








基于IF-MMIN改进的->IF-MMIN
代码地址->github传送
abstract
多模态情感识别(MER)旨在通过探索跨模态的互补信息来理解人类表达情感的方式。然而,很难保证全模态数据在真实场景中总是可用的。为了处理缺失模态,研究人员着重研究了跨模态缺失模态想象过程中有意义的联合多模态表征学习。然而,由于“模态差距”问题,跨模态想象机制极易产生误差,从而影响想象的准确性,从而影响最终的识别性能。为此,我们将模态不变特征的概念引入到缺失模态想象网络中,该网络包含两个关键模块:1)基于对比学习的新型模态不变特征提取模块;2)基于想象不变量特征的鲁棒想象模块,在缺失条件下重构缺失信息。最后,我们结合想象和可用的模式的情绪识别。在基准数据集上的实验结果表明,我们提出的方法优于现有的最先进的策略。与我们之前的工作相比,我们的扩展版本在缺失模态的多模态情感识别上更有效。
intro
多模态情绪识别(MULTIMODAL emotion recognition, MER)任务旨在利用多模态信号的互补信息来理解人类的情绪表达[1],[2],[3]。随着深度学习和情感计算的发展[4],[5],已有的研究已经对全模态数据进行了出色的情感理解能力[6],[7],[8]。然而,在现实场景中,它们经常面临设备损坏[9]、[10]、模态信息不同步[11]、视频质量差[12]等导致模态缺失的问题。现有的MER系统通常不能在缺失条件下表现良好。为此,越来越多的研究者开始关注缺失模态的多模态情绪识别[10]、[13]、[14]、[15]、[16]、[17]、[18]、[19]、[20]、[21]、[22]。
目前,主流方法的思想主要是利用现有可用模态重构缺失数据,并捕获多模态联合特征表示,用于最终的情感识别[13],[14]。
例如,Pham等人[20]提出了一种基于循环翻译的模型来学习鲁棒联合表示。此外,研究了基于级联残差自编码器(cascading Residual Autoencoder, CRA)的缺失模态想象网络[10],简称MMIN,通过CRA预测缺失模态并学习联合特征表示,取得了优于现有方法的性能。值得一提的是,这种方法的关键组成部分是跨模态想象,它对其鲁棒性起着重要作用。
尽管取得了进展,但多模态机器学习领域中众所周知的“模态差距”问题[23]对跨模态想象的性能产生了不利影响。
具体来说,情态差异是指情态有其独特的特征。请注意,异质模态之间存在天然差异,表现为各种模态的特征分布不同,在特征几何空间中会明显分开[23]。在全情态情境下,一些研究试图挖掘不同情态之间的内在关联,以缓解“情态鸿沟”问题[24],[25],[26]。例如,Hazarika等人[24]试图学习不同模态的共享子空间特征表示,用于增强单模态特征的信息。Liu等[27]提出了离散共享空间来捕获细粒度表示,以提高跨模态检索的准确性。最近的一些研究[28]、[29]试图使用对比学习将来自多个模态的信息约束到一个统一的语义空间中。所有的研究都表明,利用情态相关知识可以有效地弥合情态差距。
在上述研究的鼓舞下,如何缓解这种模式缺失的MER模式差距问题,这在以往的工作中尚未得到研究。
幸运的是,我们可以从人类的认知计算理论中得到启发[30],[31]。如文献[30]所述,人类具有在他人引导下预测某一模态信息的能力。更重要的是,丰富的跨模态一致性使机器模仿人类的跨模态生成能力成为可能。因此,如何挖掘不同模态的跨模态一致性,即模态不变特征,并将其有效地应用于缺失模态,特别是缺失模态想象中的模态一致性,是本文研究的重点
在这项工作中,我们提出了一种新的基于对比学习的情态不变特征的缺失情态想象网络,称为CIF-MMIN。在这种情况下,基于对比学习的模态不变特征被称为CIF。
