






论文题目:Saliency as Evidence: Event Detection with Trigger Saliency Attribution
论文:https://aclanthology.org/2022.acl-long.313.pdf
代码:https://github.com/jianliu-ml/SaliencyED
0 摘要
事件检测(ED)是事件提取的一个重要子任务,旨在识别文本中某些事件类型的事件触发词。尽管事件检测取得了重大进展,但现有的方法通常采用 "一个模型适合所有类型 "的方法,这种方法没有看到事件类型之间的差异,这项研究深入研究了这个问题,并提出了一个新的概念,即触发词显著性归因,它可以明确地量化事件的基本模式。在此基础上,我们为ED开发了一种新的训练机制,它可以区分依赖触发词和依赖上下文的类型,并在两个基准上取得了可喜的表现。
1 引言
在本文中,首次将倾斜的性能归因于事件的上下文模式。
图1中所示了Divorce和Start-Position的两个典型实例。直观上,它们表现出不同的模式:Divorce事件更依赖于触发词,触发词divorced非常表明事件的发生;相反,Start-Position事件更依赖于语境——事件语义主要是由上下文表达的,而不是触发词became,这仅仅是一个简单的动词。

事件检测模型在捕获上下文语义上具有挑战性,所以出现两个问题:
- 能定量的估计一个事件的模式吗?
- 如何通过表征这些模式来描述ED模型
为了解决第一个问题,引入了触发词显著性归因(trigger saliency attribution)的brandy新概念,它可以明确地量化事件的上下文模式。图2说明了关键思想:确定事件有多少依赖触发词或有多少依赖上下文,度量触发词对整体表达事件语义的贡献。
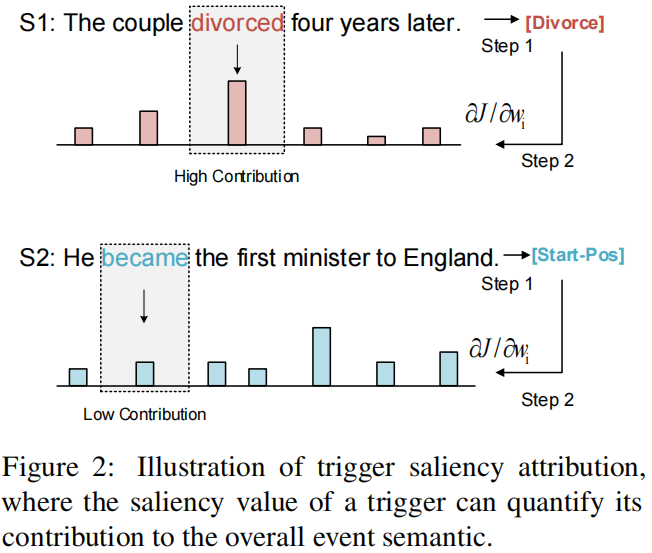
具体来说,首先为每个句子分配全局事件标签,它表示全局事件语义。然后将每个单词视为一个特征,并计算其对预测全局事件标签的贡献(即显著性值saliency value)。最后,通过检查ground-truth触发词的显著性值,可以知道该事件对触发词或上下文的依赖程度(更高值的触发词表明对事件的贡献更大,意味着该事件更依赖于该触发词)。
为了回答第二个问题,开发了一种新的基于触发词显著性归因的训练机制,它利用显著性作为证据来增强学习。不使用单一模型来检测所有事件类型,而是将具有相似模式的事件类型分组在一起(通过触发词的显著性归因进行评估),并为每个组开发单独的模型。该策略使不同的模型能够捕获不同的模式——例如,上下文相关类型的模型可以专注于挖掘上下文信息以进行学习。为了进一步提高学习能力,还提出了两种显著性探索策略来增强上述框架,它可以明确地将显著性信息集成到学习中,并产生更好的性能,特别是对于上下文相关的类型。
贡献如下:
- 分析了ED模型偏离性能的根源,并提出了一个新的概念,即触发词显著性归因,它可以评估潜在的事件模式。可以评估事件的基本模式。作为一项开创性的研究,提出了传统的 "一个模型适合所有类型 "的范式可能需要被改变。
- 提出了一种新的基于触发显著性归因的ED训练机制,它在两个基准测试上取得了良好的结果,特别是在处理上下文相关的事件类型时。
- 强调了触发词依赖和上下文依赖的事件类型的几种不同模式,未来可能会激励对它们之间的差异的研究。
2 背景和相关工作
事件检测
事件检测是事件抽取的一个重要子任务,旨在定位文本中的事件实例。
传统的事件检测方法通常使用细粒度的特征,而较新的方法则依赖于神经网络,使用句法信息、文档级线索和外部监督信号来促进学习。然而,大多数方法不承认事件类型之间的区别,并训练一个单一的模型来识别所有的事件类型,导致在不同的事件类型上有相当大的性能偏差。虽然已经有两项开创性工作已经观察到了在依赖语境的文本上相对较差的表现,并提供了一个更好的语境探索策略来改善训练。但他们的立场是改善性能,而不是研究根本原因。
另一方面,我们的方法对这一问题进行了重新审视,旨在为学习定义事件的基本模式。
特征归因
特征归因(feature attribution,FA)的目标是评估一个输入特征对模型预测的重要性。即计算每一个输入特征的属性,来代表该特征的重要性。
假设输入向量:![]()
![]() 和函数:
和函数:![]() 表示一个模型,x的属性值和相对应的输出
表示一个模型,x的属性值和相对应的输出![]() 被定义为一个向量
被定义为一个向量![]() (其中
(其中![]() 表示
表示![]() 对
对![]() 的贡献。
的贡献。
现有的FA方法分为基于梯度的方法和基于参考的方法,前者认为输出与输入的梯度是归属值,后者认为模型的输出与某些 "参考 "输出之间的差异,以输入与某些 "参考 "输入的差异为归属值。在包括图像分类、机器翻译、文本分类等应用中,FA已经被用来解释模型预测。据我们所知,本文是第一个将FA引入ED的工作,用于量化基础事件模式。
积分梯度(Integrated Gradient)
积分梯度是一种特定的特征归因方法,它将特征因值视为沿模型输入x 和参考输入![]() 之间的累计梯度。将输入的第i个特征的归因(attribution)定义为:从基线(baseline)xi′到输入xi之间的直线路径的路径积分:
之间的累计梯度。将输入的第i个特征的归因(attribution)定义为:从基线(baseline)xi′到输入xi之间的直线路径的路径积分:

