
- 无条件图像字幕:为图像添加标题!(信号)
- 图像问答:给定图像,回答有关此图像的问题(VILT)
- 图像分割:给定图像和提示符,输出该提示符的分割掩码(clipseG)
- 语音到文本:给出一个人讲话的音频记录,将讲话转录成文本(耳语)
- 文本到语音转换:将文本转换为语音(speech 5)
- 零拍摄文本分类:给定文本和标签列表,确定文本最对应的标签(Bart)
- 文本摘要:用一句或几句话总结一篇长文章(巴特)
- 翻译:将文本翻译成给定语言(NLLB)
我们还支持以下基于社区的工具:
- 文本下载器:从 Web URL 下载文本
- 文本到图像:根据提示生成图像,利用稳定扩散
- 图像变换:变换图像
因此,我们可以通过用自然语言解释我们想要做的事情来混合和匹配不同的工具。
但是如何添加新工具呢?让我们来看看如何做到这一点
添加新工具
我们将添加一个非常简单的工具,以便演示保持简单:我们将使用 Awesome Cataas(cat-as-a-Service)API 在每次运行时获取随机的 cat.
我们可以用下面的代码得到一只随机的猫:
“”"
从 PIL 导入映像导入请求
image=image.open(requests.get(https://cataas.com/cat’,stream=true).raw)image
“”"让我们创建一个可以被我们的系统使用的工具!
所有工具都依赖于包含必要的主要属性的超类工具。我们将创建一个继承自它的类:
“”"
从变压器导入工具
类 catimagefetcher(工具):
pass
“”"这个类有几个需求:
- 属性名称,与工具本身的名称相对应。为了与其他具有执行名称的工具保持一致,我们将其命名为 text-download-counter.
- 属性描述,将用于填充代理的提示。
- 输入和输出属性。对此进行定义将有助于 Python 解释器对类型做出有根据的选择,并允许在我们将工具推送到中心时生成 Gradio-Demo.它们都是期望值的列表,可以是文本、图像或音频。
- 包含推理代码的__电话__方法。这是我们在上面玩过的代码!
这是我们班现在的样子:
“”"
从 Transformers 导入工具从 HuggingFace_ 中心导入列表 _ 模型
类 catimagefetcher(工具):
name = “cat_fetcher” description = (“This is a tool that fetches an actual image of a cat online. It takes no input, and returns the image of a cat.”)
inputs = [] outputs = ["text"]
def __call__(self):
return Image.open(requests.get('https://cataas.com/cat', stream=True).raw).resize((256, 256))
“”“我们可以直接使用和测试该工具:”“”
工具 =catimagefetcher()工具()
“”为了将工具传递给代理,我们建议直接使用工具实例化代理:“”
从 Transformers.Tools 导入 HFAgent
agent=hfagent(“https://api-inference.huggingface.co/models/bigcode/starcoder ”,其他 _ 工具 =[工具] )
“”“让我们尝试让代理将其与其他工具一起使用!”“”
agent.run(“在线获取一只猫的图像并为其添加标题”)
“”"成功
该工具用于获取 CAT 图像,不久后使用图像字幕工具为同一图像添加字幕。
最后,我们建议将该工具推向中心,以便让其他人从中受益。下面是包含更多信息的文档,以便执行此操作:添加新工具
感谢你使用笔记本电脑!我们期待着你将推动的工具,这将有助于增强所有代理商的能力。
“”"


















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









