







文章目录
一、目录操作
1.1、目录操作函数与目录句柄操作函数
(1)、目录操作函数:
- mkdir——创建目录;
- rmdir——删除目录;
- chdir——改变当前工作目录;
rmdir "a"; #删除文件夹(必须是空文件夹)
mkdir "b";
mkdir "c"; #创建文件夹
chdir "b"; #改变文件夹,相当于相对路经起点变为了\Users\zhais\Documents\Perl学习\b>
mkdir "d"; #改变文件夹后,在b中创建了d文件夹
上述三个目录操作函数,同样属于Windows系统的操作命令,可以在Windows系统的终端命令行(cmd打开)进行直接操作。
(2)、目录句柄操作函数:
若想从目录里获取文件列表,可以使用目录句柄。目录句柄与文件句柄差别不大,下面是操作目录句柄的三个函数。
- opendir——打开目录句柄,类似关键字open;
- readdir——读取目录句柄中的内容(目录中的文件名),类似关键字readline;
- closedir——关闭目录句柄,类似关键字close;
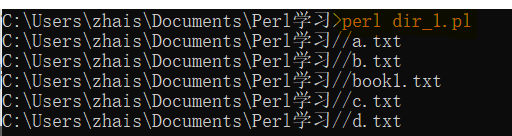
$dir_to_process = "C:\\Users\\zhais\\Documents\\Perl学习"; #双反斜杠——转义斜杠
opendir DH, $dir_to_process or die "Cannot open $dir_to_process: $!"; #DH为目录句柄,$!为默认标量变量的值,发生错误时,自动打印结果
foreach $file (readdir DH){ #readdir关键字读取目录句柄中的所有目录
next if $file eq "." or $file eq ".."; #过滤掉隐藏目录(.|..)
next if -d $file; #过滤掉文件夹
next unless $file =~ /\.txt$/; #过滤掉非txt文件(条件为假时,即不以.txt结尾的文件时,才执行next,进入下一轮循环)
my $fullname = "$dir_to_process//$file"; #显示全路径名
#print "$file\n"; #只显示文件名
print "$fullname\n"; #显示全路径文件名
}
closedir DH;
编译运行:
1.2、文件操作
1.2.1、文件名通配(glob与尖括号)
- glob操作符或者尖括号< >实现通配;
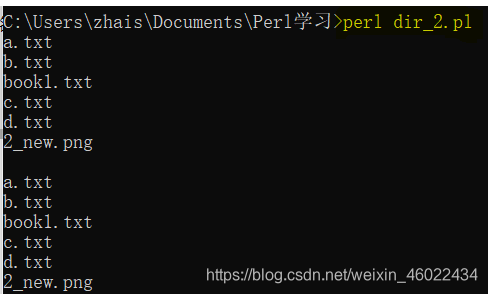
#glob新的写法——glob实现通配操作
my @files = glob "*.txt *.png"; #文件名通配,将结果放于数组中
foreach(@files){
print "$_\n";
}
print "\n";
#旧写法——尖括号实现通配
my @files = <*.txt *.png>; #文件名通配,将结果放于数组中
foreach(@files){
print "$_\n";
}
1.2.2、删除文件(unlink)
- Perl中,可以通过unlink操作符指定要删除的文件列表;不能删除目录(区别于rmdir)。
unlink "1.png"; #单独删除文件
unlink qw/slate bedrock lava/; #删除文件列表
my $success = unlink "2.jpg","4.jpg","5.jpg"; #批量多个文件,返回删除结果
print "I deleted $success files just now!\n";
unlink glob "*.jpg"; #使用glob统配,删除批量所有的同一类型文件
foreach my $file(glob "*.txt"){
unlink $file or warn "failed on $file\n"; #逐一删除,检查是否删除失败
}
1.2.3、重命名文件/移动文件(rename)
- **rename关键字用于文件的重命名,也可将文件移动到其它目录中**。
rename "2.png", "2_new.png"; #重命名,第一个参数为旧名字,第二个参数为新名字
rename "3.png", "c/3.png"; #移动功能,第一个参数为要移动的文件,第二个参数为移动后文件(一般移动过程中,不改变文件的名字)
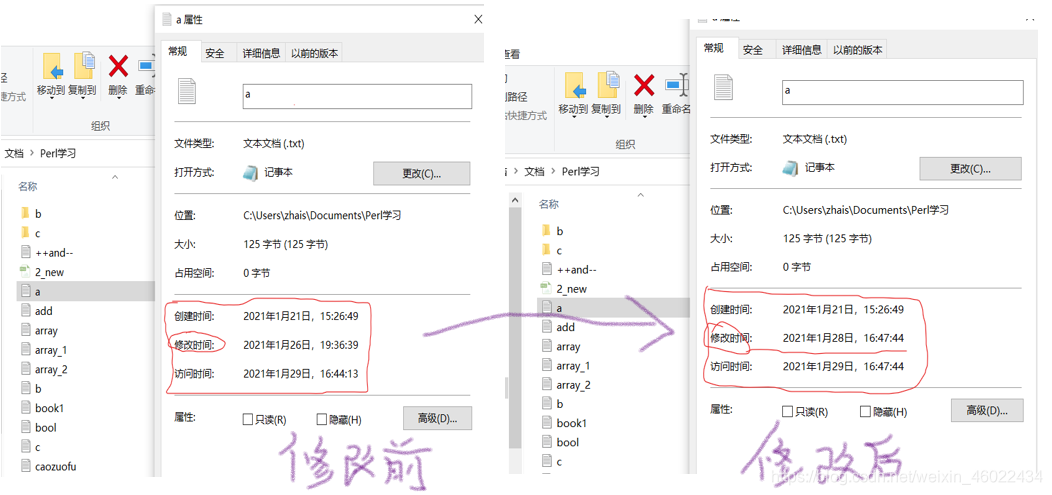
1.3、修改时间戳(utime函数)
- 当需要修改某个文件最近的更改时间或访问时间以期满其它程序,可以使用utime函数来造假。
- utime函数的前两个时间是新的访问时间和更改时间,其余参数是要修改的时间戳的文件列表名;
my $now = time;