其中![]() 代表一个神经网络,
代表一个神经网络, ![]() 是F(x) 在第i维上的梯度。
是F(x) 在第i维上的梯度。
与其他FA方法相比,积分梯度法的计算效率高,在处理广泛的基于文本的任务中很有效。
3 触发词显著性归因
Algorithm 1概述了触发词显著性归因的方法,该方法包含三个步骤:句子级事件分类(sentence-level event classifification)、单词级显著性估计(word-level saliency estimation)、类型显著性估计(type-level saliency estimation)。
有N个词的句子,事件检测的任务是预测事件标签序列
,其中
![]() 表示单词
表示单词![]() 的事件标签,
的事件标签,![]() 是包含所有预定义事件类型的集合,O表示无触发词的 "空类型"。
是包含所有预定义事件类型的集合,O表示无触发词的 "空类型"。

句子级事件分类(sentence-level event classifification)
首先给出表示整个事件语义的句子级的事件标签,
![]() ,其中
,其中![]() 表示第 i 个事件类型的触发词是(
表示第 i 个事件类型的触发词是(=1)否 (
=0)存在于s。
然后构建了一个句子级事件分类器,目的是学习s到的映射。用bert作为句子分类器,损失函数为multi-label binary cross-entropy loss:

是s在bert中的输入embedding,
表示由分类器计算的对数向量,
表示
的第i个元素。
单词级显著性估计(word-level saliency estimation)
在句子级分类器的基础上,采用积分梯度来计算每个单词对预测的贡献(即显著性值)。利用损失函数作为desired model,并计算 的显著性(saliency),更准确地说,BERT表示
,关于损失的计算方法:
是全零向量序列(作为参考输入),
是
的第i个元素。
然后,将![]() 归一化为一个标量值
归一化为一个标量值

(其中,![]() 表示L2范式)
表示L2范式)
