







上一篇博客中讲述了怎样用数学来定义或者计算神经网络的假设函数。
现在来学习一下如何高效进行计算和向量化的实现方法。更重要的是,搞明白为什么这样是表示神经网络的好的方法,并且明白它们如何帮助我们学习复杂的非线性假设函数。
以这个神经网络为例:
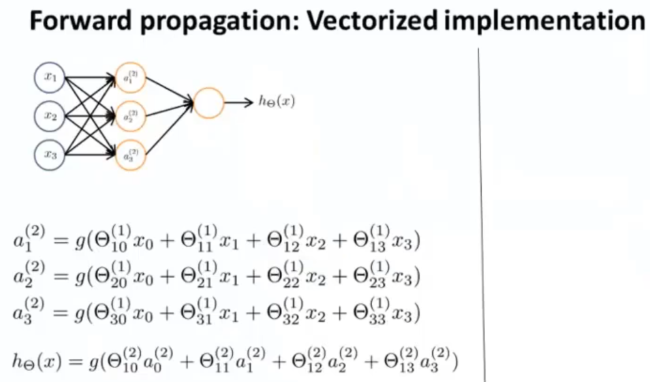
计算出假设输出的步骤是上边的这些方程,通过这些方程,我们计算出三个隐藏单元的激活值,然后利用这些值来计算最终输出,假设函数 h ( x ) h(x) h(x) 。
接下来,定义一些额外的项:
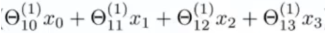
定义为
z
1
(
2
)
z^{(2)}_1
z1(2) ,这样一来就有:
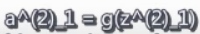
以此类推……
(上标2表示第2层)
这些 z z z 值都是线性组合某个特定的神经元的输入值 x 0 x_0 x0、 x 1 x_1 x1、 x 2 x_2 x2、 x 3 x_3 x3 的加权线性组合。
现在,看一下这堆数字:
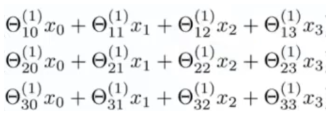
注意到该数字块对应了矩阵向量乘法
θ
(
1
)
θ^{(1)}
θ(1) 乘以向量
x
x
x。根据这一点,能将神经网络的计算向量化。
具体而言,我们将特征向量
x
x
x、
z
(
2
)
z^{(2)}
z(2) 分别定义为:


接着我们向量化
a
1
(
2
)
a^{(2)}_1
a1(2)、
a
2
(
2
)
a^{(2)}_2
a2(2)、
a
3
(
2
)
a^{(2)}_3
a3(2) 的计算,只用两个步骤:
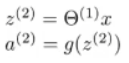
为了让我们的符号和接下来的工作相一致,在输入层,有输入 x x x,但我们还可以把这些想成是第一层的激活项。
如果定义
a
(
1
)
a^{(1)}
a(1) 等于
x
x
x,
a
(
1
)
a^{(1)}
a(1) 就是一个向量了,就可以通过把
a
(
1
)
a^{(1)}
a(1) 定义为输入层的激活项,就可以把这里的
x
x
x 替换掉:
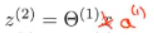
就目前所写的,能计算出
a
1
a_1
a1、
a
2
a_2
a2、
a
3
a_3
a3(上标为2)的值,但还需要一个值
a
0
(
2
)
a^{(2)}_0
a0(2) 才能得到输出单元,它是隐藏层的偏置单元,当然,第一层也有一个偏置单元。额外加上一个
a
0
(
2
)
=
1
a^{(2)}_0=1
a0(2)=1,故
a
(
2
)
a^{(2)}
a(2) 就是一个四维的特征向量。
最后,要计算假设函数的实际输出值,只需要计算
z
(
3
)
z^{(3)}
z(3):
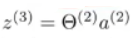

