






论文:Mitigating Inconsistencies in Multimodal Sentiment Analysis under Uncertain Missing Modalities - ACL Anthology https://aclanthology.org/2022.emnlp-main.189/
https://aclanthology.org/2022.emnlp-main.189/
Abstract:
针对多模态情感分析中的情态缺失问题,当情态缺失导致情感发生变化时,会出现不一致现象。决定整体语义的缺失情态可以被认为是关键的缺失情态。然而,以前的研究都忽略了不一致现象,简单地丢弃缺失的模态,或者仅仅从可用的模态中生成相关的特征。忽略关键的缺失情态格可能导致错误的语义结果。为了解决这个问题,我们提出了一个基于集成的缺失模态重构(EMMR)网络来检测和恢复关键缺失模态的语义特征。具体来说,我们首先通过主干编码器-解码器网络学习剩余模态的联合表示。然后,基于恢复的特征,我们检查语义一致性,以确定缺失的情态是否对整体情感极性至关重要。一旦由于关键模态缺失而导致的不一致问题存在,我们集成了几种编码器-解码器方法以更好地做出决策。在CMU-MOSI和IEMOCAP数据集上进行了大量的实验和分析,验证了该方法的优越性。
一.问题描述
1. 多模态情感分析(MSA)
-
含义: 多模态情感分析是指结合多种信息来源(如视觉、听觉和文本)来识别和分类情感的过程。这种方法比单一模态(如仅使用文本)更为有效,因为不同模态可以提供互补的信息。例如,语音的情感语调、面部表情和文本内容可以共同帮助更准确地理解说话者的情感状态。
2. 缺失模态的问题
-
含义: 在实际应用中,常常会遇到某种模态缺失的情况。例如,在视频情感分析中,可能会因为技术故障或环境噪声而缺失音频信息。缺失模态的问题会导致情感识别的准确性下降,因为模型无法获得完整的信息来做出判断。
3. 关键缺失模态的识别
-
含义: 关键缺失模态指的是在多模态情感分析中,某一模态的缺失对情感判断的影响尤为显著。本文强调,在处理缺失模态时,必须识别出哪些模态是关键的,从而采取相应的措施来弥补其缺失带来的信息损失。
4.多模态情感分析(MSA)中,不一致性问题
(1) 不一致性问题的定义
-
不一致性: 当模型在处理可用模态时,得出的情感判断与实际情感状态或其他模态的判断结果不相符时,就会出现不一致性。例如,如果视觉模态(如面部表情)显示出积极情感,而文本模态(如说出的话)传达出消极情感,这种情况下就会产生不一致。
-
(2)不一致性问题的原因
-
缺失模态: 在多模态情感分析中,某些模态可能会缺失(如缺少音频或视频),这会导致模型无法获取完整的信息,从而影响情感判断的准确性。
-
模态间的矛盾: 不同模态可能传递出相互矛盾的信息。例如,文本可能表达一种情感,而语音的语调或面部表情则表达另一种情感。这种模态间的矛盾会导致模型在情感分类时产生混淆。
(3)不一致性问题的影响
-
情感识别准确性下降: 不一致性会导致模型在情感分类时出现错误,降低整体的识别准确性。
-