实际上,我们关注的可能不是一个词对一般事件语义的显著性,而是关心特定的事件类型
。为此,使用方程(3)中T的one-hot表示来代替
来进行评估。最后,用
来表示
![]() 相对于事件类型T的单词级显著性,如果句子没有描述任何T类型的事件,则假设
相对于事件类型T的单词级显著性,如果句子没有描述任何T类型的事件,则假设 = 0。
类型显著性估计(type-level saliency estimation)
在单词级显著性的基础上,我们将类型级触发词显著性值(关于事件类型T)记为:

(s,Y)的范围为每个训练实例;{
|
=T}是包含句子s中T类型的所有触发词的集合。
类型级显著性值 SL(T)表明事件类型T是如何依赖触发词或上下文的,并且它已被证明与每个类型的模型性能密切相关.
4 显著性增强事件检测
在基于触发显著性归因的基础上,设计了一种新的ED训练范式,可以区分具有相似学习模式的事件类型,并取得了良好的效果。如图3所示。
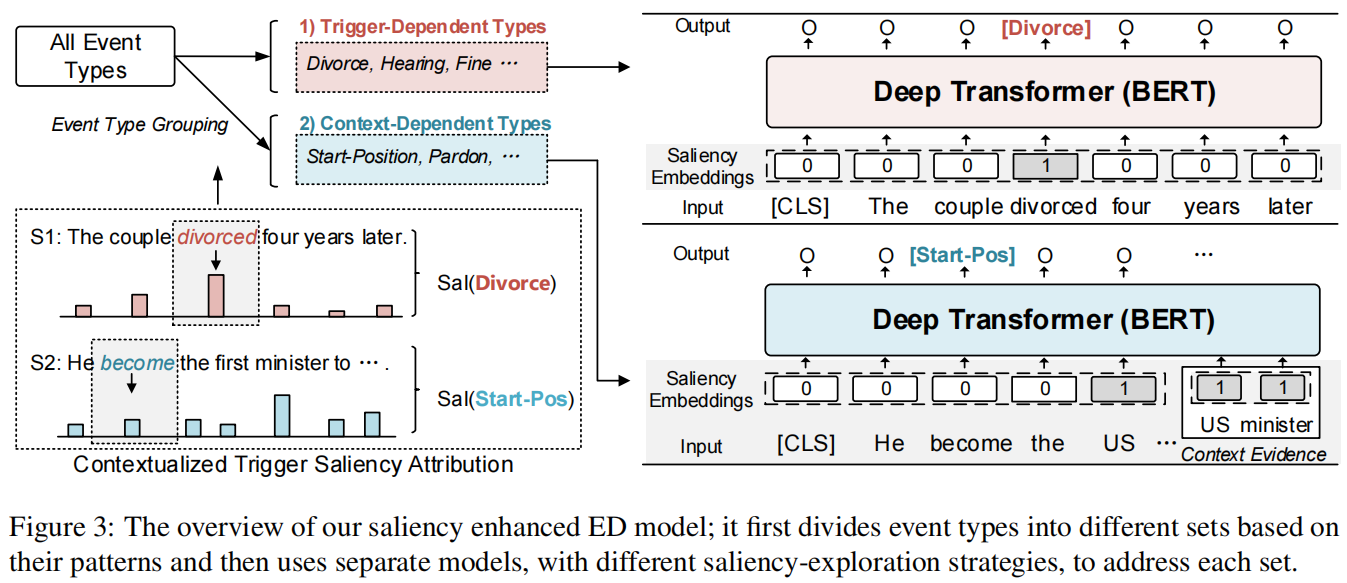
事件类型划分(Event Type Division)
在基于触发显著性归因的基础上,将事件类型划分为触发词依赖集和上下文依赖集
。阈值λ是根据经验确定为所有每个类型的触发显著性值的中间值,这意味着事件类型被平均分为两组。
富有显著性的事件检测器(Saliency-Enriched Event Detector)
接下来,为触发词依赖集和上下文依赖集
创建单独的ED模型。用Bert来实现每个模型。给定句子s,它对BERT的输出执行逐字的分类,生成一个标签序列:
,
是
的预测事件标签。因为触发词依赖类型和上下文依赖类型有不同特征,所以设计了不同的显著性探索方法来促进学习。
(i) 单词显著性嵌入(Word Saliency Embeddings)
因为触发词依赖的类型往往有指示性的触发词,所以对于触发词依赖集,在模型中建立了一个称为单词显著性嵌入(WSEs)的机制,以捕捉这种规律性。具体来说,首先根据λ将每个单词的显著性值量化为0或1,即之前用于区分事件类型的阈值;然后使用单独的嵌入向量来区分0和1,类似于单词嵌入。

