






 本文介绍了基于LLaMA的优化模型LLaMA2,重点讨论了如何通过增加训练数据、改进注意力机制和对话优化,以及预训练、有监督微调和强化学习来创建适用于聊天场景的LLaMA-Chat模型。文章详细描述了模型训练方法和策略,包括RLHF中的奖励模型和PPO训练过程。
本文介绍了基于LLaMA的优化模型LLaMA2,重点讨论了如何通过增加训练数据、改进注意力机制和对话优化,以及预训练、有监督微调和强化学习来创建适用于聊天场景的LLaMA-Chat模型。文章详细描述了模型训练方法和策略,包括RLHF中的奖励模型和PPO训练过程。
1. 背景
通过聊天接口的形式与大语言模型进行交互,可以让语言模型最大程度的发挥实际作用。因此本文基于LLaMA进行优化得到新的大语言模型LLaMA2。并在LLaMA2的基础上进行了进一步的微调,针对对话用例进行了训练和调整,从而与现有的聊天语言模型(chat model)进行对标,得到的模型即LLaMA-Chat。本文开源了一系列模型从7b大小到70b大小,并给出了详细的实现方式和代码。(Github: https://ai.meta.com/resources/models-and-libraries/llama/)
2. LLaMA2
相比于LLaMA模型,现有的LLaMA2主要有三点不同:
- 在训练时收集使用了更多的公开数据,训练语料库增加了40%
- 模型可以接受的文本输入长度翻倍(doubled the context length),从原来的2K变成了4K
- 对于更大规模的模型采用了分组查询自注意力机制(Grouped-Query Attention)提高推理效率
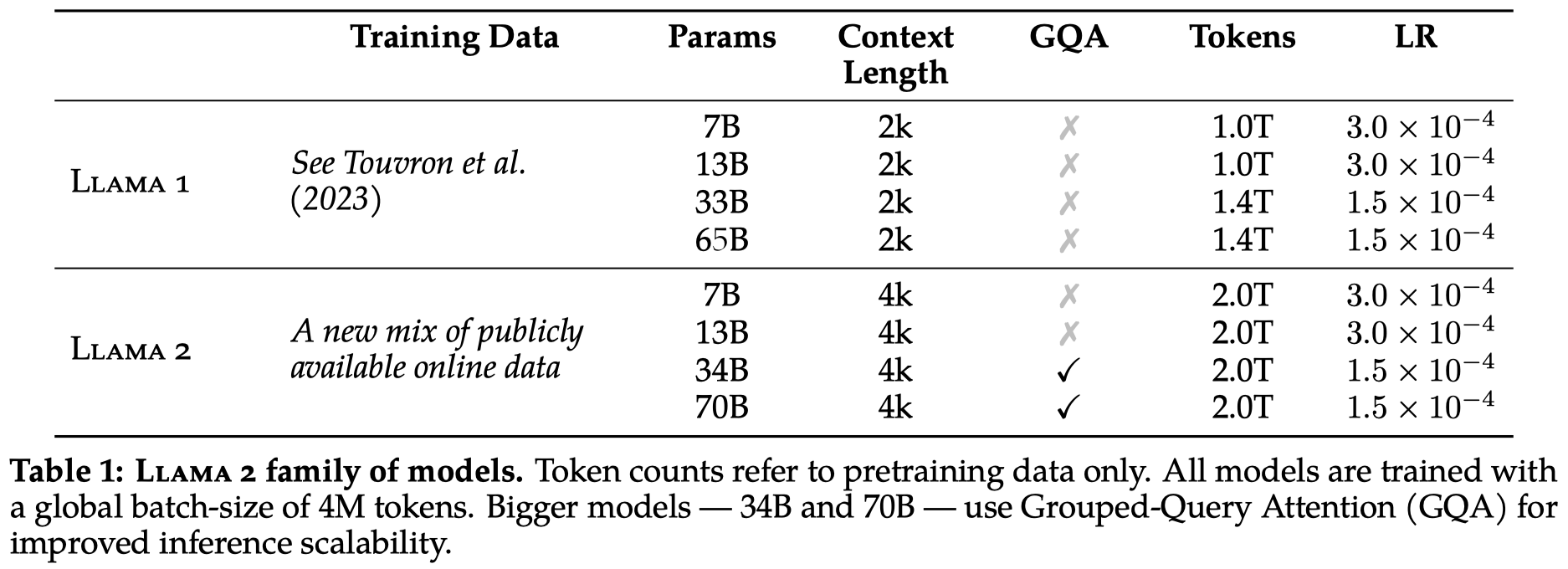
3. LLaMA-Chat Model
基于LLaMA2针对对话进行优化和调整,整体流程分为:Pretraining + Supervised Fine-Tuning(SFT) + Reinforcement Learning with Human Feedback(RLHF) +
3.1 Pretraining
预训练的流程即LLaMA2基座模型的训练过程,通过大量无标注语料库使用自回归的方式(下一个词预测)进行训练,得到一个能力出众的大语言模型。
3.2 SFT
为了更好地从指令层面上对大语言模型进行调用,需要使用有监督的指令微调数据对模型进行训练,让模型学习到对应的Prompt理解和回复生成能力。
如下图所示是一些SFT标注数据的示例,即给定对应的Prompt,我们希望模型能够给出相应的回复。LLaMA2证明少量的高质量的SFT数据会比大量低质缺乏多样性的数据更加有效,即少量干净高质的instruction-tuning数据能够让模型达到一个高水平。
在训练的过程中,通过将Prompt和Response串联在一起并使用分隔符分割,而后同样用自回归预测的方式进行训练,在进行梯度下降计算时对于Prompt部分的token loss置为0,只计算Response部分的损失从而达到SFT的目的。

3.3 RLHF
