







文章目录
1. 问题描述
现实环境中经常遇到模态不完整问题:语音可能由于背景噪音或传感器故障而丢失;由于自动语音识别错误或未知单词,文本可能不可用;由于光照、运动或遮挡,可能无法检测到面部。本研究旨在利用缺失模态数据预测出相应视频片段对应情感类别。
2. 模态缺失相关工作
(1) 数据增强方法:随机删除输入模拟缺失模态情况(训练期间随机删除视觉片段,模拟真实世界的缺失模态场景)
(2) 基于生成方法:生成具有相似分布的新数据,以服从观测数据分布
(3) 基于联合学习方法:根据不同模态间的关系学习联合表示(目前主流,目前看到的近3年文章都是基于联合学习的方法)
3. 实验数据集
(1) IEMOCAP:二元对话会话数据集,设置四类情绪识别
(2) MSP-IMPROV:二元对话会话数据集,包含四种情绪设置
(3) CMU-MOSI:来源YouTube,情感标签在[-3,3]范围,被标注为积极或消极当作二分类任务。也有研究直接用所标注的值。
(4) CMU-MOSEI:MOSI数据集升级版,同样被标注为积极和消极
(5) MELD:来源老友记,考虑了7种情绪标签和3种情感倾向标签(积极消极中性)
4. 实验设计
(1) 完全缺失模态数据:测试数据往往全部为缺失模态。(3种模态,缺失一个或者两个,共有6种缺失方案。因此由全模态数据集生成缺失模态数据集,生成的缺失模态数据集数量是全模态数据集的6倍);