嵌入被合并到模型中,具有高显著性值的单词更有可能成为触发词。
注意,单词显著性嵌入WSEs也被纳入了的模型中,它学习相反的规律性,即具有高显著性值的单词可能不是触发词。
(ii)显著性作为上下文证据(Saliency as Context Evidence)
在的事件检测中,还设计了一个机制,将显著信息解释为推理的上下文证据。

输入:句子 + context evidence
对于示例S2。
输入:He became the first US minister to England. + US minister
将上下文词“US minister”识别为表达整体事件语义最显著的词(即显著性值大于λ)。将显著的上下文词视为补充证据,并将它们与可供学习的句子连接起来,如下图所示。

与WSEs相比,该方法可以额外捕获显著词的词汇语义,这已被证明在很大程度上有助于识别与上下文相关的事件类型。
模型集成Model Ensemble
在测试阶段,结合两个模型的结果来做出最终的预测。如果出现模棱两可的情况,即两个ED模型预测同一词的不同事件类型,使用概率较高的类型作为结果。使用交叉熵损失来进行优化。例如,触发词的模型是通过最小化以下损失来训练的:

式中![]() 表示每个训练实例;(wi,yi)的范围是每一对单词和它的ground-truth event label;
表示每个训练实例;(wi,yi)的范围是每一对单词和它的ground-truth event label;![]() 表示模型预测wi的yi的条件概率。我们使用Adam对默认的超参数来进行参数更新。
表示模型预测wi的yi的条件概率。我们使用Adam对默认的超参数来进行参数更新。
5 实验
- 表3显示了不同模型的性能。
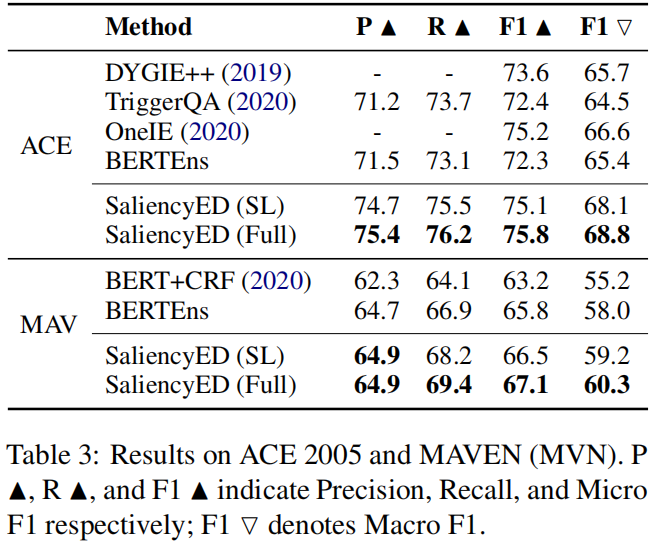
研究结果证实了我们的方法的有效性。
(i)我们的完整模型获得了最好的F1值(75.8%和67.1%)
(ii) 在相同的架构下,我们完整的模型SaliencyED(Full)在两个数据集中的分别比BERTEns的F1值高出了2.8%和1.7%;SaliencyED(SL)只区分训练的事件类型,其F1值比BERTEns高出1.6%。这表明识别ED的事件模式的重要性。
(iii) 我们的方法在两个数据集上得到了较好的F1值,表明它在常见事件类型和罕见事件类型上都表现良好。
- 表4显示了依赖触发词(TD)和依赖上下文(CD)类型的性能细分。

