






大模型技术的风险与挑战
尽管以ChatGPT为代表的大模型技术取得关键性突破,但当前大模型技术仍存在诸多风险与挑战。
首先,大模型的可靠性无法得到有效保障。例如:基于海量数据训练的语言大模型,尽管其生成的内容符合语言规则、通顺流畅且与人类偏好对齐,但其合成内容在事实性、时效性方面等仍存在较多问题,上无法对所合成内容做出可靠评估。
其次,大模型的可解释性存在不足。大模型基于深度神经网络,为黑盒模型,其工作机理仍难以理解。语言大模型的涌现能力、规模定律,多模态大模型的知识表示、逻辑推理能力、泛化能力、情景学习能力等方面有待展开深入研究,为大模型的大规模实际应用提供理论保障。
再次,大模型应用部署代价高。大模型参数规模和数据规模都非常巨大,存在训练和推理计算量大、功耗高、应用成本高、端侧推理[1]存在延迟等问题,从而限制了其落地应用。提高推理速度降低大模型使用成本是大规模应用的关键。
此外:,大模型在小数据情景下的迁移能力存在不足。大模型基于数据驱动深度学习方式,依赖训练数据所覆盖的场景,由于复杂场景数据不足,大模型存在特定场景适用性不足的问题,面临鲁棒性和泛化性等挑战。提升大模型对小数据的高效适配迁移能力是未来研究的重点。
最后,大模型还存在伴生技术风险问题。例如,语言大模型具有通用的自然语言理解和生成能力,其与语言合成、图像视频生成等技术结合可以产生人类难以辨别的音视频等逼真多媒体内容,可能会被滥用于制造虚假信息、恶意引导行为,诱发舆论攻击、甚至危害国家安全。此外,大模型存在安全与隐私问题,目前针对大模型安全漏洞的典型攻击方式包括:数据投毒攻击、对抗样本攻击、模型窃取攻击、后门攻击、指令攻击。大模型的安全漏洞可能被攻击者利用,使用大模型关联业务面临整体失效的风险,威胁以其为基础构建的应用生态。大模型利用海量的互联网数据进行训练,包括个人、企业甚至国家的敏感数据可能被编码进大数据参数中,因而存在数据隐私问题。例如,通过提示信息可能诱发大模型隐私数据泄露问题。
[1]:端侧推理是指在边缘设备(如智能手机、嵌入式系统等)上进行模型推理的
过程。这种技术使得计算和数据处理功能从数据中心下沉到终端设备上,实现实
时推理和隐私保护,提高系统性能和可靠性。
**实时性:**由于推理计算直接在终端设备上进行,因此能够显著降低网络延迟,满足实时性要求。
**隐私性:**数据无需传输到云端进行处理,有助于保护用户隐私和数据安全。
**高效性:**在终端设备上进行推理计算,可以减少数据传输带宽的占用,提高系统整体效率。
Transformer架构
目前语言大模型采用的主流架构,基于自注意力机制[2]模型。
[2]:Transformer自注意力机制是一种在Transformer架构中使用的核心机制,用
于捕捉输入序列中不同位置之间的依赖关系。对于输入序列中的每个位置,
Transformer会生成三个向量:查询向量(Q)、键向量(K)和值向量(V)。
这些向量是通过将输入数据(如词嵌入)乘以可学习的权重矩阵得到的。
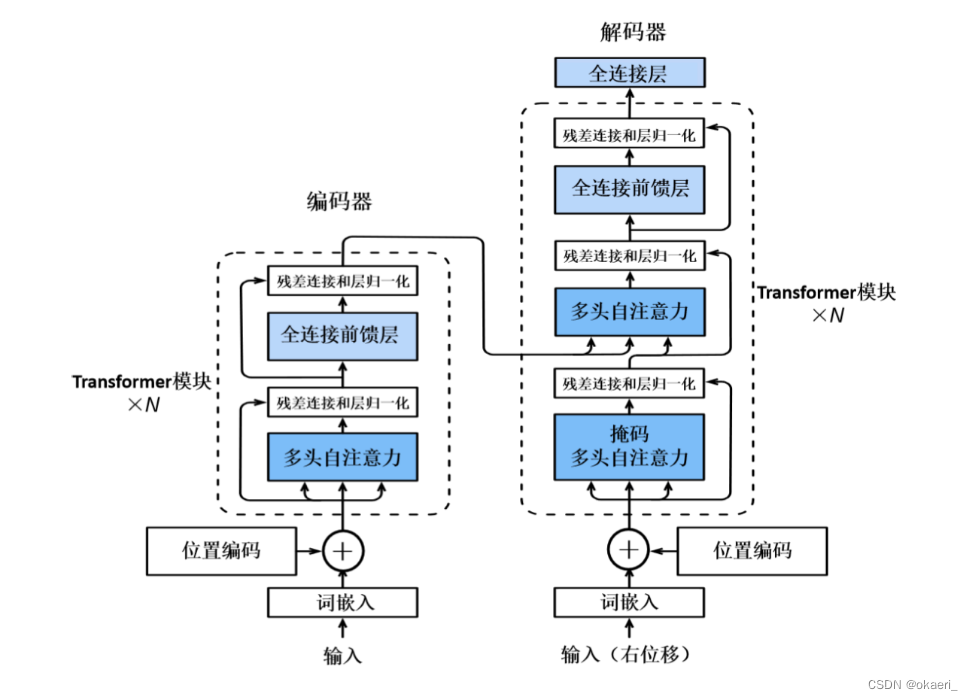
