







系列文章目录
机器学习笔记——梯度下降、反向传播
机器学习笔记——用pytorch实现线性回归
机器学习笔记——pytorch实现逻辑斯蒂回归Logistic regression
机器学习笔记——多层线性(回归)模型 Multilevel (Linear Regression) Model
深度学习笔记——pytorch构造数据集 Dataset and Dataloader
深度学习笔记——pytorch解决多分类问题 Multi-Class Classification
深度学习笔记——pytorch实现卷积神经网络CNN
深度学习笔记——卷积神经网络CNN进阶
深度学习笔记——循环神经网络 RNN
深度学习笔记——pytorch实现GRU
文章目录
前言
参考视频——B站刘二大人《pytorch深度学习实践》
一、逻辑斯蒂回归
1.似然和极大似然估计
a.似然
在讲逻辑斯蒂回归前,必须懂得似然和极大似然估计。
我们常常可以根据事物的性质推出某种结果的概率,比如扔一枚硬币,正面和反面的概率都是百分之五十。
而似然性(Likelihood) 正好反过来,意思是一个事件实际已经发生了,反推在什么参数条件下,这个事件发生的概率最大。比如,在观察到投掷了一万次硬币都是正面向上,可以推出这枚硬币两面都是正面。似然就是根据结果判断事物的性质。
概率和似然可以看作是问题的两个不同的方向
概率是在已知模型参数的情况下预测结果
似然是在已知结果的情况下推断模型参数
数学公式表达:

P和L的值是相等的,即
L
(
β
∣
x
)
=
P
(
x
∣
β
)
\mathcal{L}(\beta| x)=P(x | \beta)
L(β∣x)=P(x∣β)。
b.极大似然估计