决策不可靠: 在实际应用中,例如情感监测或客户反馈分析,不一致的情感判断可能会导致错误的决策,从而影响用户体验或业务策略。
二、研究现状
1. 多模态情感分析的背景
-
情感分析的演变: 传统的情感分析主要依赖于文本数据,而随着技术的发展,研究者们开始探索如何结合多种模态(如视觉、听觉和文本)来提高情感识别的准确性。
-
多模态的优势: 不同模态提供了互补的信息,能够更全面地捕捉情感。例如,语音的语调、面部表情和文本内容可以共同帮助更准确地理解说话者的情感状态。
2.当前研究的挑战
-
缺失模态问题: 在实际应用中,某些模态可能会缺失,这导致情感分析面临挑战。研究者们需要找到有效的方法来处理缺失模态,以减少不一致性。
-
模态间的不一致性: 不同模态可能传递出相互矛盾的信息,如何协调这些信息以得出一致的情感判断是一个重要的研究问题。
3.未来研究方向
-
集成方法的改进: 未来的研究可以集中在如何更有效地集成不同模态的信息,以提高情感分析的准确性和鲁棒性。
-
深度学习模型的优化: 进一步探索深度学习模型在多模态情感分析中的应用,尤其是在处理缺失模态和不一致性方面的优化。
三、本文方法描述
1.目前研究存在问题
针对多模态情感分析中的情态缺失问题,当情态缺失导致情感发生变化时,会出现不一致现象。决定整体语义的缺失情态可以被认为是关键的缺失情态。然而,以前的研究都忽略了不一致现象,简单地丢弃缺失的模态,或者仅仅从可用的模态中生成相关的特征。忽略关键的缺失情态格可能导致错误的语义结果。

缺失关键情态的情况,其中缺失的情态用红色虚线标记,语义词用蓝色标记
MSA的模态缺失问题
关于MSA中的特征输入策略,以前的工作大致可以分为两类
1.生成方法
生成方法旨在通过生成新的数据来匹配观察到的分布,主要包括以下几种技术:
-
变分自编码器(Variational Auto-Encoder, VAE):VAE被用来将输入变量映射到多元潜在分布,从而生成与现有模态相匹配的缺失模态特征。
-
生成对抗网络(Generative Adversarial Networks, GAN):GAN通过对抗训练的方式生成缺失模态的图像或特征。例如,Cai等(2018)将缺失模态问题转化为条件图像生成任务,旨在基于现有模态生成缺失的模态图像。
这些生成方法的优势在于能够生成与真实数据分布相似的缺失模态特征,从而在情感分析中提供更丰富的信息。
2. 联合学习方法
联合学习方法则侧重于从观察到的模态中学习潜在表示,主要包括以下策略:
-
循环一致性策略:该策略通过确保不同模态之间的表示能够相互转换,从而提高联合表示学习的鲁棒性。例如,Zhao等(2021)采用循环一致性策略来增强模态间的关联性。
-
特征重建:Zeng等(2022)通过附加标签来重建不确定缺失模态的特征,以提高模型的预测能力。
联合学习方法的优点在于能够有效利用现有模态的信息,通过学习模态间的关系来增强模型 的表现力和鲁棒性。
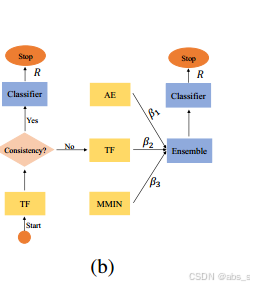
2.我们的方法