主要思想:通过自注意力机制获取输入序列的全局信息,并将这些信息通过网络层进行传递。标准的Transformer是一个编码器-解码器架构,其编码器和解码器均由一个编码层和若干相同的Transformer模块层堆叠组成,编码器的Transformer模块层包括多头注意力层和全连接前馈网络层,这两部分通过残差连接和层归一化操作连接起来。解码器需要考虑解码器输出作为背景信息进行生成,其中每个Transformer层多了一个交叉注意力层。
相比于传统循环神经网络(RNN)和长短时记忆神经网络(LSTM),Transformer架构的优势在于它的并行计算能力,即不需要按照时间步顺序地进行计算。
编码层:主要将输入词序列映射到连续值向量空间进行编码,每个词编码由词嵌入和位置编码构成。
词嵌入:数据的第一步处理过程,将词映射到高维空间中的向量,可以捕获词汇的语义信息,比如词义和语法关系。每个词都被转化为一个固定长度的向量,然后被送入模型进行处理。
位置编码:由于自注意力机制本身对位置信息不敏感,为了让模型能够理解序列中的顺序信息,引入了位置编码。标准Transformer架构的位置编码方式是使用正弦和余弦函数的方法。对于每个位置i,对应的位置编码是一个长度为d的向量,其中d是模型的嵌入维度。
掩码语言架构:基于Transformer 编码器 的双向模型,其中BERT[3]和RoBERTa[4]是其中典型代表。这类模型通过掩码语言建模任务进行预训练,BERT中还加入了下一句预测任务。
[3]:BERT是一种基于Transformer架构的预训练语言模型,它通过掩码语言模型
和下一句预测两个任务进行预训练,能够捕获丰富的语言表示,并在各种NLP任
务中取得显著的性能提升。
[4]:RoBERTa是BERT的改进版,通过增加训练数据量、优化数据预处理、采用动
态遮蔽策略以及移除下一句预测任务等优化方法,进一步提升了模型的性能。它
在NLP领域的应用广泛,并在多个任务上取得了显著的性能提升。
自回归语言建模:在训练时通过学习预测序列中的下一个词来建模语言,主要通过Transformer 解码器 来实现。优化目标为最大化对序列中每个位置的下一个词的条件概率的预测。更适合用于生成任务,以及对模型进行规模扩增。
序列到序列建模:建立在完整Transformer架构上,即同时使用编码器-解码器结构。
知识运用和推理能力是衡量语言大模型智能水平的重要因素
语言大模型技术主要包括模型预训练、适配微调、提示学习、知识增强和工具学习等。
预训练:高性能训练工具、高效预训练策略、高质量训练数据、高质量训练数据、高效的模型架构。
适配微调:指令微调(指令理解、指令数据获取、指令对齐)、参数高效微调。
提示学习:指令提示【少样本提示,零样本提示、上下文学习(也叫情境学习,将自然语言问题作为语言大模型的输入,并将其答案作为输出。可以看作一种特殊的少样本提示)】、思维链。
知识增强:知识增广、知识支撑、知识约束、知识迁移。















 58
58

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