极大似然估计也叫最大似然估计,根据已知的样本观察数据,反推最具可能,或者最大概率导致这些样本结果出现的模型参数。
逻辑斯蒂回归属于二分类问题,即y只有两种取值y=1或y=0
公式为:
P
(
y
)
=
P
(
y
=
1
)
y
P
(
y
=
0
)
1
−
y
P(y)=P(y=1)^{y}P(y=0)^{1-y}
P(y)=P(y=1)yP(y=0)1−y
2.逻辑斯蒂回归Logistic regression
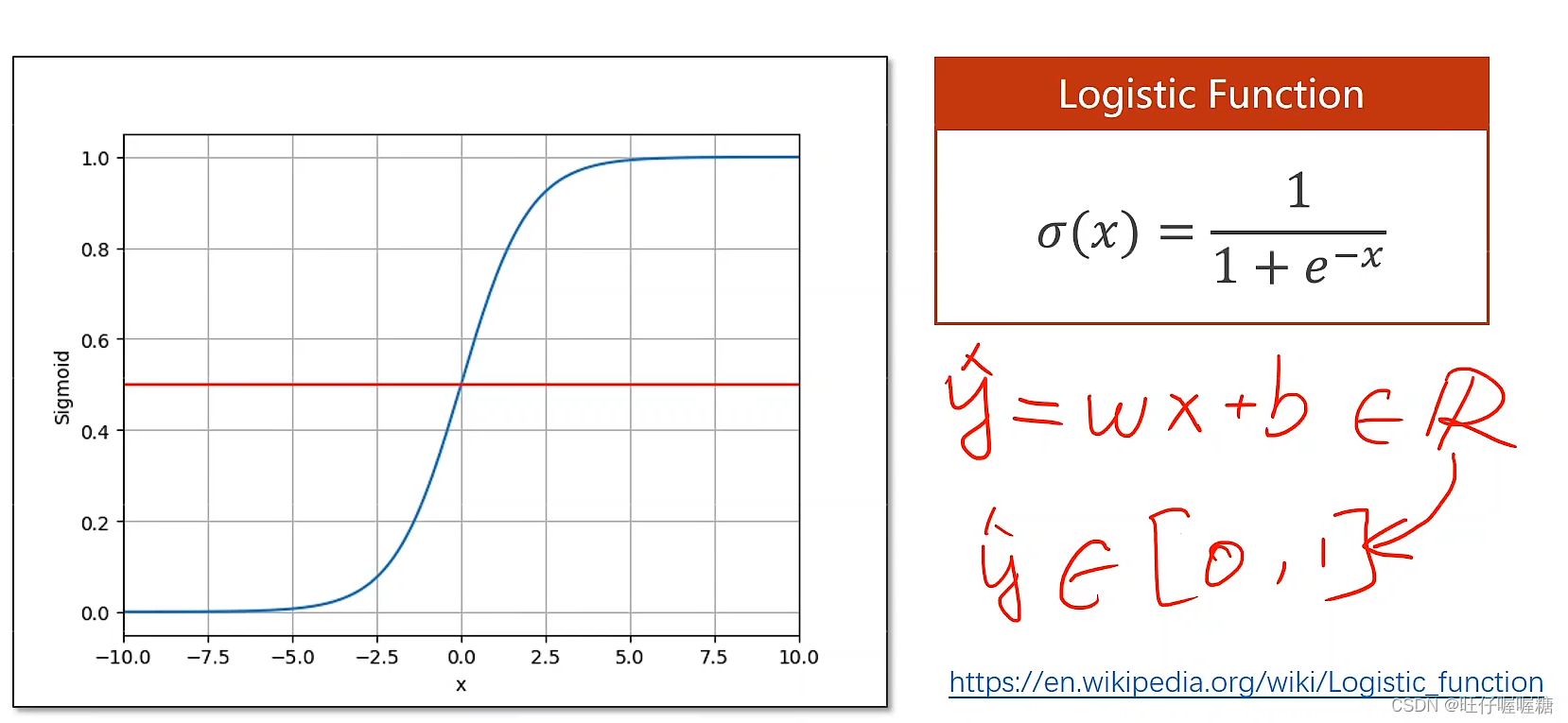
要将结果转为概率,就需要将实数域映射到[0,1]的区间上,于是使用了逻辑斯蒂函数。(逻辑斯蒂函数是sigmoid函数的一种)
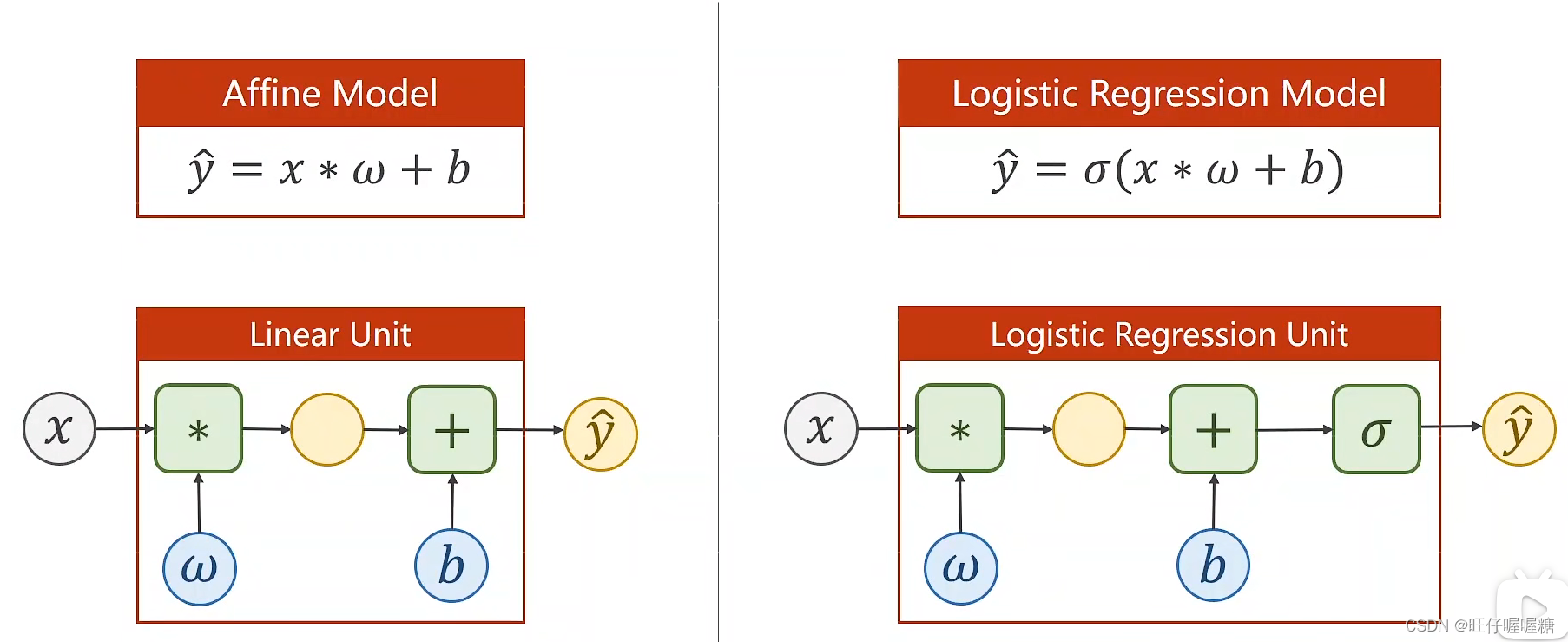
逻辑斯蒂模型,实际上就是在输出的y上加上一个逻辑斯蒂函数

P
(
y
)
=
P
(
y
=
1
)
y
P
(
y
=
0
)
1
−
y
P(y)=P(y=1)^{y}P(y=0)^{1-y}
P(y)=P(y=1)yP(y=0)1−y将极大似然的公式取对数,就将乘法转为了加法,便于运算。并再取负数,就得到了损失值。
为什么要取负,因为y_hat的值必然在0-1之间,所以log(y_hat)必然是小于0的。所以加个负号,且y_hat的值越大,loss的值越小,即loss越小越好。
模型改变之后,损失函数也要改变。因为线性模型中的损失值是两点之间的距离,而在分类问题中损失值应当是计算分布的差异。

注:图里的log其实是取的ln
二、代码及运行结果
1.pytorch自带数据集
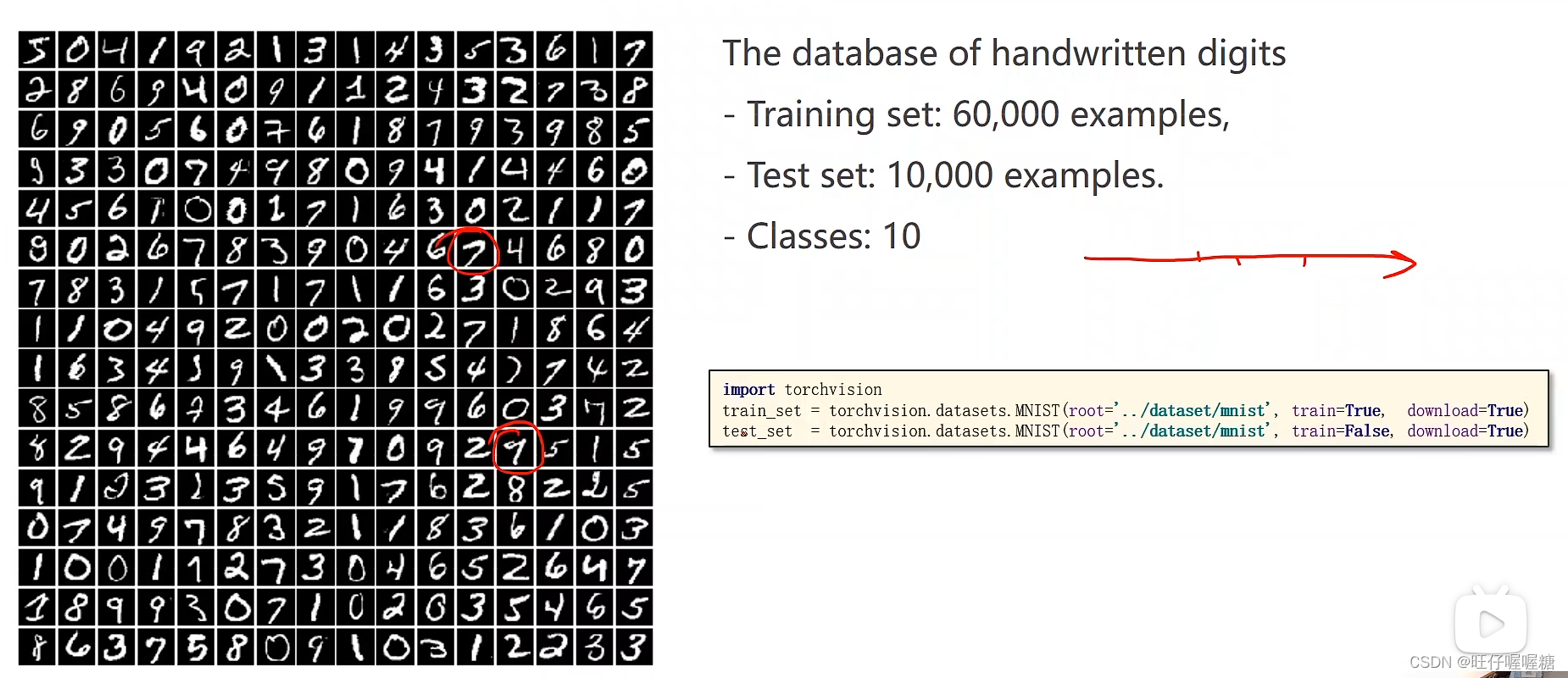
torch提供的minst数据集