我们提出了一个基于集成的缺失模态重构(EMMR)网络来检测和恢复关键缺失模态的语义特征。具体来说,我们首先通过主干编码器-解码器网络学习剩余模态的联合表示。然后,基于恢复的特征,我们检查语义一致性,以确定缺失的情态是否对整体情感极性至关重要。一旦由于关键模态缺失而导致的不一致问题存在,我们集成了几种编码器-解码器方法以更好地做出决策。
1.集成学习方法
集成学习是一种机器学习技术,通过结合多个基模型的预测结果,以提高整体模型的性能和鲁棒性。它的核心思想是“众包智慧”,即多个模型的集成往往能比单一模型提供更好的预测效果。以下是集成学习的主要概念和方法:
1. 集成学习的基本概念
-
基模型:集成学习依赖于多个基模型(也称为弱学习器),这些模型可以是同种类型(如多个决策树)或不同类型(如决策树、支持向量机、神经网络等)。
-
组合策略:集成学习通过特定的组合策略将基模型的预测结果进行融合,常见的组合策略包括投票、平均和加权等。
2. 集成学习的主要方法
-
Bagging(自助聚合):通过对训练数据进行重采样,生成多个不同的训练集,训练多个基模型,然后将它们的预测结果进行平均(回归任务)或投票(分类任务)。随机森林就是一种典型的Bagging方法。
-
Boosting(提升法):通过逐步训练多个基模型,每个新模型专注于纠正前一个模型的错误。每个模型的权重根据其性能进行调整,最终将所有模型的预测结果加权组合。AdaBoost和XGBoost是常见的Boosting方法。
-
Stacking(堆叠):将多个基模型的输出作为新的特征输入到一个更高层次的模型(通常称为元学习器)中进行训练。通过这种方式,可以利用不同模型的优势来提高最终的预测性能。
3. 集成学习的优点
-
提高准确性:集成学习通常能显著提高模型的预测准确性,尤其是在数据噪声较大或特征复杂的情况下。
-
降低过拟合:通过结合多个模型的预测,集成学习能够有效降低单一模型可能出现的过拟合现象。
-
增强鲁棒性:集成学习对异常值和噪声数据的鲁棒性更强,因为不同模型的错误可以相互抵消。
四、具体方法及模型框架
1.预准备
给定一组具有三种模态的多模态数据:S = [Xv, Xa, Xt],其中Xv, Xa和Xt分别表示视觉,声学和文本模态。假设只有一个模态缺失,在不失一般性的前提下,我们用X ' m表示缺失的模态,其中m∈{v, a, t}。
形式上,我们的问题定义如下:对于给定的三元组(Xv, Xa, Xt),有一个模态随机缺失。主要任务是根据可用的模式对整体情绪(积极,中立或消极)进行分类。
2.骨干网络
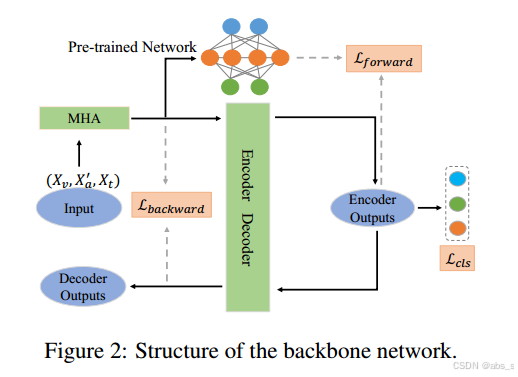
以缺乏声学模态的三重(Xv, X ' a, Xt)作为输入,首先由多头注意(MHA)模块编码,然后经过两个分支:(1)一个由预先训练的网络编码,该网络使用所有完整模态进行训练,(2)另一个通过编码器-解码器网络获得相应的输出,其中编码器输出用于情感分类。最后,计算前向相似损失和后向重构损失来监督联合特征的学习过程。
(1)特征提取:
视觉表征:我们采用OpenFace2.0工具包来获得709维的视觉表示,除了帧号、face_id和时间戳等无关属性的数据。