my $yesterday = $now - 24*60*60; #减去一天的秒数
#print "$now\n"; #打印一串数字
#print "$yesterday\n"; #打印一串数字
utime $now,$yesterday, glob "*.txt"; #修改文件的时间 (所有的txt文件)
二、字符串及排序
2.1、字符串函数
2.1.1、index与rindex函数(查找子字符串位置)
index函数的查找,返回的字符位置从0开始计。如果无法找到子串,则返回-1。index函数每次都会返回首次出现子字符串的位置,同时还可以加上第三个参数来指定开始搜索的位置。
rindex函数的查找,从字符串的右侧开始查找,返回的字符位置任然从左侧由0开始计数。
#字符串函数运用
my $stuff = "howdy world";
my $where = index($stuff, "wor"); #index_查找字符串的位置(从第0个开始记)
print "$where\n"; #打印:6
my $where1 = index($stuff, "w"); #查找到第一个w即停止
print "$where1\n"; #打印:2
my $where2 = index($stuff, "w", $where1+1); #第三个参数指定查找的起始位置
print "$where2\n"; #打印:6
my $where3 = index($stuff, "w", $where2+1); #查找第三个w
print "$where3\n"; #打印:-1, 表示找不到,没有了
#上述操作——可以通过循环操作实现
my $last_slash = rindex("/etc/passwd", "/"); #rindex_从右侧开始找,计数从左侧开始(从0开始)
print "$last_slash\n"; #打印:4
my $name = "abc/123/xyz/hello";
$where = rindex($name, "/"); #从右侧开始找第一个斜杠
print "$where\n"; #打印:11
$where1 = rindex($name, "/", $where-1); #第二个参数表示起始查找位置
print "$where1\n"; #打印:7
$where2 = rindex($name, "/", $where1-1); #第二个参数表示起始查找位置
print "$where2\n"; #打印:3
2.1.2、substr函数(提取/替换子字符串)
substr函数用来处理较长字符串中的一小段内容,返回截取的子字符串;
substr函数包含三个参数:第一个为原始字符串,第二个为**从0开始计**的起始位置,第三个为子字符串的长度(可省略);
#提取子字符串
my $a = substr("Fred J. Flintstone", 8 ,5); #第一参数为给定的字符串,第二个参数为起始位,第三个参数为截取长度
print "$a\n"; #打印:Flint
my $b = substr("Fred J. Flintstone", 13 ,100); #第三个参数超出界限,那就取剩余的所有,也可以省略第三个参数
print "$b\n"; #打印:stone
my $c = substr("Fred J. Flintstone", 13); #可以省略第三个参数,取剩余的所有字符
print "$c\n"; #打印:stone
my $out = substr("some very long string", -3, 2); #负数表示从后边开始取
print "$out\n"; #打印:in
#substr与index搭配使用,截取字符串
my $long = "some very long string";
my $right = substr($long, index($long, "l"));
print "$right\n"; #打印:long string
substr函数除了直接返回截取子字符串外,还可以实现字符串的替换功能。
#substr替换
my $string = "Hello world";
substr($string,0,5) = "Goodbye";
print "$string\n"; #打印:Goodbye world
$string = "aaaaadddddddsssssssssssfred.....,fred...fred.";
substr($string, -20) =~ s/fred/barney/g ; #在后20个字符范围内进行替换
print "$string\n"; #打印:aaaaadddddddsssssssssssfred.....,barney...barney.