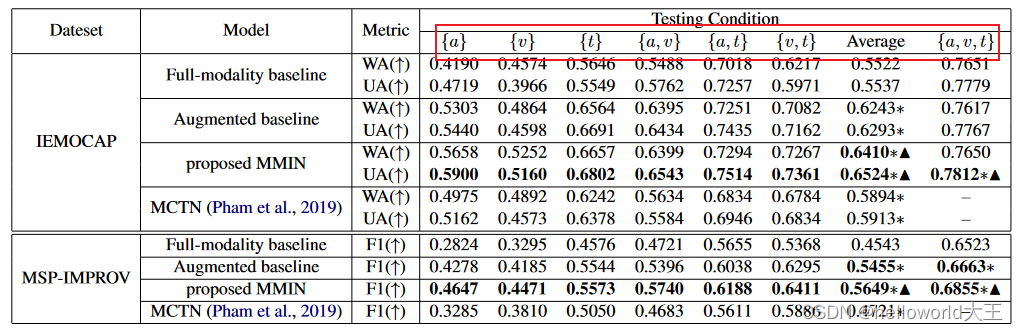
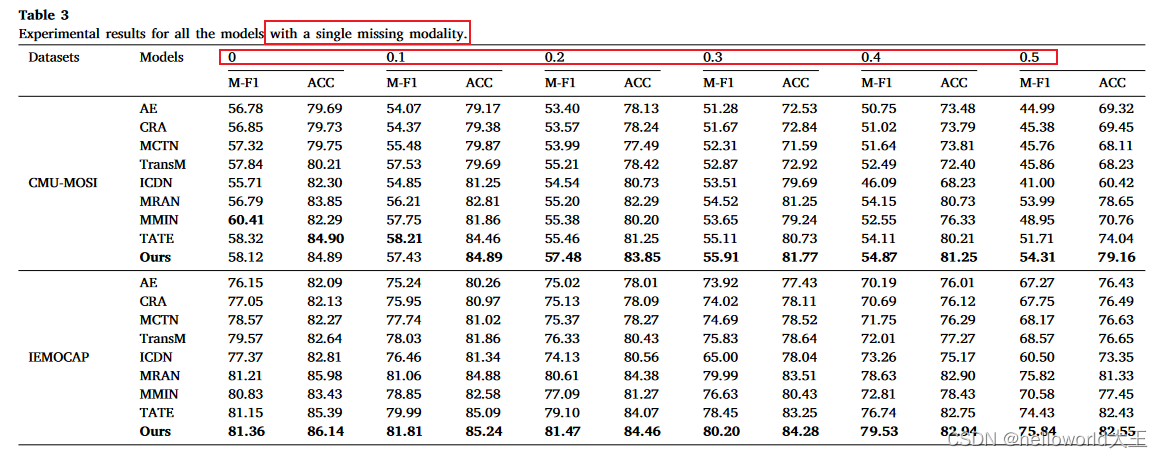
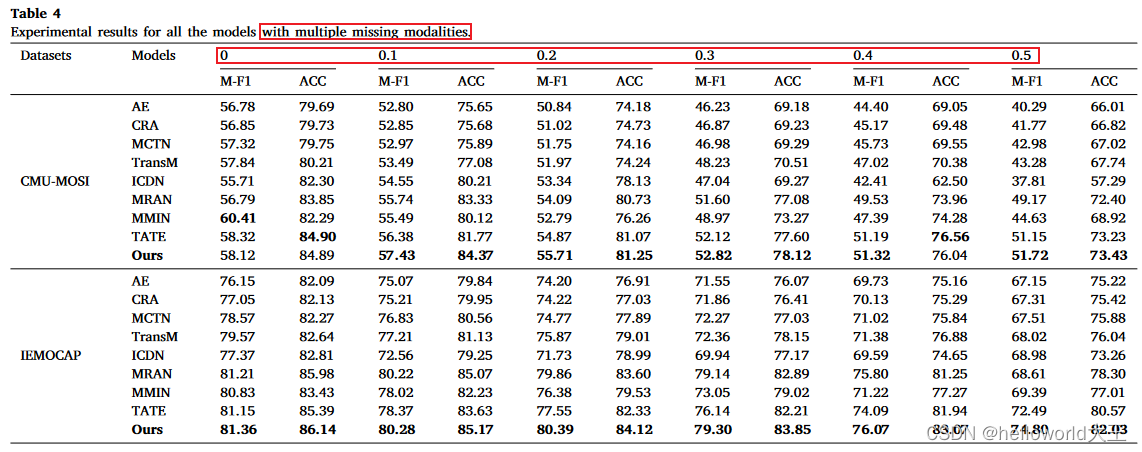
(2) 部分缺失数据:测试数据部分缺失(通过设置缺失率选择相应比重的缺失数据,然后随机缺失一个或者两个模态)
5. 含缺失模态的输入数据定义
(1) 三元组:固定输入为
(
A
,
T
,
V
)
(A,T,V)
(A,T,V) 三元组形式,对于缺失模态用0向量填充。部分文献还对缺失模态进行标签编码。
(2) 单独输入:基于模态转换模型,不进行统一处理
(3) 统一输入:根据不同缺失,设置不同输入组合
{
(
A
)
,
(
T
)
,
(
V
)
,
(
A
,
T
)
,
(
A
,
V
)
,
(
T
,
V
)
}
\{(A),(T),(V),(A,T),(A,V),(T,V)\}
{(A),(T),(V),(A,T),(A,V),(T,V)}
6. 文献阅读
6.1 缺失模态想象网络用于不确定缺失模态的情绪识别
论文地址:https://aclanthology.org/2021.acl-long.203/
总结:通过构建缺失模态特征,学习到能表征情感的多模态联合特征
(1)多模态编码器预训练
使用全模态数据训练用于提取模态特征的模态编码器网络