最终,假设函数输出
h
(
x
)
h(x)
h(x):
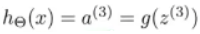
a
(
3
)
a^{(3)}
a(3)是输出层的唯一单元,它是一个实数,可以写成
a
(
3
)
a^{(3)}
a(3) 或
a
1
(
3
)
a^{(3)}_1
a1(3)。
这个计算
h
(
x
)
h(x)
h(x) 的过程也称为前向传播,这样命名是因为,我们从输入单元的激活项开始,然后进行前
向传播给隐藏层,计算隐藏层的激活项
a
(
2
)
=
g
(
z
(
2
)
)
a^{(2)}=g(z^{(2)})
a(2)=g(z(2)),然后继续前向传播,并计算输出层的激活项
a
(
3
)
=
g
(
z
(
3
)
)
a^{(3)}=g( z^{(3)} )
a(3)=g(z(3))。
这个依次计算激活项,从输入层到隐藏层再到输出层的过程叫前向传播。
我们刚刚推导出的是这一过程的向量化实现方法,如果你用那些公式来实现这一过程,你会得到一个相对有效的计算 h ( x ) h(x) h(x) 的方法。
这种前向传播的方法也可以帮助我们了解神经网络的作用和它为什么能够帮助我们学习非线性假设函数。
看一下这个神经网络:

暂时盖住图片的左边部分:

如果观察图中剩下的部分,看起来很像逻辑回归,也就是用图中最后一个节点(逻辑回归单元)来预测 h ( x ) h(x) h(x) 的值。
具体来说,假设函数的输出为:
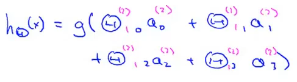
如果只观察符号中蓝色的部分,看起来非常像标准的逻辑回归模型,不同之处在于现在用的是大写的
Θ
Θ
Θ 而不是小写的
θ
θ
θ。
这实际上就是逻辑回归,但输入逻辑回归的特征是通过隐藏层计算的数值。 但是它不是使用原本的 x 1 x_1 x1、 x 2 x_2 x2、 x 3 x_3 x3 作为特征,而是用 a 1 a_1 a1、 a 2 a_2 a2、 a 3 a_3 a3(上标(2))作为新的特征。
有趣的是特征项 a 1 a_1 a1、 a 2 a_2 a2、 a 3 a_3 a3,它们是学习得到的函数输入值。具体来说,就是从第一层映射到第二层的函数,这个函数由其他参数 Θ ( 1 ) Θ^{(1)} Θ(1) 决定。
在神经网络中,它没有用输入特征 x 1 x_1 x1、 x 2 x_2 x2、 x 3 x_3 x3 来训练逻辑回归,而是自己训练逻辑回归的输入 a 1 a_1 a1、 a 2 a_2 a2、 a 3 a_3 a3。
可以想象,根据为 Θ 1 Θ_1 Θ1 选择的不同参数,有时可以学习到一些很有趣和复杂的特征,就可以得到一个更好的假设函数,比使用原始输入 x 1 x_1 x1、 x 2 x_2 x2、 x 3 x_3 x3 时得到的假设更好。
也可以选择多项式项作为输入项,但这个算法可以灵活地尝试快速学习任意的特征项,把 a 1 a_1 a1、 a 2 a_2 a2、 a 3 a_3 a3 输入最后的单元,这部分实际上是逻辑回归算法。
现在描述的这个例子比较高级,有点难理解这个具有更复杂特征项的神经网络。后面会讲解一个具体的例子,来说明神经网络如何利用隐藏层计算更复杂的特征,并输入到最后的输出层,以及为什么这样就可以学习更复杂的假设函数。这可以使我们更加理解神经网络。
还可以用其他类型的图来表示神经网络,神经网络中神经元的连接方式称为神经网络的架构。架构是指不同的神经元的连接方式。
这里有一个例子,包括了不同的神经网络架构:

在第二层有三个隐藏单元,它们会计算一些比如说输入层的复杂功能,然后第三层可以将第二层训练出的特征项作为输入,然后在第三层计算出更复杂的特征。这样,在你到达输出层时,就可以利用在第三层训练出的更复杂的特征作为输入,以此得到非常有趣的非线性假设函数。
前向传播在神经网络里的工作原理:从输入层的激活项开始前向传播到第一隐藏层,然后传播到第二隐藏层,最终到达输出层。
知道如何向量化那些计算。
某些层是如何计算前面层的复杂特征项这一点有点抽象。
后面会讨论具体的例子,描述怎样用神经网络来计算输入的非线性函数,以便更好地理解从神经网络中得到的复杂的非线性假设函数。
参考资料:吴恩达机器学习系列课程















 572
572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









