




 本文介绍了如何通过RLHF(强化学习的人类反馈)方法改进语言模型,使其更加有益、诚实和无害。首先进行有监督的预训练微调,接着训练奖励模型评估回答质量,最后通过PPO强化学习调整模型以更好地遵循人类行为规范。
本文介绍了如何通过RLHF(强化学习的人类反馈)方法改进语言模型,使其更加有益、诚实和无害。首先进行有监督的预训练微调,接着训练奖励模型评估回答质量,最后通过PPO强化学习调整模型以更好地遵循人类行为规范。
背景
人们希望语言模型是有帮助的(它们应该帮助用户解决问题)、诚实的(它们不应该捏造信息或误导用户)和无害的(它们不应该对人或环境造成身体、心理或社会伤害) ,即解决之前 LLM 容易出现的这种有毒和带有偏见的生成内容的问题 (not aligned with users)。将LLM与人类行为对齐即为本文的目的,主要通过RLHF(Reinforcement Learning of Human Feedback)的方式来进行实现。
RLHF
RLHF主要分为三个步骤:有监督的预训练微调(Supervised Fine-tuning, SFT)、奖励模型的训练(Reward Model, RM)以及强化学习训练PPO。
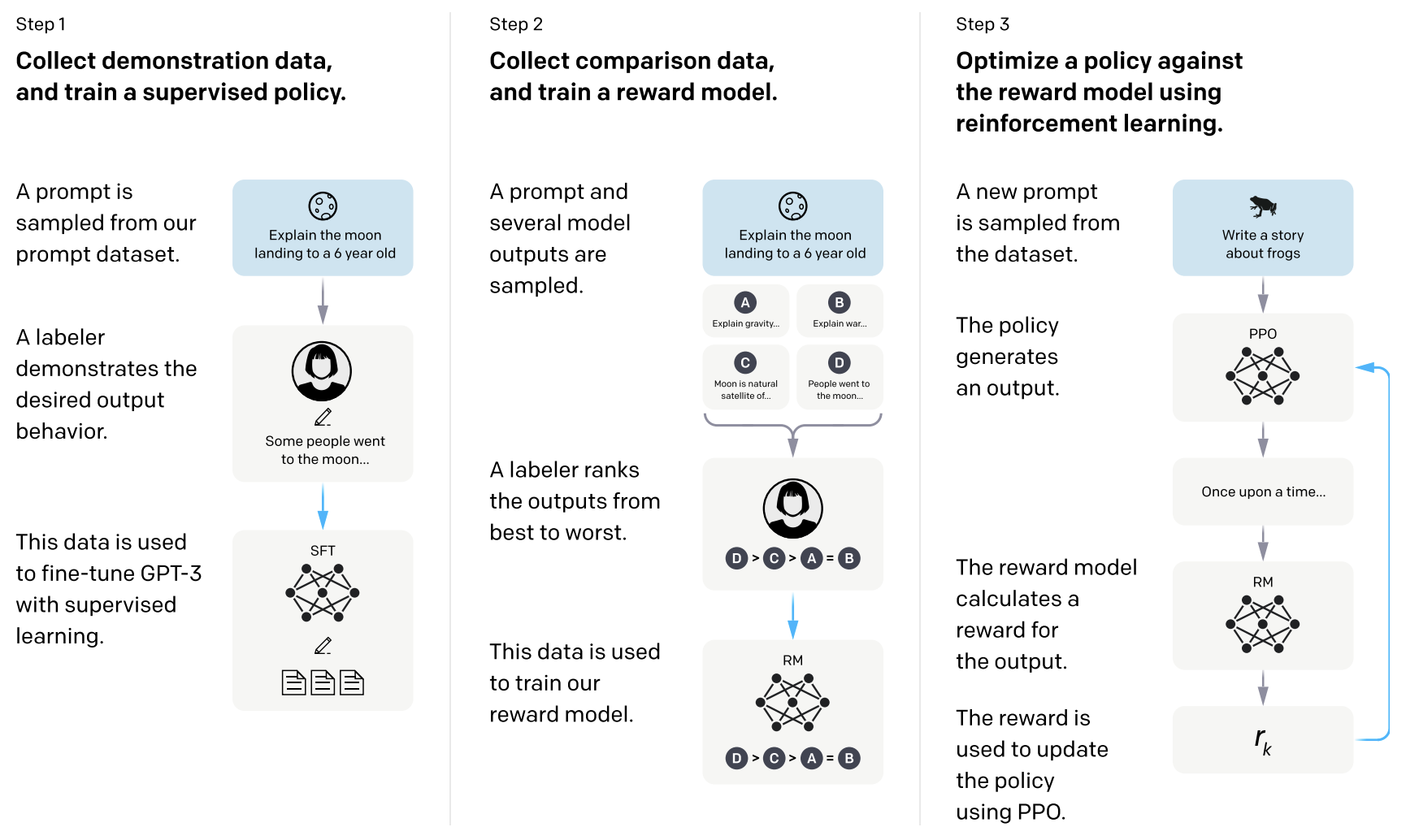
SFT(Step 1)
为了更好的让模型学习到如何进行对话反馈以及生成内容,首先从网上收集了一些用户使用过程中的提出的问题(human-written prompt),而后让人去为这些prompt problem标注答案即合适的回复(human written answer)。而后利用这些数据去对GPT3模型进行有监督的fine-tuning训练。在Fine-tuning的过程中同样采用自回归的方式,将Prompt和对应的label answer串联在一起进行训练(下一个词预测训练目标)。
SFT数据集只有1.3万个训练样本,训练16个epoch,这一步微调有利于最终InstructGPT向人类所需的对话回答对齐。如下图所示为一些Human-Written Prompt示例。

RM(Step 2)
此时SFT-GPT虽然学习到了对话以及与人类反馈交流的能力,但是无法更好地和人类行为进行对齐,例如怎样的回答是更符合人的行为(是人们所期望的回答)。因此进一步使用强化学习对模型进行调整。在进行强化学习训练之前首先训练一个奖励模型(Reward Model),该模型可以评估一个回答的好坏,而后用来辅助训练。
首先再次收集一批用户提问的Prompt(Human-Written Prompt)数据,而后将利用前面训练得到的SFT-GPT可以产生解码得到K个回答(Output),而后根据对应的Prompt以及K个回答结果进行排序(标注者根据回答的好坏进行打分),而后就可以利用这个标注数据集(Prompt+K个排序回答)去训练一个可以打分的Reward Model。
Reward Model的网络结构和GPT保持一致,有所区别的是将最后的SoftMax层改为线性层,从而将以前的下一个词预测变成得分预测(Scalar)。
在训练过程中,我们通过上面的标注得到数据集对[ d a t a s e t s = ( p r o m p t , [ a n s w e r 1 , a n s w e r 2 , . . . , a n s w e r k ] ) datasets = (prompt, [answer_1, answer_2, ..., answer_k]) datasets=(prompt,[answer1,answer2,...,answerk])],而后我们将prompt和每一个answer组合送进奖励模型 r θ r_{θ}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