(2)MMIN模型训练
基于级联残差自编码器(CRA)和循环一致性学习的想象模块,用于在给定相应可用模态表示的情况下想象缺失模态的表示。收集CRA中自编码器的潜在向量,形成联合多模态表示;
- 残差自编码器:预测缺失模态的多模态特征
- 循环一致性想象模块:两个独立网络的耦合架构在两个方向上进行想象预测,包括forward(可用模态→缺失模态)以及backward(缺失模态→可用模态)
- 总损失函数为预测分类损失(交叉熵)、前向损失和反向损失(均为JS散度)加权和。
整体过程:
首先多模态模态编码器E在全模态数据上进行预训练。利用E获取剩余模态的特征 h h h后,通过CAR获取预测的缺失模态特征 h ’ h’ h’,并与缺失模态数据单独通过固定参数E提取的特征 h ^ \widehat{h} h 比较(前向)。此外, h ’ h’ h’通过CRA得到恢复的可用模态特征 h ’’ h’’ h’’,与 h h h进行比较(反向)。CAR每个自编码器中间层拼接用于预测情感。

(3)MMIN模型分类
收集每个自编码器潜在向量进行连接得到联合多模态表示,用于情感类别预测。

6.2 利用模态不变性进行缺失模态的鲁棒多模态情感识别
论文地址:https://arxiv.org/abs/2210.15359
总结:MMIN的改进,从模态特定性和不变性出发进行改进
(1)全模态数据预训练
引入基于CMD距离约束策略,预训练特定性编码器和不变性编码器。(红色箭头表示基于CMD的距离约束,以强制各种模态特征映射到相同的语义子空间。)
L
c
m
d
=
1
3
∑
m
1
,
m
2
)
∈
{
(
t
,
a
)
,
(
t
,
v
)
(
a
,
v
)
}
(
∥
E
(
H
m
1
)
−
E
(
H
m
2
)
∥
2
+
∑
k
=
2
K
∥
C
k
(
H
m
1
)
−
C
k
(
H
m
2
)
∥
2
)
\begin{equation} \mathcal{L}_{\mathrm{cmd}}=\frac{1}{3} \sum_{\substack{\left.m_1, m_2\right) \in \\\{(t, a),(t, v) \\(a, v)\}}}\left(\left\|\mathbf{E}\left(H^{m_1}\right)-\mathbf{E}\left(H^{m_2}\right)\right\|_2 \quad+\sum_{k=2}^K\left\|C_k\left(H^{m_1}\right)-C_k\left(H^{m_2}\right)\right\|_2\right) \end{equation}
Lcmd=31m1,m2)∈{(t,a),(t,v)(a,v)}∑(∥E(Hm1)−E(Hm2)∥2+k=2∑K∥Ck(Hm1)−Ck(Hm2)∥2)
(2)IF-MMIN
- 特定性编码器
- 不变性编码器
整体过程:
利用预训练特定性编码器抽取输入的可用模态的特定特征 h h h,级联预训练不变编码器抽取不变特征 H ’ H’ H’,两者拼接送入级联残差自编码器预测缺失模态 h ’ h’ h’。利用固定参数的预训练特定性编码器,获取缺失模态数据的特定性特征 h ’’ h’’ h’’,与 h ’ h’ h’进行比较计算损失;利用固定参数的预训练不变性编码器,获取全模态的不变性特征 H H H,与 H ’ H’ H’进行比较计算损失。同样,利用级联自编码器隐层拼接进行情感预测。总损失包括特定特征损失、不变特征损失以及分类损失。

6.3 不确定缺失模态下标签辅助多模态情感分析
论文地址:https://arxiv.org/abs/2204.13707
总结:针对于不确定缺失模态,利用标签编码标记缺失模态
(1)标签编码
用四维数字表示模态缺失情况,第一位表示是否模态缺失(0为缺失),后面三位数字表示视觉,声学,文字三个模态的缺失情况(1为缺失)

(2)公共投影空间
为了将三个模态投影到公共空间,首先对于每个单一模态得到自相关的公共空间,
W
v
a
W_{va}
Wva,
W
v
t
W_{vt}
Wvt以及
W
t
a
W_{ta}
Wta为权重矩阵。然后将所有公共向量和编码标签连接,得到最终共同的联合表示。
C
v
=
[
W
v
a
E
v
∥
W
v
t
E
v
]
C
a
=
[
W
v
a
E
a
∥
W
t
a
E
a
]
C
t
=
[
W
v
t
E
t
∥
W
t
a
E
t
]
E
all
=
[
C
v
∥
C
a
∥
C
t
∥
E
t
a
g
]
\begin{equation} \begin{aligned} C_v & =\left[W_{v a} E_v \| W_{v t} E_v\right] \\ C_a & =\left[W_{v a} E_a \| W_{t a} E_a\right] \\ C_t & =\left[W_{v t} E_t \| W_{t a} E_t\right] \\ E_{\text {all }} & =\left[C_v\left\|C_a\right\| C_t \| E_{t a g}\right] \end{aligned} \end{equation}
CvCaCtEall =[WvaEv∥WvtEv]=[WvaEa∥WtaEa]=[WvtEt∥WtaEt]=[Cv∥Ca∥Ct∥Etag]

