







 本文介绍了开源语言模型Llama2的发布,它经过大规模预训练和微调,性能超越公开模型,且在安全性方面有所增强。研究详细阐述了模型的训练技术,特别是RLHF微调方法,以及对模型性能和安全性的评估。
本文介绍了开源语言模型Llama2的发布,它经过大规模预训练和微调,性能超越公开模型,且在安全性方面有所增强。研究详细阐述了模型的训练技术,特别是RLHF微调方法,以及对模型性能和安全性的评估。
导语
Llama 2 是之前广受欢迎的开源大型语言模型 LLaMA 的新版本,该模型已公开发布,可用于研究和商业用途。本文记录了阅读该论文的一些关键笔记。
- 链接:https://arxiv.org/abs/2307.09288
1 引言
大型语言模型(LLMs)在多个领域表现出卓越的能力,尤其是在需要复杂推理和专业知识的任务中,例如编程和创意写作。LLMs通过直观的聊天界面与人类互动,导致了它们在公众中的快速普及。LLMs通常通过自回归式的Transformer在大量自监督数据上进行预训练,然后通过诸如人类反馈的强化学习(RLHF)等技术进行微调,使其更符合人类偏好。尽管训练方法相对简单,但高计算要求限制了LLMs的发展。已有公开发布的预训练LLMs在性能上可以与GPT-3和Chinchilla等闭源模型相媲美,但这些模型并不适合作为诸如ChatGPT、BARD、Claude这样的闭源“产品”LLMs的替代品。