具体而言,我们首先设计了一种基于对比学习的训练策略,从全模态信息中提取CIF。然后,我们设计了基于CIF-MMIN的想象模块(CIF-IM),通过推断理想全模态的不变性,在缺失条件下推断出鲁棒缺失信息。注意,我们提出了一个不变性损失来约束CIF-MMIN中不变性特征的推理能力。最后,将想象的模态信息和可用的模态信息融合,以获得完成模态识别所需的完整信息。这样,我们充分探索了可用的模态,缓解了跨模态想象中的模态差距问题,从而提高了缺失条件下的MER的鲁棒性。
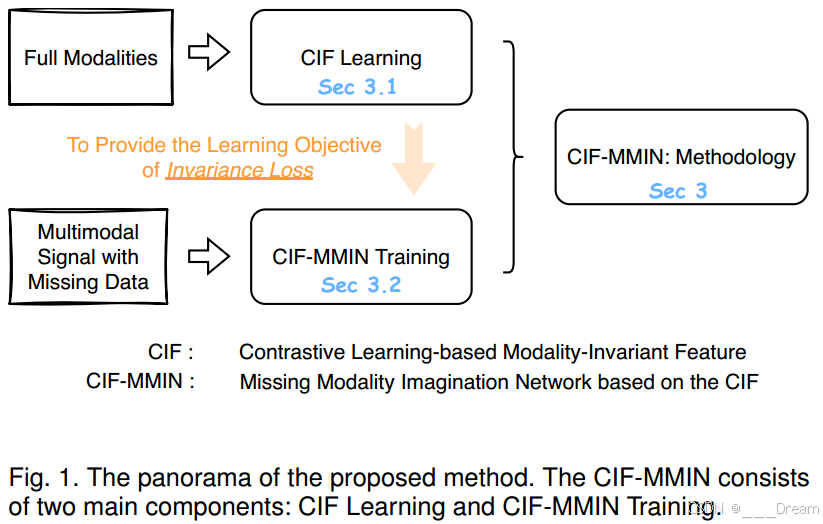
图1显示了所提出方法的全景图。我们可以看到,我们的方法,CIF- MMIN,包括两个主要部分:CIF学习和CIF- MMIN训练。CIF学习最初侧重于学习全模态场景中的模态不变性特征。CIF-MMIN训练进一步扩展了在模态缺失的情况下进行多模态情感识别的学习过程。CIF学习旨在为推断CIF- mmin训练中的不变性特征提供学习目标。
我们将在第3、3.1和3.2节中依次介绍这些方面。为了验证我们方法的有效性,我们在三个基准会话数据集上进行了实验。通过定量和定性分析,结果表明我们的CIF-MMIN方法在所有缺失模态条件下都优于最先进的基线模型。
本文的主要贡献可以概括如下:
•本工作专注于多模态情感识别,解决了缺失模态问题,显著增强了多模态情感识别在现实场景中的鲁棒性;
•我们受到人类强大的跨模态推理能力的启发,研究具有缺失模态的MER,这在以前的研究中尚未得到解决;
•我们设计了一个新的框架,CIF-MMIN,以实现对缺失数据的鲁棒跨模态想象。利用基于对比学习的模态不变特征有效地缓解了模态差距问题;
•在三个基准数据集上的实验结果验证了我们方法的有效性。在失模态条件下,CIF-MMIN优于现有的先进方法。
虽然这项工作与我们之前的工作[32]有相似的动机,称为IF-MMIN,在模态不变特征学习方面,它在许多方面是不同的:
1)我们使用基于对比学习的策略来取代之前的无监督中心矩差异(CMD)距离约束策略,因为无监督学习策略缺乏可解释性,学习的特征遭受语义损失[33];
2)在之前的工作中,在完成跨模态想象后,将CRA中的联合表示用于最终的MER,而将想象获得的单模态信息和缺失模态信息丢弃,导致信息浪费。因此,在本工作中,将想象中的缺失情态信息与原始的单模态信息融合,完成最终的MER,有效地利用了多模态信息。我们在第5.3.2.2节的消融研究中验证了这一点;
3)为了更全面地验证我们的模型,本文引入了更多的基准数据集和更多的基线系统,并进行了更详细的定性和定量分析,以进一步完善我们的工作
在本文的其余部分,我们首先简要回顾第2节的背景。第3节介绍了CIF-MMIN的方法。之后,我们在第4节中介绍了实验设置,其中包括数据集、基线和实现细节。我们在Section 5中展示了所有的实验结果并进行了深入的分析。最后,我们对本文进行了总结,并在第6节中讨论了未来的工作。
intro
多模态情绪识别
自动多模态情感识别对于自然人机交互非常重要[1],[2],[3],[34]。先前的研究表明,这些不同的模态对情绪表达是互补的,并提出了许多有效的多模态融合方法来提高情绪识别性能[6],[34],[35],[36],[37]。如Zhao等[34]提出基于变压器的深度融合网络(Deep-scale Fusion Network, TDFNet)模型,通过促进多模态信息之间的交互来增强情感特征的提取,从而提高情感识别的准确性。
Chen等人[37]提出了一种基于鲁棒优化的BERT方法(RoBERTa)[38]和Wav2vec[39]的key-sparse Transformer,通过更多地关注多模态特征中的情绪相关信息来实现高效的情绪识别。然而,现有的基于全模态样本训练的多模态融合模型在缺少部分模态的情况下往往会失败。因此,这就引入了一个重要的研究方向,即缺失模态的多模态情感识别,这正是本文的重点。