(3)TATE
整体的损失为分类损失(交叉熵)、前向损失(JS散度)、反向损失(JS散度)、标签重建损失(四维标签编码,MAE)加权和。
整体过程:
将缺失模态掩码为0,提取已有模态的原始特征后经过两个分支:
1)一个分支由预训练模型编码,该模型使用所有全模态数据进行训练;
2)另一个分支通过标签编码模块和公共空间投影模块获得对齐的特征向量。然后,通过Transformer编码器对更新后的表示进行处理,并计算预训练向量与编码器输出之间的前向相似性损失。同时,将编码后的输出输入分类器进行情感预测。最后,我们计算了后向重构损失和标签恢复损失来监督联合表示学习。

6.4 随机模态缺失情况下的多模态情感分析
论文地址:https://aclanthology.org/2022.emnlp-main.189/
总结:关键模态缺失引起情感不一致,基于集成学习检测和恢复关键缺失模态语义特征
(1)骨干网络
缺失模态数据先通过MHA模态编码,再经历两个分支
1)一个由预训练网络编码,该网络经过所有完整模式的训练,
2)另一个通过编-解码器网络获得相应的输出,其中编码器输出用于情感分类。 最后,计算前向相似性损失和后向重建损失来监督联合特征的学习过程。(整体架构和论文[3]类似)

(2)检测缺失模态是否为关键模态
将Decoder输出缺失模态代替初始化 X a ’ Xa’ Xa’,得到恢复的完整模态,经过MHA和FC得到恢复全模态预测的情感。通过语义一致性进行检测,比较恢复的完整模态和可用的模态预测语义标签,若相等说明所缺失的不是关键模态,可直接预测。
(3)集成学习减轻语义不一致性
若语义不一致,说明缺失关键模态,利用集成学习降低语义不一致性。
首先需要将恢复后的模态两两组合,获得相应的情感标签。由于每种模态组合重要性不同,根据最大逻辑获得各个模态组合的权重。
α
=
softmax
(
[
L
v
a
′
∥
L
v
t
′
∥
L
a
t
′
]
)
L
k
′
=
max
L
k
(
softmax
(
L
k
)
)
,
k
∈
{
v
a
,
v
t
,
a
t
}
E
k
e
y
=
[
α
v
a
L
v
a
∥
α
v
t
L
v
t
∥
α
a
t
L
a
t
]
\begin{equation} \begin{aligned} & \alpha=\operatorname{softmax}\left(\left[L_{v a}^{\prime}\left\|L_{v t}^{\prime}\right\| L_{a t}^{\prime}\right]\right) \\ & L_k^{\prime}=\max _{L_k}\left(\operatorname{softmax}\left(L_k\right)\right), k \in\{v a, v t, a t\} \\ & E_{k e y}=\left[\alpha_{v a} L_{v a}\left\|\alpha_{v t} L_{v t}\right\| \alpha_{a t} L_{a t}\right] \end{aligned} \end{equation}
α=softmax([Lva′∥Lvt′∥Lat′])Lk′=Lkmax(softmax(Lk)),k∈{va,vt,at}Ekey=[αvaLva∥αvtLvt∥αatLat]
得到聚合特征后,分别利用AE(自编码器)、MMIN[1]以及Transformer进行进一步决策,设置关注权重整合三个模型的输出,用于后续分类。