本文开发并发布了Llama 2和Llama 2-Chat,以供研究和商业使用,这是一系列预训练和微调的LLMs,模型规模最大可达70亿参数。Llama 2-Chat在有用性和安全性方面的测试中普遍优于现有的开源模型,并且在人类评估中与一些闭源模型相当。本文还采取了提高模型安全性的措施,包括特定的数据注释和调整,红队测试,以及迭代评估。同时作者强调,虽然LLMs是一项新技术,可能带来潜在风险,但如果安全地进行,公开发布LLMs将对社会有益。作者提供了负责任使用指南和代码示例,以促进Llama 2和Llama 2-Chat的安全部署。
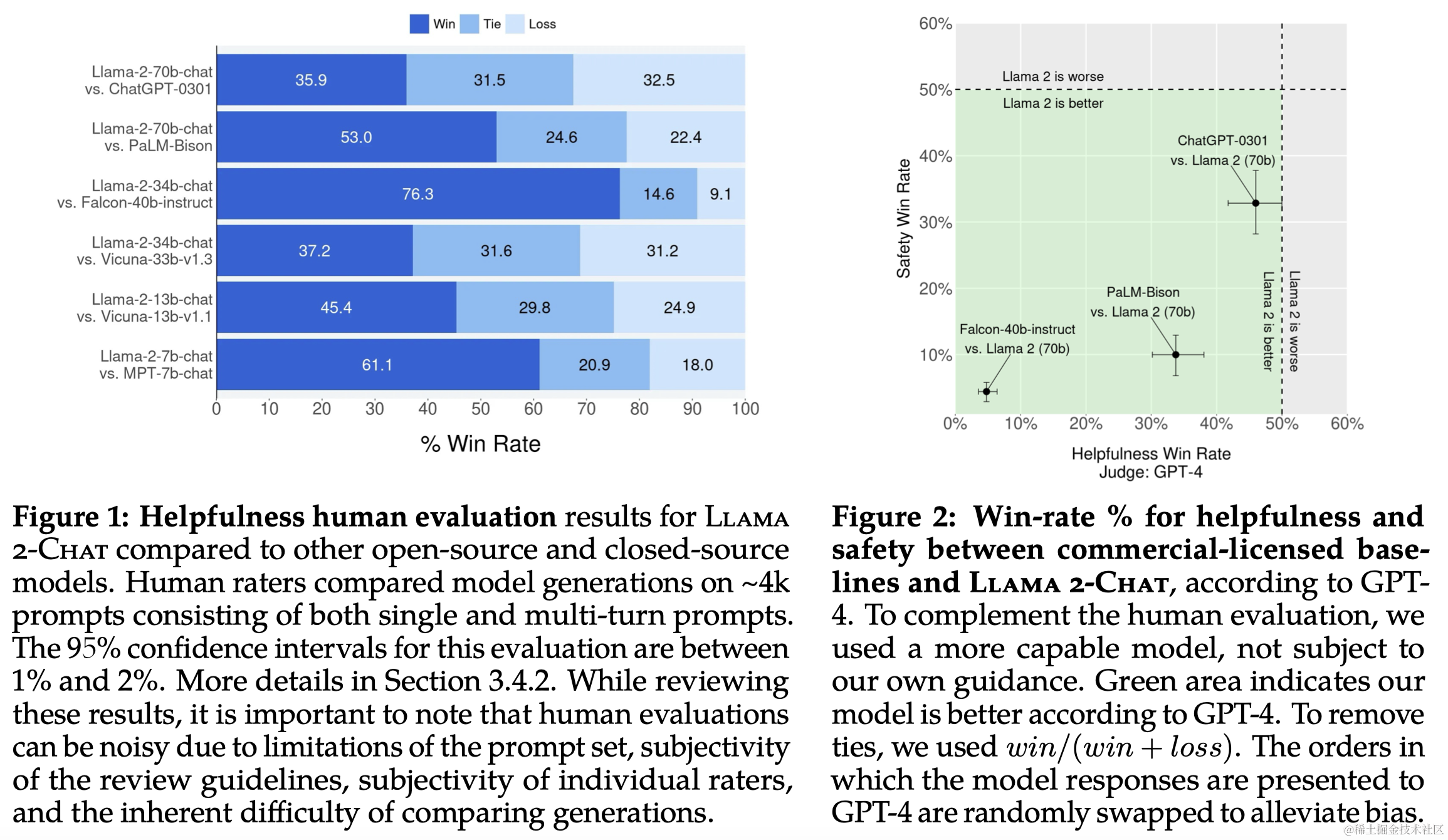