结果表明,不同的模型在TD类型上表现良好,而在CD类型上表现较低,这意味着我们的触发词显著性归因方法所发现的模式是合理的。
当比较SaliencyED(SL)和SaliencyED(Full)时,我们发现显著性探索方法对CD类型(F1+2.3%)比对TD类型(F1+0.3%)更有效。这是有迹可循的,因为检测与上下文相关的事件主要依赖于上下文推理,而我们的方法只可以只使用重要的上下文作为证据来改善学习。
- 表5中进行了一项消融实验,以更具挑战性的上下文依赖(CD)类型为例,研究不同的模型成分。
在变体模型中
+WSE和+Evidence分别表示用单词显著性嵌入和上下文证据补充显著性嵌入(SL)
+MaskAtt是一种计算attention的方法这掩盖了这个词本身,这可以推动模型更多地关注学习的环境;
+Gold Arguments是一种预言性的方法,它使用真实论元作为学习的证据。
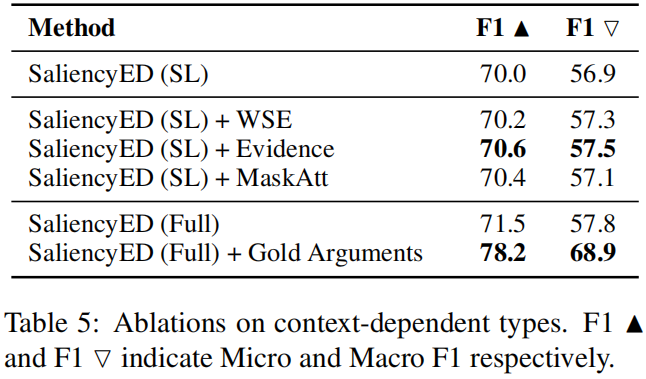
结果表明,+Evidence的性能优于+WSE和+MaskAtt,这表明在依赖上下文的时间中,加入context evidence还是有用的。
有趣的是,+MaskAtt也提高了性能,这意味着CD事件的上下文确实携带了判断事件类型的重要信息。最后,+Gold Arguments的优越表现表明,寻找指示性证据(例如,事件Arguments)是促进CD类型学习的关键因素。
- 图7描述了几种案例的显著性图。TD类型的事件触发词通常确实具有很大的显著性值。
例如,案例2)是触发显著性值最低的divorce实例,它仍高达0.34。相比之下,CD类型的事件触发词通常具有较低的显著性值。例如,案例4)和案例6)显示了Transfer-Money和Transport的随机实例,其中触发词的显著性值只有0.01。

6 结论
在本研究中,我们分析了一个ED模型的倾斜性能的起源,并引入了一个称为触发显著性归属的新概念来量化事件的模式。
我们为ED设计了一种新的训练范式,它可以区分触发词依赖的类型和上下文依赖的类型学习,在两个基准测试上产生了有希望的结果。
我们也广泛地研究了这两种类型之间的差异,我们的工作可能会促进未来对这一问题的研究。在未来,我们将把我们的方法应用于其他对上下文模式很重要的任务(例如,关系提取)。














 418
418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