6.5 基于耦合转换融合网络的多模态情感分析的层次学习
论文地址:https://aclanthology.org/2021.acl-long.412/
总结:通过学习一种模态到另一种模态间的定向转换器,在模态缺失时可以重构缺失模态
(1)耦合转换融合网络
基于Transforemer编码器,采用环形一致性结构保持正向反向转换一致性,从而实现一个模态输入到另一个模态转移表达。 X a X_a Xa通过 T r a n A → V Tran_{A→V} TranA→V后得到 X v ’ X_v’ Xv’, X v ’ X_v’ Xv’通过 T r a n V → A Tran_{V→A} TranV→A得到 T r a n V → A ( X v ’ ) Tran_{V→A}(X_v’) TranV→A(Xv’);同理可得,对称过程为 X v X_v Xv通过 T r a n V → A Tran_{V→A} TranV→A后得到 X v ’ X_v’ Xv’, X v ’ X_v’ Xv’通过 T r a n A → V Tran_{A→V} TranA→V得到 T r a n A → V ( X v ’ ) Tran_{A→V}(X_v’) TranA→V(Xv’),构建损失函数需要保证生成的模态特征与原始模态特征距离尽可能小。(此处和[1]中循环一致性异曲同工,引入参数 α α α能平衡正向和反向循环一致性的贡献,从而获得更加灵活的循环一致性。)
l
A
→
V
(
X
a
,
X
v
)
=
∥
Tran
A
→
V
(
X
a
,
X
v
)
−
X
v
∥
F
+
+
∥
Tran
A
→
V
(
X
a
,
X
v
)
−
X
v
∥
F
l
V
→
A
(
X
v
,
X
a
)
=
∥
Tran
V
→
A
(
X
v
,
X
a
)
−
X
a
∥
F
+
∥
Tran
V
→
A
(
X
v
,
X
a
)
−
X
a
∥
F
l
A
↔
V
=
α
l
A
→
V
(
X
a
,
X
v
)
+
(
1
−
α
)
l
V
→
A
(
X
v
,
X
a
)
\begin{equation} \begin{aligned} & l_{A \rightarrow V}\left(\boldsymbol{X}_a, \boldsymbol{X}_v\right)=\left\|\operatorname{Tran}_{A \rightarrow V}\left(\boldsymbol{X}_a, \boldsymbol{X}_v\right)-\boldsymbol{X}_v\right\|_{F^{+}}+ \\ & \left\|\operatorname{Tran}_{A \rightarrow V}\left(\boldsymbol{X}_a, \boldsymbol{X}_v\right)-\boldsymbol{X}_v\right\|_F \\ & l_{V \rightarrow A}\left(\boldsymbol{X}_v, \boldsymbol{X}_a\right)=\left\|\operatorname{Tran}_{V \rightarrow A}\left(\boldsymbol{X}_v, \boldsymbol{X}_a\right)-\boldsymbol{X}_a\right\|_F+ \\ & \left\|\operatorname{Tran}_{V \rightarrow A}\left(\boldsymbol{X}_v, \boldsymbol{X}_a\right)-\boldsymbol{X}_a\right\|_F \\ & l_{A \leftrightarrow V}=\alpha l_{A \rightarrow V}\left(\boldsymbol{X}_a, \boldsymbol{X}_v\right)+(1-\alpha) l_{V \rightarrow A}\left(\boldsymbol{X}_v, \boldsymbol{X}_a\right) \end{aligned} \end{equation}
lA→V(Xa,Xv)=∥TranA→V(Xa,Xv)−Xv∥F++∥TranA→V(Xa,Xv)−Xv∥FlV→A(Xv,Xa)=∥TranV→A(Xv,Xa)−Xa∥F+∥TranV→A(Xv,Xa)−Xa∥FlA↔V=αlA→V(Xa,Xv)+(1−α)lV→A(Xv,Xa)

(2)多模态卷积融合模块
作者认为在Transformer模态转换器的中间层,能得到两个模态间的联合表示。因此将将一对模态转换器中间层输出,按照时间维度进行拼接,再利用1D时间卷积探索局部关联。

(3)分层体系结构
提出一种利用多模态双向转移分层体系架构。对于3种模态两两转换,共有6个模态转换器,得到6个跨模态联合表征。将相同源模态转换的联合表征进行拼接,利用1D卷积提取局部特征,最后将所有融合特征整合通过MLP进行情感预测。(对于3个模态转换器共享参数
α
α
α,便于控制平衡训练损失。)

(4)预测阶段
将使用全模态数据训练的模态转换器用于缺失模态数据测试,获取转换器中间层联合表征,进行后续情感预测。

6.6 在多模态情感分析中增加对缺失情态的鲁棒性
论文地址:https://www.researchgate.net/publication/376711705_MissModal_Increasing_Robustness_to_Missing_Modality_in_Multimodal_Sentiment_Analysis
总结:提出三个约束,将缺失模态的表示与完整模态的表示进行对齐
(1)模态融合
对于提取到各个模态的特征,采用几个简单的MLP和tanh激活层作为融合网络,获得完整模态的特征
F
M
F_M
FM,以及缺失模态的特征
F
m
i
s
s
F_{miss}
Fmiss。(文中提到这里的融合方法可以换做更好的模型,作者再次只想突出后续约束的贡献)
F
M
=
M
L
P
(
[
T
;
A
;
V
]
)
∈
R
d
M
F
miss
=
M
L
P
(
[
modality
;
…
]
)
∈
R
d
M
\begin{equation} \begin{aligned} F_M & =M L P([T ; A ; V]) \in \mathbb{R}^{d_M} \\ F_{\text {miss }} & =M L P([\text { modality } ; \ldots]) \in \mathbb{R}^{d_M} \end{aligned} \end{equation}
FMFmiss =MLP([T;A;V])∈RdM=MLP([ modality ;…])∈RdM