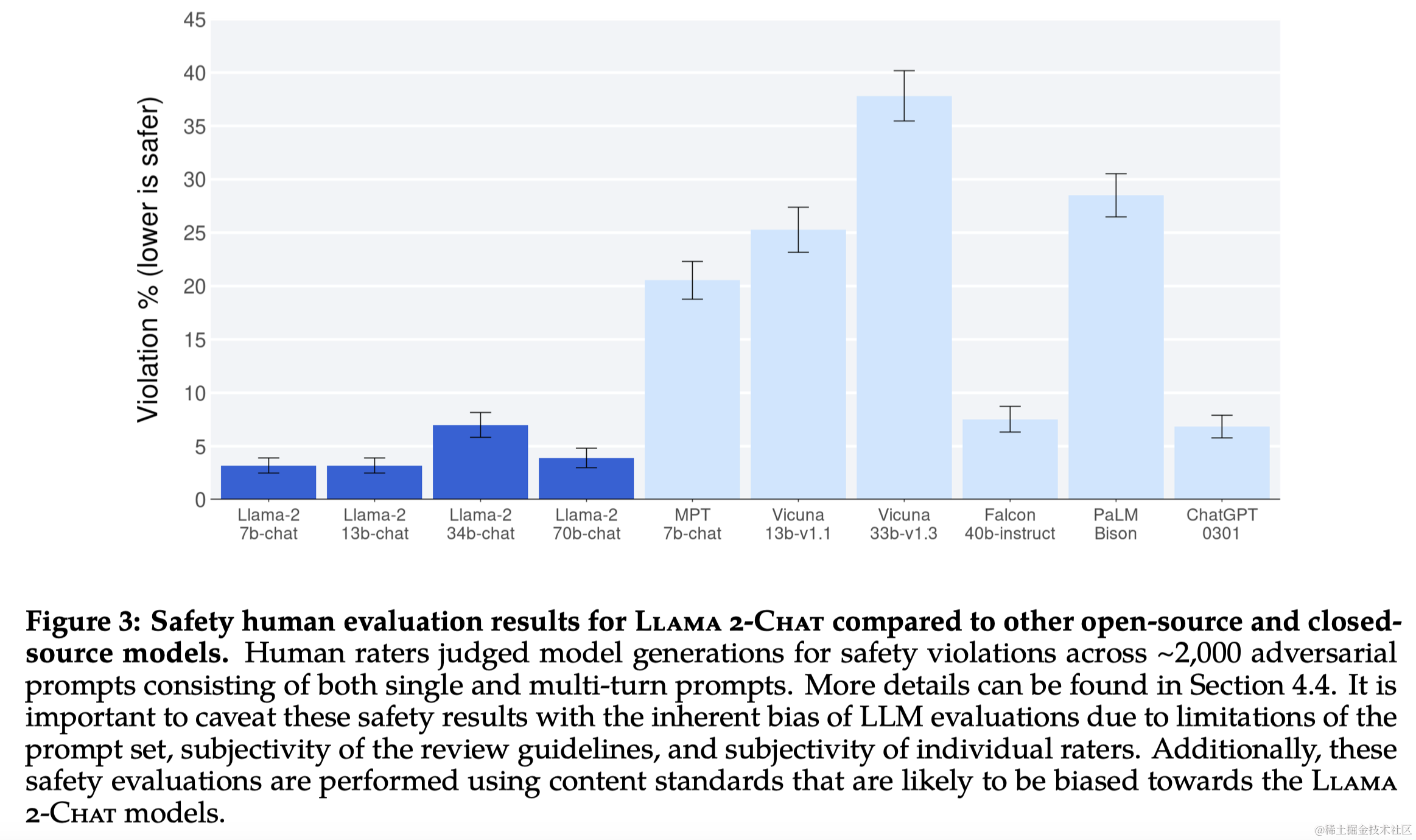
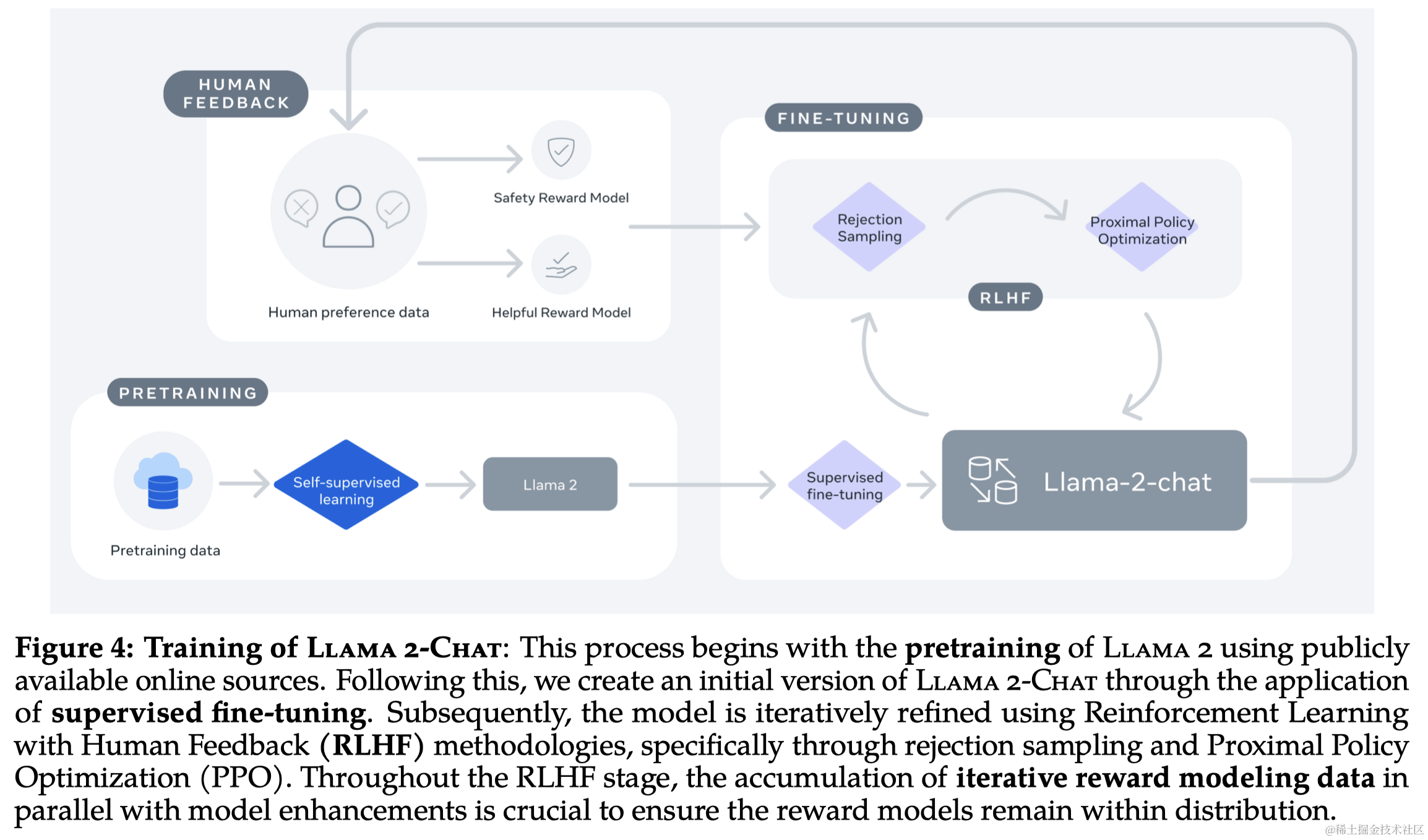
2 预训练
2.1 预训练数据
- 数据来源:训练数据来自公开可用的源,排除了来自 Meta 产品或服务的数据。
- 数据清洗:移除了已知包含大量个人信息的网站数据。
- 训练token数:训练了2万亿(2T)token的数据,以获得良好的性能和成本平衡。
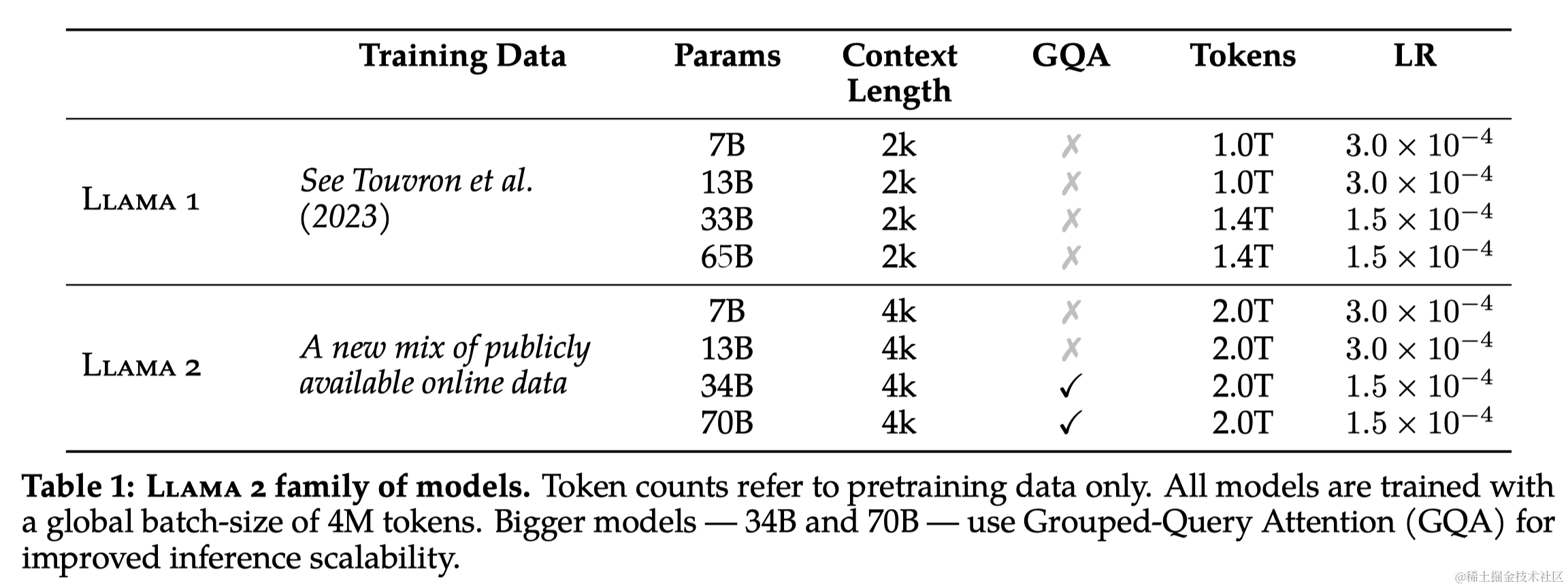
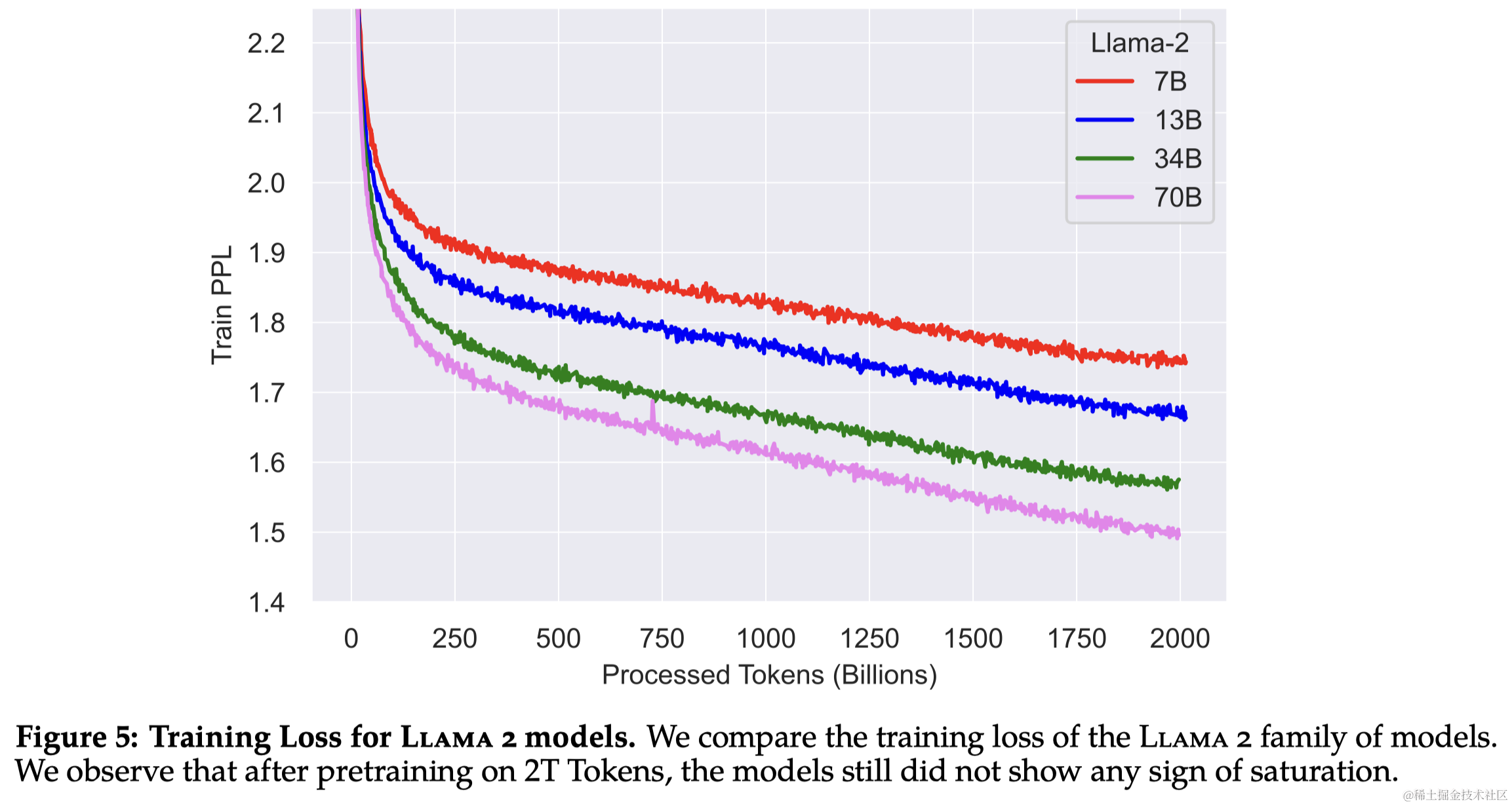
2.2 训练细节
- 使用标准Transformer架构
- 使用RMSNorm而不是原始的LayerNorm
- 使用SwiGLU激活函数
- 相对于LLaMA的2k上下文长度,LLaMA2增加到了4k上下文长度
- 使用了Grouped-Query Attention (GQA),而不是之前的MQA、MHA
- 使用了RoPE方式进行位置编码,使用旋转矩阵来编码位
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1774
1774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