torch提供的CIFAR10数据集
2.开发流程
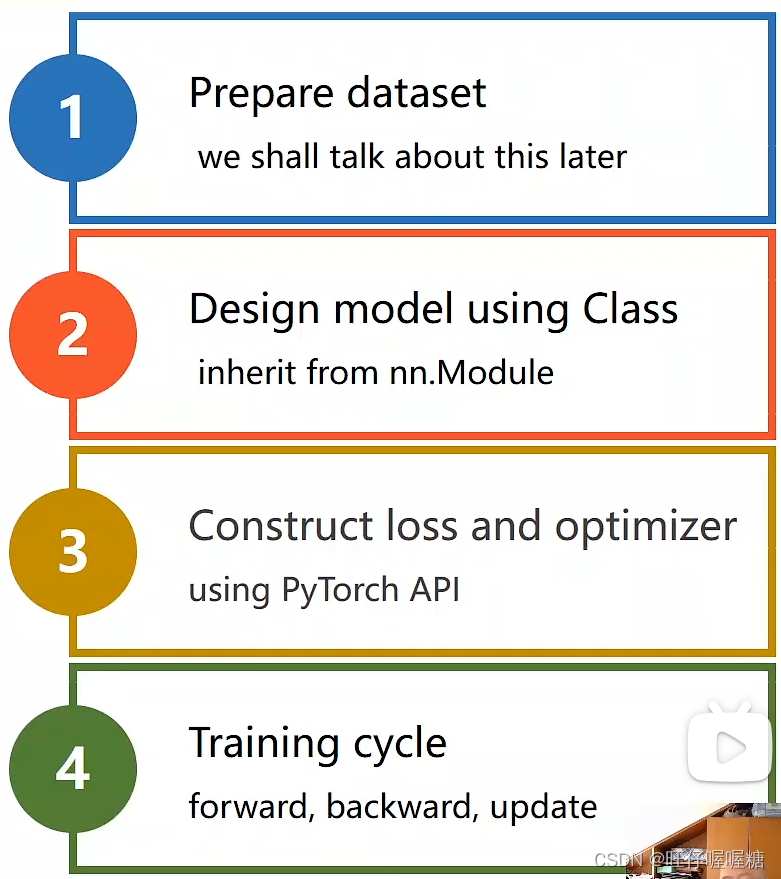
1.数据集准备
2.模型设计
3.损失值计算和优化器选择
4.训练
3.代码
#!/user/bin/env python3
# -*- coding: utf-8 -*-
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
# 模型
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__() # 继承父类的__init__方法
self.Linear = torch.nn.Linear(1, 1) # 创建线性模型
def forward(self, x):
y_pred = F.sigmoid(self.Linear(x)) # 将Linear算出的y_hat值传入sigmoid函数
return y_pred
# 训练集
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
# 测试集
x_test = torch.Tensor([[4]])
if __name__ == '__main__':
model = LogisticRegressionModel()
# 损失值和优化器
criterion = torch.nn.BCELoss(size_average=False) # 使用二分类交叉熵计算损失
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 优化器,学习率0.01
# 训练
for epoch in range(100):