文本表示:对于每个文本话语,使用预训练的Bert (12层,768隐藏,12头)来获取768维单词向量。
声学表示:采用Librosa 提取33维声学特征,包括过零率、Mel-Frequency倒谱系数(MFCC)和常q变换(CQT)的属性。
输入的三种模态(视觉、声学和文本)首先通过多头注意力模块进行编码。MHA模块能够捕捉不同模态之间的关系和重要特征。
表达式为:
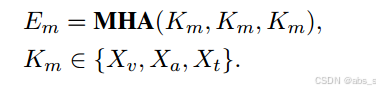
所有提取的模态特征在MHA模块处理后被连接成一个整体输入序列:

其中||是垂直连接操作。
(2)预训练网络
预训练网络利用完整模态的预训练网络来指导缺失模态的学习过程。具体来说,我们首先连接三个完整的模态,然后将它们输入softmax分类器进行训练:
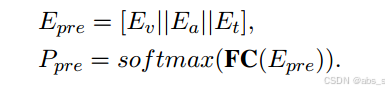
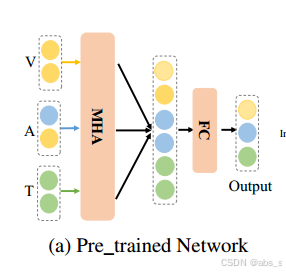
一旦具有完整模态的模型得到很好的训练,我们在整个训练阶段固定预训练的网络
(3)编解码器网络
编码器-解码器网络是一个核心组件,旨在处理输入数据并生成重建输出。该网络由两个主要部分组成:编码器(φ)和解码器(ψ)。编码器负责将输入数据映射到一个隐含特征空间,而解码器则将这个隐含特征空间映射回原始输入数据的重建。
编码器
功能:编码器的主要任务是将输入数据(X)转化为一个特征表示(F)。这个特征表示包含了输入数据的关键信息,便于后续的解码过程。
表达式:
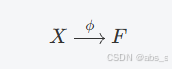
其中 X 是输入数据,F 是编码器的输出特征。
解码器
功能:解码器的任务是从编码器生成的特征表示中重建输入数据(X′)。解码器的输出应该尽可能接近原始输入,以实现有效的重建。
表达式:
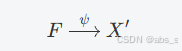
其中 X′ 是解码器的输出,即重建后的输入数据。
网络组件
在编码器-解码器网络中,使用了以下几种具体的网络结构:
EMMR(Ensemble-based Missing Modality Reconstruction)集成了以下几种编码器-解码器方法:
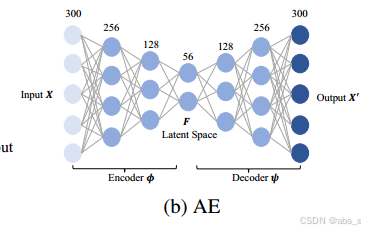
(1)自编码器(Autoencoder, AE):
1.AE网络的设计旨在训练网络将输入数据复制到输出。具体而言,AE采用全连接层(Fully Connected, FC),其层大小为[300, 256, 128, 64, 128, 256, 300]。
(2)缺失模态想象网络(Missing Modality Imagination Network, MMIN):
1.MMIN采用级联残差自编码器(Cascade Residual Autoencoder, CRA)结构,包含多个残差自编码器(Residual Autoencoders, RA)。具体使用了5个RA,层设置与AE相同。
2.编码器和解码器的输出分别为:
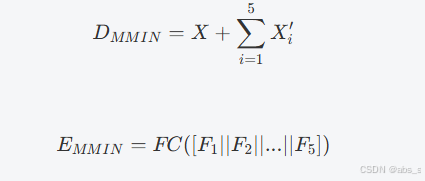