RLHF的目的即通过微调的方式进一步使得模型行为与人类的偏好所保持一致。对于给定的Prompt,模型通过调整超参数可以得到不同的Response Answer,而后根据对这些response answer进行评分,告诉模型哪个回答是更优的,通过这样的方式进行训练,模型可以学习到如何生成更好的回答。但人为进行online训练会成为瓶颈降低训练效率,因此提出了Reward Model + 强化训练的模式,希望利用RM来替代人类进行判断。
3.3.1 Reward Model
数据收集:首先让标注者给出prompt信息,而后通过选择不同规模的SFT-model变体以及超参数可以得到两个回答(Response),对这两个回答进行标注即哪个回答分数高(align with human),并根据两个回答的差异程度进行分类,即:(明显更好,更好,稍微更好,或可以忽略不计的更好/不确定)。
考虑到模型在训练过程中“更具帮助性”(helpfulness)和”安全性”(safety)往往是矛盾的,为了更好地应用于不同场景,在进行数据的收集和模型训练时分为两个部分分别进行处理训练得到两个模型(helpfulness model & safety model)。
当利用一个已有的RM训练得到一个新的Chat-model以后,模型的Generate Response能力得到了提高,这时数据产生偏移(RM初始阶段使用的是SFT-Model生成的数据训练的)可能导致RM模型能力降低,进一步影响Chat-Model的性能。因此引入了迭代对抗的思想,RM的训练数据是周期性的收集,增强Reward model用来训练LLAMA2-Chat,利用LLAMA2-Chat生成质量更高的数据再反馈训练Reward model。
模型结构:从输出输入角度来看给定Prompt和对应的Response,RM需要输出一个得分结果用来判断这个回答的好坏。从模型结构来看RM使用SFT-Model作为网络结构并进行初始化,把最后一层的下一个词预测头更改为线性层用来输出分数。
损失函数:RM模型训练的损失函数如下所示,其中
x
x
x表示的是输入的prompt信息,
y
y
y表示对应的Response answer输入,其中
y
c
y_c
yc代表更好的response,
y
r
y_r
yr表示更差的reponse,
r
θ
(
x
,
y
)
r_{θ}(x,y)
rθ(x,y)表示RM输出的奖励分数,
m
(
r
)
m(r)
m(r)两个response之间的差异程度。该损失函数即希望更好的reponse
y
c
y_c
yc可以得到更高的分数输出,更差的response
y
r
y_r
yr的分数更低,同时通过
m
(
r
)
m(r)
m(r)项希望两个答案差距越大则两个分数之间的差值也应该越大越好。
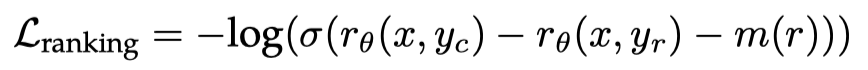
3.3.2 Rejection Sampling
前面说到,当我们训练得到一个RM以后就可以利用RM来判断一个模型回答的好坏,从而帮助进行强化学习训练。在LLaMA2中强化学习训练主要分为两种,分别是Rejection Sampling(RS) 和 PPO,而结合RM和Chat-Model的对抗迭代训练就可以得到RLHF-V1,…,RLHF-V5模型,能力越来越强。其中在RLHF-V1至V4中只使用了RS进行训练,而在RLHF-V5中首先使用RS训练以后再用PPO进行训练。下面介绍RS和PPO的细节。