y_pred = model(x_data) # 求出预测值y_hat
loss = criterion(y_pred, y_data) # 计算损失值
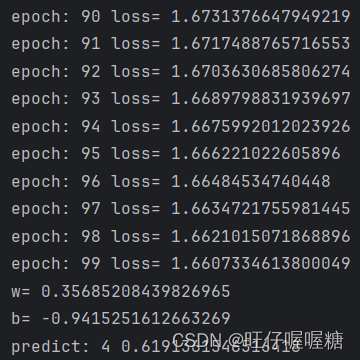
print('epoch:', epoch, 'loss=', loss.item()) # 输出
optimizer.zero_grad() # 梯度清零
loss.backward() # 通过损失值计算梯度
optimizer.step() # 根据损失值更新参数
# 输出参数
print('w=', model.Linear.weight.item())
print('b=', model.Linear.bias.item())
# 测试
print('predict:', 4, model(x_test).item())
# 绘图
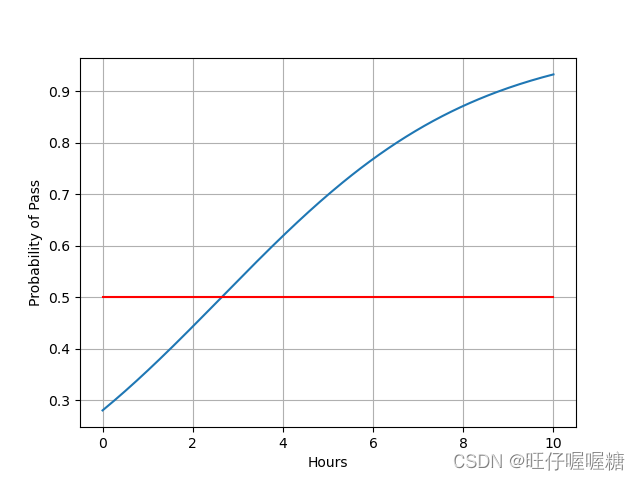
x = np.linspace(0, 10, 200)
x_t = torch.Tensor(x).view((200, 1))
y_t = model(x_t)
y = y_t.data.numpy()
plt.plot(x, y)
plt.plot([0, 10], [0.5, 0.5], c='r')
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
plt.grid()
plt.show()
结果:















 1408
1408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