#传统写法——上述代码
my $string = "Hello world";
substr($string,0,5,"Goodbye");
#$previous_value = substr($string,0,5,"Goodbye"); #$previous_value变量无用,一般忽略
print "$string\n"; #打印:Goodbye world
#print "$previous_value\n";
2.1.3、sprintf函数(返回字符串,但不会打印)
sprintf函数与printf函数有相同的参数,但是区别在于sprintf函数返回的是所请求的字符串,不会直接打印出来。sprintf函数可以将格式化后的字符串存放在变量里以便稍后使用。
格式化定义数字字段的前置零(%02d)表示必要时,在数字前补0以符合指定的宽度要求。
#sprintf函数使用——将格式化后的字符串保存到变量里
my $now = localtime;
print "$now\n"; #打印:Sun Jan 31 17:21:09 2021
my($sec,$min,$hour,$day,$mon,$year,$wday,$yday,$isdst) = localtime;
my $now = ($year+1900)."/".($mon+1)."/".$day." ".$hour.":".$min.":".$sec."\n";
print "$now\n"; #打印:2021/1/31 17:21:9
my $now = sprintf("%4d/%02d/%02d %02d:%02d:%02d",$year+1900,$mon+1,$day,$hour,$min,$sec); #%02d_宽度为2位,如果只有1位数,则加上0
print "$now\n"; #打印:2021/01/31 17:21:09
printf "%4d/%02d/%02d %02d:%02d:%02d",$year+1900,$mon+1,$day,$hour,$min,$sec; #打印:2021/01/31 17:21:09
2.2、排序
在第四章提到,Perl内置的sort排序操作符,是以ASCII码序对列表进行排序。但是涉及到数字大小或者不区分大小写的排序,单一的sort操作符难以实现。
#排序
my @rocks = qw/bedrocks slate rubble granite/;
my @sorted = sort(@rocks); #按照ASCII码值大小进行排序
print "@sorted\n"; #打印:bedrocks granite rubble slate
my @numbers = (20,2,1,10);
my @result = sort @numbers; #按照ASCII码值大小进行排序
print "@result\n"; #打印结果:1 10 2 20 (按照首位:1,1,2,2排序)
2.2.1、按数字大小或不分大小写排序(<=>, cmp)
但是,我们可以建立自己的“ 排序子程序 ”,加以实现按数字大小或者不区分大小写的排序。
下列排序子程序中,my($a, $b) = @_代码是Perl默认执行的操作,变量 $a与 $b会被Perl自动赋值。
在实际的大小值排序过程中会用到飞船操作符<=>,与此对应用来比骄傲字符串的操作符为:cmp
##############################上述代码的具体实现###############################
sub by_number{ #排序子程序
#my($a, $b) = @_; #Perl默认执行的操作
#if($a > $b){ 1 }elsif($a < $b){ -1 }else{ 0 };
$a <=> $b; #飞船操作符
}
my @result = sort by_number @numbers;
print "@result\n"; #打印结果:1 2 10 20 (正确排序)
实际大小顺序或不分大小写的排序代码:
my @result = sort { $a<=>$b } @numbers;
print "@result\n"; #打印结果:1 2 10 20 (正确排序)
#my @result = sort {lc($a) cmp lc($b)} qw(Cat big apple Dog cat cab); #lc函数,转换小写
my @result = sort {"\L$a" cmp "\L$b"} qw(Cat big apple Dog cat cab); #比较时,全部转换为\L小写字母进行比较
print "@result\n"; #打印结果:apple big cab Cat cat Dog
2.2.1、 哈希排序(键排序、值排序)
- 键排序: sort keys %elems;
- 值排序: sort { $elems{$a} <=> $elems{$b}} keys %elems;
- 多个值排序:sort {
$score{$b} <=> $score{$a} or #先按值排序,(or具有短路功能)
$a cmp $b #当分数相同,返回0,再按名字排序
} keys %score;
#哈希排序
my %elems = (B => 5, Be => 4, H => 1, He => 2, Li => 3);
my @result = sort keys %elems;
print "@result\n"; #打印结果:B Be H He Li(键排序)
my %elems = (B => 5, Be => 4, H => 1, He => 2, Li => 3);
#sub by_value{ $elems{$a} <=> $elems{$b}};
my @result = sort { $elems{$a} <=> $elems{$b}} keys %elems;
print "@result\n"; #打印结果:H He Li Be B(值排序)
my %score = ("barney" => 195, "fred" => 205, "dino" => 35 );
my @result = sort { $score{$b} <=> $score{$a}} keys %score; #由大到小排序
print "@result\n"; #打印结果:fred barney dino(值排序)
#如果有分数一样的,按名字排序
my %score = ("barney" => 195, "fred" => 205, "dino" => 35, "banma" => 195 );
my @result = sort {
$score{$b} <=> $score{$a} or #先按值排序,(or具有短路功能)
$a cmp $b #当分数相同,返回0,再按名字排序
} keys %score; #由大到小排序
print "@result\n"; #打印结果:fred banma barney dino(值排序)















 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