研究多模态情绪识别任务中的模态缺失问题具有重要的现实意义[10]、[13]、[22]、[40]、[41]。在现实场景中,某些模式(如面部表情、声音线索或文本转录)不可用或不可靠是很常见的[10]、[22]、[40]、[42]。这可能是由于各种原因造成的,比如设备故障、环境噪音或姿势限制。例如,在视频会议中,由于网络延迟或摄像头故障,可能无法获得面部表情数据。同样,在嘈杂的环境中,整个声音线索可能被环境噪声掩盖,使语音数据不可靠。与前面的场景类似,在噪声环境下,语音识别模型可能会产生错误的结果或无法准确识别文本信息。因此,在这种情况下,文本情态可能受到影响,无法提供精确的文本数据。这些问题在实际应用中非常普遍,解决缺失模式的挑战对于实现准确和稳健的情感识别系统至关重要[10],[13],[22]。
通过解决缺失模式的挑战,我们可以开发更强大和准确的情绪识别系统,可以有效地处理某些模式不存在或不可靠的情况[10],[13],[22],[41]。该研究可以在多个领域得到实际应用,包括人机交互[13]、情感计算[10]、[22]和情感感知技术[41],最终提高情感识别系统在现实环境中的性能和可用性。
缺失模态解决方案
现有的缺失模态的MER解决方案可以归纳为三类:1)缺失数据的输入;2)缺失数据重建;3)缺失条件下的联合表示学习。
缺失数据输入方法试图填充缺失信息,以便该信息可以与可用模态的信息组合以形成可计算的多模态表示。注意,用零向量或平均值填充缺失模态是最简单和最广泛使用的方法。如Parthasarathy等[15]用零向量填充视频缺失帧。Zhang等[16]基于同一类别的可用样本,用平均值填充缺失模态。一些进一步的方法[17]考虑了不同模态之间的相关性。
然而,验证通过上述方法获得的填充信息的可解释性仍然是一个挑战。
缺失数据重建研究的目的是预测或想象缺失数据的原始信息,从目前观察到的模式。请注意,想象的数据被馈送到后续模块,而观察到的模态被丢弃。为了实现这一目标,已经出现了几种神经网络模型,其中包括变压器[12],[43],生成对抗网络(GAN)[18],[44],自动编码器(AE)[45],[46]和变分自动编码器(VAE)[9],[47]等,并取得了令人鼓舞的结果。例如,Duan等人[48]利用自动编码器来输入缺失的数据。Tran等人[46]受残差学习[49]的启发,提出残差自编码器,设计了一种CRA架构来进行缺失数据重建。Cai等[18]提出了一种编码器-解码器网络,根据可用模态生成高质量的缺失模态图像。Suo等人[50]提出了一个由GAN和度量学习组成的框架来生成缺失模态信息[51]。
缺失条件下联合表征学习的目标是利用现有数据学习有意义的特征表征,模拟全模态条件下的多模态联合特征表征[19],[20],[21],[22]。Pham等[20]提出了一种基于循环一致性损失的翻译方法来学习联合表示。
我们注意到后两种方法之间的界限正变得越来越模糊,研究人员使用在缺失模态重建过程中学习到的联合表示来进行最终的情感识别。
例如,MMIN模型[10]将具有循环一致性损失的CRA纳入跨模态想象,然后提取CRA之间的联合特征表示,取得了优于现有方法的性能。
这种结合了联合表征学习和缺失模态重构的方法已经成为当今的主流方法。
人类情态间隙与跨情态推理
模态差距一直是困扰多模态学习的难题[23],这是由异构模态之间的载体差异造成的。与[23]的观察结果类似,不同的模态在隐藏特征空间中表现出不同的特征分布。具体来说,我们从交互式情绪二元运动捕捉(IEMOCAP)数据集[52]中随机选择400个样本进行t分布随机邻居嵌入(t-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1711
1711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