(2)缺少模态时的约束
本文提出三种损失作为约束,将缺失模态表示 F m i s s F_{miss} Fmiss和完整模态表示 F M F_M FM对齐
i.几何对比损失:
引入对比学习,在情感标签监督中对来自相同话语样本的完整模态表征和缺失模态表征进行几何对齐。鼓励多模态融合网络将完整模态信息转移到缺失模态表征中,使它在处理缺失模态问题时更容易被区分。
对于同一批的多模态表征
B
=
{
F
M
i
,
F
miss
i
}
i
=
1
B
\mathcal{B}=\left\{F_M^i, F_{\text {miss }}^i\right\}_{i=1}^B
B={FMi,Fmiss i}i=1B,定义正样本
(
F
M
i
,
F
miss
i
)
\left(F_M^i, F_{\text {miss }}^i\right)
(FMi,Fmiss i),负样本为
(
F
M
i
,
F
miss
i
)
\left(F_M^i, F_{\text {miss }}^i\right)
(FMi,Fmiss i),
(
F
M
i
,
F
M
j
)
\left(F_M^i, F_M^j\right)
(FMi,FMj),
(
F
miss
i
,
F
miss
j
)
\left(F_{\text {miss }}^i, F_{\text {miss }}^j\right)
(Fmiss i,Fmiss j) 以及
(
F
M
i
,
F
miss
j
)
\left(F_M^i, F_{\text {miss }}^j\right)
(FMi,Fmiss j),计算正样本和负样本的相似度之和。
s
p
,
q
(
i
,
j
)
=
exp
(
F
p
i
⋅
F
q
j
/
γ
)
,
p
,
q
∈
{
M
,
miss
}
N
p
,
q
(
i
)
=
∑
i
≠
j
B
s
p
,
p
(
i
,
j
)
+
∑
j
=
1
B
s
p
,
q
(
i
,
j
)
\begin{equation} \begin{aligned} s_{p, q}(i, j) & =\exp \left(F_p^i \cdot F_q^j / \gamma\right), p, q \in\{M, \text { miss }\} \\ N_{p, q}(i) & =\sum_{i \neq j}^B s_{p, p}(i, j)+\sum_{j=1}^B s_{p, q}(i, j) \end{aligned} \end{equation}
sp,q(i,j)Np,q(i)=exp(Fpi⋅Fqj/γ),p,q∈{M, miss }=i=j∑Bsp,p(i,j)+j=1∑Bsp,q(i,j)
构建几何对比损失,
L
geo
=
−
1
B
∑
i
=
1
B
log
s
p
,
q
(
i
,
i
)
N
p
,
q
(
i
)
\begin{equation} \mathcal{L}_{\text {geo }}=-\frac{1}{B} \sum_{i=1}^B \log \frac{s_{p, q}(i, i)}{N_{p, q}(i)} \end{equation}
Lgeo =−B1i=1∑BlogNp,q(i)sp,q(i,i)
ii.分布距离损失
引入
L
2
L2
L2距离约束,进一步减小来自同一样本的
F
M
F_M
FM与
F
m
i
s
s
F_{miss}
Fmiss间的分布距离
L
dis
=
1
B
∑
i
=
1
B
∥
F
M
i
−
F
miss
i
∥
2
2
\begin{equation} \mathcal{L}_{\text {dis }}=\frac{1}{B} \sum_{i=1}^B\left\|F_M^i-F_{\text {miss }}^i\right\|_2^2 \end{equation}
Ldis =B1i=1∑B
FMi−Fmiss i
22
iii.情感语义损失
利用情绪标签真值监督标签空间中缺失模态表示的情感预测,减少由于模态缺失而引起与完整模态情感预测不一致。
L
sem
=
1
B
∑
i
=
1
B
∣
y
i
−
y
^
miss
i
∣
\begin{equation} \mathcal{L}_{\text {sem }}=\frac{1}{B} \sum_{i=1}^B\left|y^i-\hat{y}_{\text {miss }}^i\right| \end{equation}