(3)变换器(Transformer, TF)
TF架构遵循编码器-解码器结构,能够有效处理序列输入数据。利用多头注意力机制(Multi-Head Attention, MHA)和前馈网络(Feed-Forward Networks, FFN)来生成编码器和解码器输出。
编码器输出为:
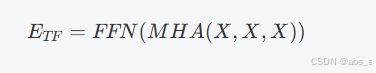
解码器输出为:
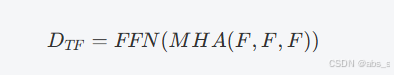
3.集成学习
对于输入的重建,我们用解码器输出中的相应表示替换缺失的模态。例如输入(Xv, X ' a, Xt)和重构输出(DT F v, DT F a, DT F t),我们可以得到恢复的输入(Xv, DT F a, Xt)。为了简化随后的数学表达式,我们将恢复的输入表示为(Iv, Ia, It)。可以获得恢复输入的情绪:
![]()
由于缺少情态而导致情绪发生变化时,就会出现不一致现象。基于这一现象,我们利用不一致性来确定缺失情态是否对整体情感极性至关重要。具体来说,我们首先结合每两个模态来获得相应的情感标签:
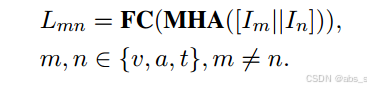
当恢复的完整模态的情感标签与剩余可用模态的语义标签不相等时,缺失模态可以视为关键缺失模态。然而,每种模式的重要性是不同的。如图所示,我们建议根据它们的最大逻辑值(L’k)来分配权重:
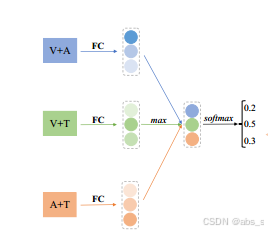
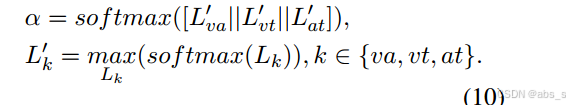
然后,可以访问具有键缺失模态的聚合表示:
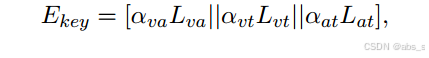
我们首先用TF编码器将输入馈送到骨干网络。基于恢复的特征,我们检查恢复的完整模态与原始可用模态之间的语义一致性。一旦它们与缺失模态不一致或不一致,我们就整合TF、AE和MMIN以进行进一步的决策。考虑到集成学习中多种方法的综合性能优于单一方法,我们根据相应的关注权重将三个提取的特征组合在一起。
总体培训目标(Ltotal)表示为:
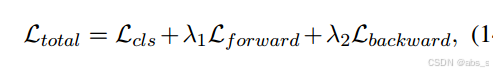
cls为分类损失,Lf forward为正向差分损失,Lbackward为后向重构损失,λ1、λ2为对应的权值。
前向损失由预训练输出(Epre)与编码器输出(F)之差计算,使用Kullback Leibler散度损失函数(DKL):
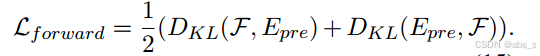
后向重构损失(Lbackward):对于后向损失,我们的目标是监督由解码器输出(X ')和处理后输入(X)计算的联合公共向量重构。
![]()
我们将最终输出R输入到一个带有softmax激活函数的全连接网络中,用于最终的情感分类:
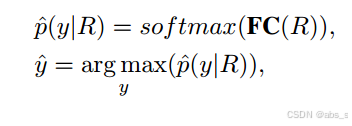
其中y´为预测标号。具体来说,我们使用标准的交叉熵损失来完成这个分类任务:
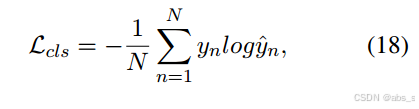
N为样本个数,yn为第N个样本的真实标号。
五、实验
1.数据集
-
CMU-MOSI:该数据集包含2199个情感片段,情感评分范围为[-3, 3],用于三类情感分类(负面、正面和中性)。
-
IEMOCAP:该数据集包含5个会话,共151个视频,主要用于情感识别,分类为两类(负面和正面)。
2.基线模型
为评估所提出模型的性能,选择了多个基线模型进行比较,包括:
AE(自编码器)
CRA(情感识别模型)
MMIN(多模态信息网络)
MCTN(多模态循环翻译网络)
TransM(基于变换器的模型)
3.实验结果
实验中使用了多个性能指标来评估模型的表现,包括F1分数、准确率(ACC)等。
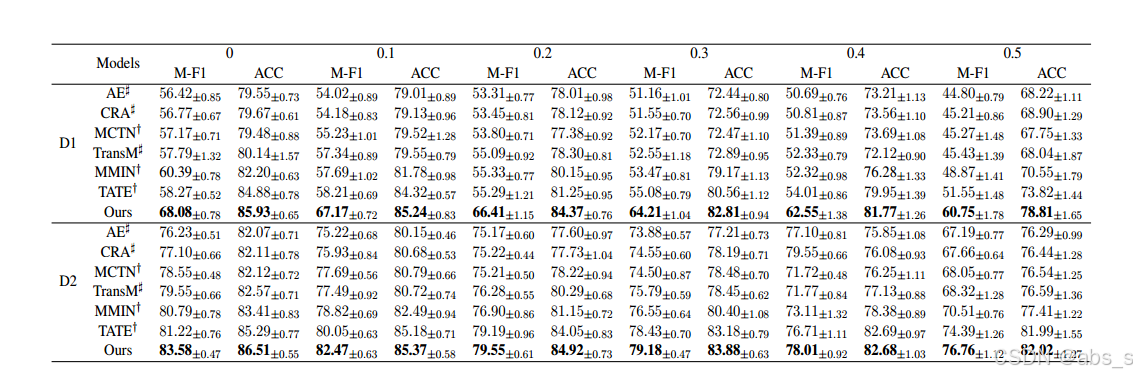
所有基线的性能,其中D1和D2分别表示CMU-MOSI和IEMOCAP数据集。
我们提出的EMMR在所有设置下都取得了最好的结果,特别是在CMU-MOSI数据集上的M-F1提高了8.54% ~ 11.12%。由于三种集成方法可以很好地处理缺少关键模态时的不一致问题,从而进一步提高鲁棒性,因此本研究结果具有重要意义。当缺失比从0增加到0.5时,随着缺失样本的增多,性能逐渐下降。我们还发现MCTN和TransM比AE和CRA具有更好的性能,这意味着循环翻译可以更好地融合来自多个模态的多模态信息。此外,由于变压器结构具有较强的学习能力,TATE和EMMR优于其他基准。
另一个观察结果是,当近一半的样本缺失时,我们提出的EMMR仍然表现良好,这是由于三种集成方法可以以互补的方式结合它们的预测。
4.消融实验
4. 消融实验
为了进一步理解各个模块对模型性能的影响,进行了消融实验:
单模态和双模态实验:评估使用单一模态或两种模态时模型的表现,结果显示,单模态的性能显著下降,特别是去除文本模态时。
模块影响:通过去除预训练网络和后向重建模块,观察模型性能的变化,从而分析各个模块对整体性能的贡献。
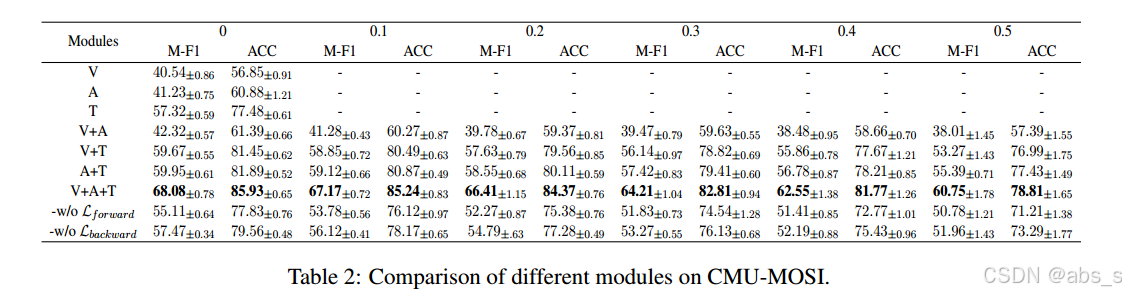
在单一情态下,特别是在去掉文本情态时,性能急剧下降。然而,当视觉模态缺失时,没有观察到类似的减少。这些结果表明,语篇情态可能主导着整体情感。此外,从数据中得出的一个显著结果是,两种模式结合后,性能有所提高,这表明多种模式可以通过相互学习互补的特征来提高性能。此外,从后两行可以看出,去除预训练网络后,相对于M-F1性能下降约9.97% ~ 14.39%,相对于ACC性能下降约7.60% ~ 9.12%,可见前向指导的重要性。同时,进一步分析表明,后向重构模块也为最终的联合表示学习提供了很好的监督。
5.不同集成方法的影响
仅使用基础网络:只依赖于单一的基础模型进行情感分类。
组合两种集成方法:将两种不同的集成策略结合使用,以提高模型的性能。
组合三种集成方法(最大操作):使用最大操作(max operation)来整合三个模型的输出,选择每个类别中预测概率最高的结果。
