







SSD是一种直接预测目标类别和bounding box的多目标检测算法。它使用低层feature map检测小目标,使用高层feature map检测大目标。
一、SSD的优势与劣势
1.优势
(1)没有生成边界框(proposal)的过程,进而提高了速度。
(2)SSD的核心是预测固定的一系列默认边界框的类别分数和边界框偏移,使用更小的卷积滤波器应用到特征映射上。
(3)为了实现高检测精度,我们根据不同尺度的特征映射生成不同尺度的特征映射生成不同尺度的预测,并通过纵横比明确分开预测。
(4)这些设计功能使得即使在低分辨率输入图像上也能实现简单的端到端训练和高精度,从而进一步提高速度与精度之间的权衡。
2.劣势
(1)需要人工设置prior box的min_size,max_size和aspect_ratio值。网络中prior box的基础大小和形状不能直接通过学习获得,而是需要手工设置。而网络中每一层feature使用的prior box大小和形状恰好都不一样,导致调试过程非常依赖经验。
(2)虽然采用了pyramdial feature hierarchy的思路,但是对小目标的recall依然一般,并没有达到碾压Faster RCNN的级别。作者认为,这是由于SSD使用conv4_3低级feature去检测小目标,而低级特征卷积层数少,存在特征提取不充分的问题。
二、模型
1.概述
SSD方法基于前馈卷积网络,该网络产生固定大小的边界框集合,并对这些边界框中存在的目标类别实例进行评分,然后进行非极大值抑制步骤来产生最终的检测结果。然后,我们将辅助结构添加到网络中以产生具有以下关键特征的检测:
用于检测的多尺度特征映射。我们将卷积特征层添加到截取的基础网络的末端。这些层在尺寸上逐渐减小,并允许在多个尺度上对检测结果进行预测。用于预测检测的卷积模型对于每个特征层都是不同的。
用于检测的卷积预测器。每个添加的特征层(或者任选的来自基础网络的现有特征层)可以使用一组卷积滤波器产生固定的检测预测集合。对于具有p通道的大小为m×n的特征层,潜在检测的预测参数的基本元素是3×3×p的小核得到某个类别的分数,或者相对于默认框坐标的形状偏移。在应用卷积核的m×n的每个位置,它会产生一个输出值。边界框偏移输出值是相对每个特征映射位置的相对默认框位置来度量的。
默认边界框和长宽比。对于网络顶部的多个特征映射,我们将一组默认边界框与每个特征映射单元相关联。默认边界框以卷积的方式平铺特征映射,以便每个边界框相对于其对应单元的位置是固定的。在每个特征映射单元中,我们预测单元中相对于默认边界框形状的偏移量,以及指出每个边界框中存在的每个类别实例的类别分数。具体而言,对于给定位置处的k个边界框中的每一个,我们计算c个类别分数和相对于原始默认边界框形状的4个偏移量。这导致在特征映射中的每个位置周围应用总共(c+4)k个滤波器,对于m×n的特征映射取得(c+4)kmn个输出。我们的默认边界框与Faster R-CNN[2]中使用的锚边界框相似,但是我们将它们应用到不同分辨率的几个特征映射上。在几个特征映射中允许不同的默认边界框形状让我们有效地离散可能的输出框形状的空间。
2.基础
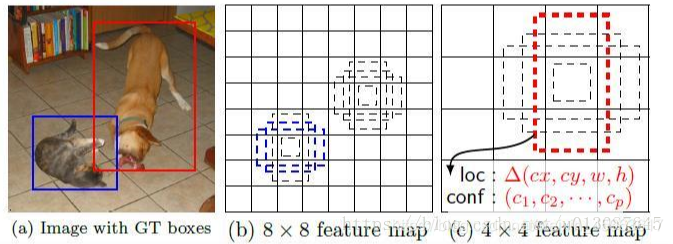
feature map cell:是指feature map中每一个小格子,就是上图中的每个小方格,上图分别有64个feature map cell和16个feature map cell.
default box:是指每个feature map cell上都有一系列固定大小的box,也就是上图中的虚线框。
ground truth: 在机器学习中,数据是有标注的<x,t>, t是正确标注的ground
truth。就好像上图中x是框的信息,t就是猫或狗的信息。
prior box:是指在实际选择fdefault box 过程中(在实际选择中我们并不是
每个feature map cell的k个default box都取)也就是说default box是一种概念,prior box则是实际的选取。
训练中一张完整的图片送进网络获得各个feature map,对于正样本训练来说,需要先将prior box与ground truth box做匹配(就是把一张图片输入到 region network中,判断有物体的区域
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 695
695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