在我们给定一批 p r o m p t prompt prompt和训练好的奖励模型 R M RM RM以后,对于每一个 p r o m p t prompt prompt输入到待训练的语言模型(LM)中通过控制超参数例如温度系数等就可以得到多个不同的回答输出 r e s 1 , r e s 2 , . . . , r e s k res_1, res_2,...,res_k res1,res2,...,resk,而后利用 R M RM RM对这些回答进行打分 s c o r e i = R M ( x , r e s i ) score_i=RM(x,res_i) scorei=RM(x,resi)并进行排序,取分数最高的回答作为一个标准答案与这个 p r o m p t prompt prompt构成一条有监督训练数据 ( p r o m p t , r e s b e s t s c o r e ) (prompt, res_{bestscore}) (prompt,resbestscore)。通过这样的方式我们可以借助奖励模型 R M RM RM和给定的一批 p r o m p t prompt prompt生成大量有标签的数据,从而使用SFT的方式对模型进行训练。
3.3.3 PPO
PPO的训练流程和Instruct-GPT大致相似,通过从数据库中批次采样
p
:
p
r
o
m
p
t
p:prompt
p:prompt并输入到待训练的语言模型
π
θ
\pi_{\theta}
πθ中并生成回答
g
:
o
u
t
p
u
t
g
e
n
e
r
a
t
e
g:output_{generate}
g:outputgenerate,我们希望将对应的
(
p
,
g
)
(p,g)
(p,g)输入到奖励模型
R
R
R中得到的分数
R
(
g
∣
p
)
R(g|p)
R(g∣p)越高越好,即训练促使模型生成更好的回答。同时我们希望
π
θ
\pi_{\theta}
πθ与其初始化参数模型
π
o
\pi_{o}
πo之间的差异越小越好,从而保证训练的稳定性和对抗数据的偏移性(RM和Generate Model的对抗数据偏移)。具体的损失函数如下所示。
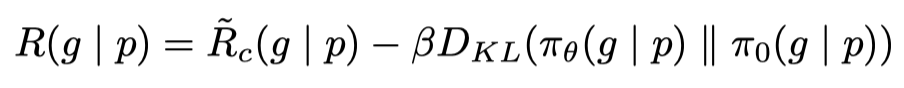
同时,LLaMA2进一步考虑了模型的安全性问题,为了促使模型尽可能的输出安全(无毒)的内容,在训练过程中安全模型(Safety Model)使用安全奖励模型(Safety Reward Model)进行训练,同时对于帮助性模型如果安全分数太低(Safety RM score < 0.15)则认为不是一个理想的安全输出,则也使用safety RM进行训练。如下图所示:

4. Reference
[1] Rejection Sampling
【手撕RLHF-Rejection Sampling】如何优雅的从SFT过渡到PPO
[2] Instruct-GPT
Instruct-GPT-CSDN博客
[3] 《Llama 2: Open Foundation and Fine-Tuned Chat Models》 - https://arxiv.org/pdf/2307.09288.pdfÂ

















 1769
1769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









