







系列文章目录
机器学习笔记——梯度下降、反向传播
机器学习笔记——用pytorch实现线性回归
机器学习笔记——pytorch实现逻辑斯蒂回归Logistic regression
机器学习笔记——多层线性(回归)模型 Multilevel (Linear Regression) Model
深度学习笔记——pytorch构造数据集 Dataset and Dataloader
深度学习笔记——pytorch解决多分类问题 Multi-Class Classification
深度学习笔记——pytorch实现卷积神经网络CNN
深度学习笔记——卷积神经网络CNN进阶
深度学习笔记——循环神经网络 RNN
深度学习笔记——pytorch实现GRU
前言
一、多分类问题 Multi-Class Classification
1.多分类模型结构
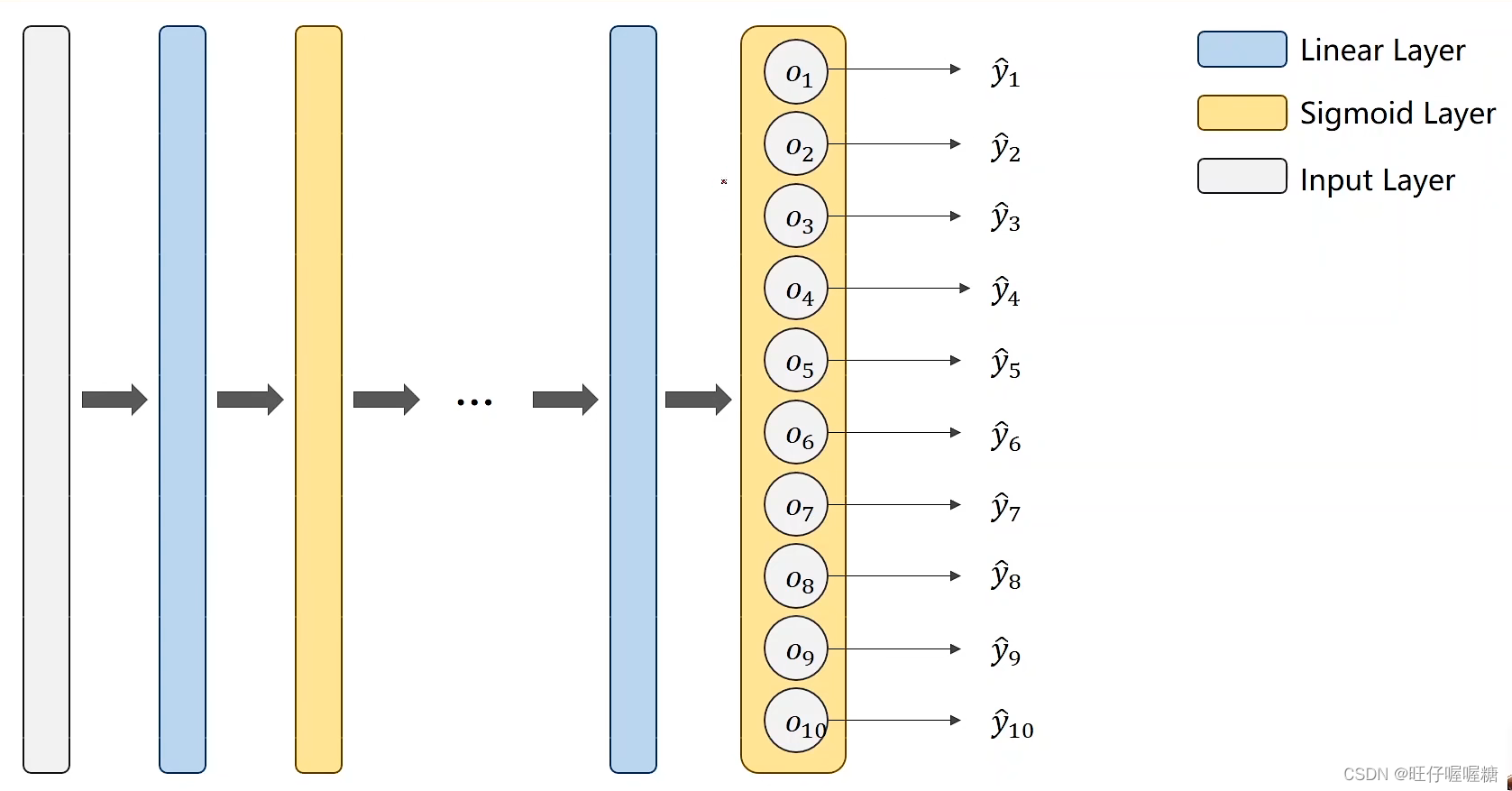
模型结构图,以mnist数据集为例,通过多层的计算,最后输出10个值。即该数为1的概率、为2的概率、为3的概率…

所以最后的输出应该是一个分布,满足yi>0且y1+y2+y3+…+y10=1,即所有可能都大于零且所有可能之和等于1.