组合三种集成方法(平均操作):使用平均操作(average operation)来整合三个模型的输出,计算每个类别的平均预测概率。
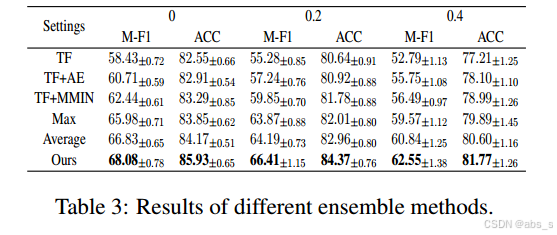
在实验中,通过对比不同集成方法的性能,得出了以下几个关键发现:
-
性能提升:通过组合多个模型的预测,集成方法显著提高了情感分类的准确率和F1分数。这是因为不同模型在处理数据时可能会关注到不同的特征,集成方法能够充分利用这些互补的信息。
-
鲁棒性增强:当某一模态缺失或模型出现错误时,集成方法能够有效地缓解这些问题。例如,当视觉模态缺失时,其他模态(如文本和声学)的信息可以帮助维持模型的整体性能。
-
处理不一致性:集成方法在处理多模态数据时,能够有效地解决由于模态缺失导致的预测不一致性问题。通过结合多个模型的输出,能够减少单一模型可能带来的偏差。
6.不同损失的影响
KL散度损失(KL loss)
- 定义:KL散度损失用于衡量两个概率分布之间的差异,适用于需要比较模型输出概率分布的任务。
- 优势:在情感分析任务中,KL损失能够更好地捕捉到不同类别之间的相似性,促进模型学习更准确的情感分布。
均方误差损失(MAE loss)
- 定义:MAE损失计算预测值与真实值之间的绝对差值,常用于回归任务。
- 劣势:在多类分类问题中,MAE损失可能无法有效捕捉类别间的关系,导致模型对类别的区分能力不足。
余弦相似度损失(cosine loss)
- 定义:余弦相似度损失用于衡量两个向量之间的角度差异,适用于需要比较向量方向的任务。
- 劣势:虽然余弦损失在某些情况下能够有效捕捉相似性,但在情感分析中,可能不如KL损失在处理概率分布时表现优异。
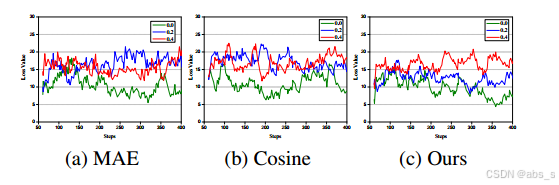
结果:
训练损失曲线
-
平滑性:KL损失的训练损失曲线相较于MAE和余弦损失更加平滑,表明模型在训练过程中具有更好的收敛性。这意味着KL损失能够更有效地引导模型学习,从而减少训练过程中的波动。
最小损失值
-
性能比较:在不同损失函数的比较中,KL损失达到了最小的损失值(4.89),而MAE和余弦损失的最小损失值相对较高。这表明KL损失在评估模型输出与真实分布之间的差异时更具优势。
缺失率的影响
-
缺失模态:随着缺失率的增加(例如0.2和0.4),训练损失曲线的波动性增加,尤其在使用MAE和余弦损失时更为明显。这表明在模态缺失的情况下,KL损失能够更好地保持模型的稳定性和性能。
六、总结
我们重点研究了在MSA中缺少关键模态时的不一致现象。EMMR首先通过主干编码器-解码器网络从剩余模态中学习特征。然后,我们通过检查恢复的完整模态与原始可用模态之间的语义一致性来区分关键模态。然后,利用三种基于主干编解码器网络的集成方法,在存在不一致现象时进行决策。实验结果和分析证明了该方案与几种最新方法的有效性。未来的研究将集中于综合不同的集成方法进行综合分析。


















 1443
1443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