Lsem =B1i=1∑B
yi−y^miss i
iv.优化目标
在得到完整模态的情绪预测结果后,利用MAE损失对情绪标签进行回归。
L
task
=
1
B
∑
i
=
1
B
∣
y
i
−
y
^
M
i
∣
\begin{equation} \mathcal{L}_{\text {task }}=\frac{1}{B} \sum_{i=1}^B\left|y^i-\hat{y}_M^i\right| \end{equation}
Ltask =B1i=1∑B
yi−y^Mi
最后计算所有训练损失的加权和,得到最终的优化目标:
L
total
=
L
task
+
L
sem
+
α
L
geo
+
β
L
dis
\begin{equation} \mathcal{L}_{\text {total }}=\mathcal{L}_{\text {task }}+\mathcal{L}_{\text {sem }}+\alpha \mathcal{L}_{\text {geo }}+\beta \mathcal{L}_{\text {dis }} \end{equation}
Ltotal =Ltask +Lsem +αLgeo +βLdis
6.7 情感分析中情态缺失问题的多模态重构和对齐网络
论文地址:https://dl.acm.org/doi/abs/10.1007/978-3-031-27818-1_34
总结:引入以文本为中心多模态对齐模块,缓解文本模态缺失导致性能衰退。
(1)特征重构
- 对原始特征进行特征重构,实现对缺失模态重建,对已有模态加强。
- 重构特征
f
s
’
f_s’
fs’ = 原始特征
f
s
f_s
fs + 多模态嵌入
f
m
f_m
fm + 缺失索引嵌入
f
i
f_i
fi
- 多模态嵌入 f m f_m fm:三个模态拼接后通过MLP得到多模态融合表示。
- 缺失索引嵌入 f i f_i fi:缺失模态编码,与论文[3]类似,0表示缺失模态。再通过MLP得到缺失索引嵌入。
- 用全模态数据预训练特征提取器得到预训练特征,利用MSELoss计算其与重构特征之间的损失。
(2)以文本为中心的多模态对齐模块
文本贡献最大,在此将非文本模态和文本稳态对齐。
首先利用MLP将声音和视觉投影到与文本同样维度,利用GloVe对情感类别进行编码。在训练过程中国,保持情感嵌入E冻结,利用
L
2
L2
L2归一化约束将文本特征空间种三个模态特征聚类为锚点。
∥
f
a
proj
−
E
y
∥
2
2
+
∥
f
t
′
−
E
y
∥
2
2
+
∥
f
v
proj
−
E
y
∥
2
2
\begin{equation} \left\|f_a^{\text {proj }}-E_y\right\|_2^2+\left\|f_t^{\prime}-E_y\right\|_2^2+\left\|f_v^{\text {proj }}-E_y\right\|_2^2 \end{equation}
faproj −Ey
22+∥ft′−Ey∥22+
fvproj −Ey
22
此时,视觉和声学模态在文本特征空间的位置,被引导至更具语义的文本特征处
(3)分类
计算三个模态和所有情感嵌入的点积相似度加权和,从而获得分类为各个情感的概率
p
a
=
E
f
a
p
r
o
j
,
p
t
=
E
f
t
′
,
p
v
=
E
f
v
p
r
o
j
p
=
softmax
(
w
a
p
a
+
w
t
p
t
+
w
v
p
v
)
\begin{equation*} \begin{gathered} p_a=E f_a^{p r o j},\quad p_t=E f_t^{\prime},\quad p_v=E f_v^{p r o j} \\ p=\operatorname{softmax}\left(w_a p_a+w_t p_t+w_v p_v\right) \end{gathered} \end{equation*}
pa=Efaproj,pt=Eft′,pv=Efvprojp=softmax(wapa+wtpt+wvpv)
总损失为分类损失(交叉熵)、缺失模态重构损失、对齐损失(模态特征和其对应情感嵌入之间L2距离之和)加权和。




















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