将最后一层的激活函数换成softmax分类器,softmax能够输出一个分布。

softmax计算公式

例子:假设输出0.2、0.1、-0.1三个数,将三个数进行e的指数运算,得到1.22、1.11、0.90,三个数之和为3.23,最后的分布为0.38、0.34、0.28.所以0.2的概率最大。
2.交叉熵损失函数

3.数据集

mnist数据集是手写数字识别,共有十个分类,即0、1、2、3、4、5、6、7、8、9。

输入的图像是长和宽都为28个像素的图像,用矩阵表示如图。

在python的PIL中,图像的像素值在0-255之间,我们要把其转换为一个张量,像素值在0-1之间
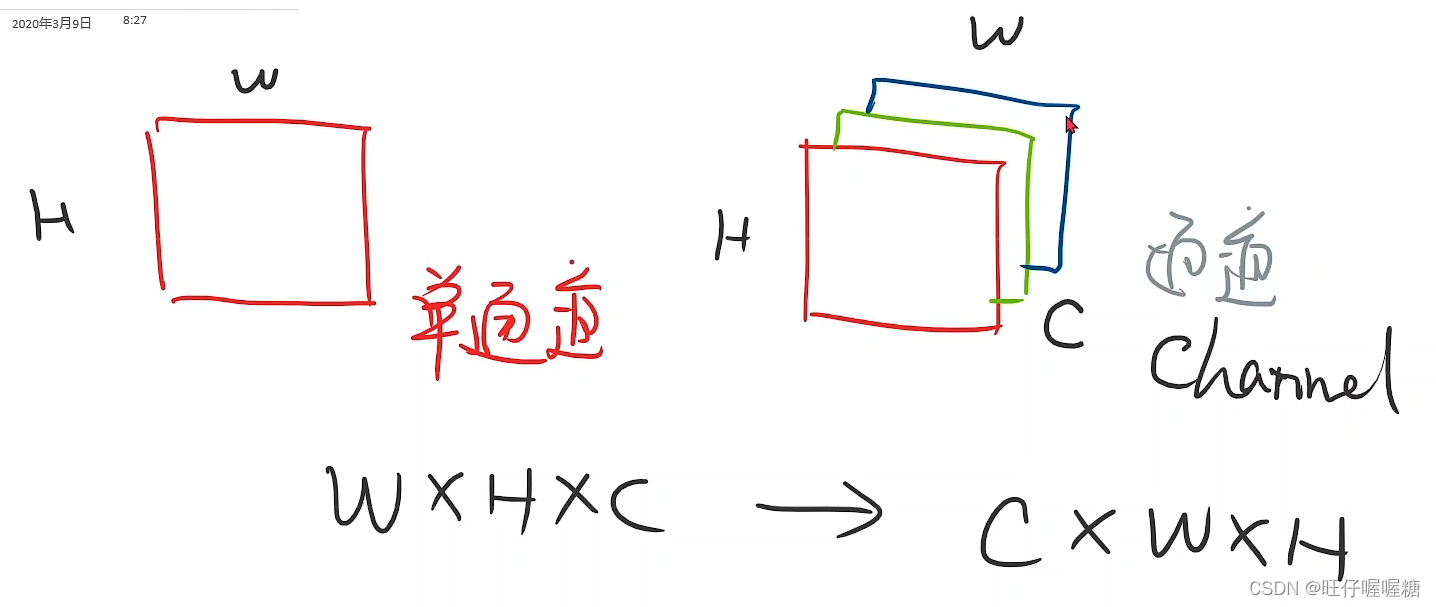
在通常的图像处理包下,图像是宽✖高✖通道,而pytorch为了更好的计算,需要转换为通道✖宽✖高的形式。
二、代码
1.代码
#!/user/bin/env python3
# -*- coding: utf-8 -*-
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
# 数据集
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(), # 图像转为张量
transforms.Normalize((0.1307,), (0.3081,)) # 根据均值和标准差,进行归一化处理
])
# 训练集
train_dataset = datasets.MNIST(root=r'learn_torch/mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
# 测试集
test_dataset = datasets.MNIST(root=r'learn_torch/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.linear1 = torch.nn.Linear(784, 512)
self.linear2 = torch.nn.Linear(512, 256)
self.linear3 = torch.nn.Linear(256, 128)
self.linear4 = torch.nn.Linear(128, 64)
self.linear5 = torch.nn.Linear(64, 10)
self.activate = torch.nn.ReLU()
def forward(self, x):
x = x.view(-1, 784) # 改变张量的形状,将(64,1,28,28)的数据变成(64,784)的数据,-1其实就是自动获取mini_batch,
x = self.activate(self.linear1(x))
x = self.activate(self.linear2(x))
x = self.activate(self.linear3(x))
x = self.activate(self.linear4(x))
return self.linear5(x)
# 模型实例化
model = Net()
# 损失函数
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失
# 优化器
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# 训练
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, targets = data
# forward
outputs = model(inputs)
loss = criterion(outputs, targets)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 输出
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d,%5d] loss:%.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
# 测试
def model_test():
correct = 0 # 正确数据
total = 0 # 全部数据
with torch.no_grad(): # 不需要计算梯度
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set:%d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
model_test()
2.运行结果
开始训练: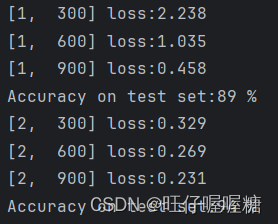
十轮训练之后:
















 1236
1236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









