







稀疏专家模型(Sparse expert models)介绍
随着大模型的发展及其背后训练&推理成本的不断攀升,稀疏专家模型(Sparse expert models)这个三十年历史的概念,因其在提高计算效率方面的可能性,再次吸引了人们的注意。
这类架构包括 Mixture-of-Experts、Switch Transformers、Routing Networks、BASE Layers 等,所有这些都服务于一个统一的想法:对每个输入的处理只使用模型的部分参数。通过这种方式将参数量和实际计算量分离,从而允许极大但高效的模型。其中,基于 Transformer 结构的混合专家模型(Mixture-of-Experts)是当下最流行的变体,也是本文主要探讨范围。
基本概念
混合专家(MoE)
一种通用的模型结构,理论上可以适用于任意神经网络模块。也可以被认为是具有不同的子模型,每个子模型用于不同的输入,混合专家模型由两个关键部分组成:
- 混合专家层(MoE Layer): 这些层代替了传统 Transformer 模型中的前馈网络(FFN)层。MoE 层包含若干“专家”,每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络 (FFN),但它们也可以是更复杂的网络结构,甚至可以是 MoE 层本身,从而形成层级式的 MoE 结构。
- 门控网络或路由(Gate or Router): 用于控制哪些 token 被发送到哪个 Expert。路由算法是所有混合专家架构的关键特征,决定了知识分配和专家分化结果。
稀疏性(Sparsity)
神经网络吸收信息的能力,受限于其参数的数量。在 MoE 的基础上,实现条件计算(Conditional computation)的理论承诺,即对每个输入样本,激活神经网络不同部分(作为对比,在传统的稠密模型中,所有的参数都会对所有输入数据进行处理),使得在不增加额外计算负担的情况下扩展模型规模成为可能。
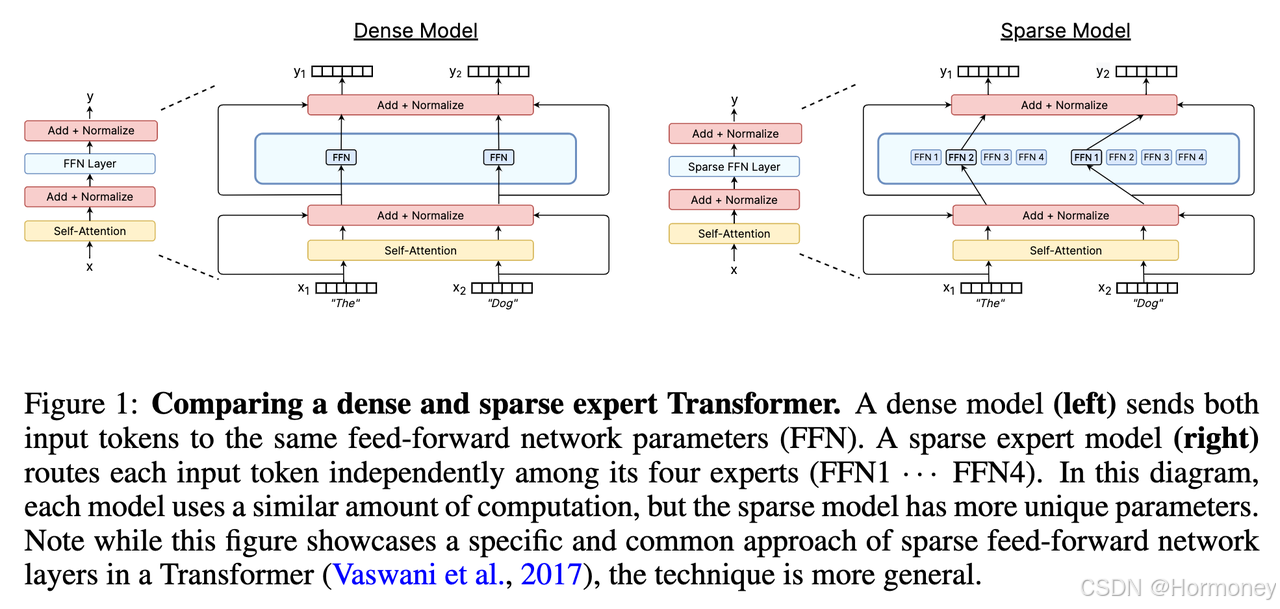
路由算法
这个领域目前有了比较广泛的研究和实现,理解路由算法的常用方法是分析路由分数矩阵:
- 每个 Token 选择前 k 个 Expert(目前用的最多,需要考虑 balancing)
- 每个 Expert 选择前 k 个 Token(每个 Token 路由到可变数量专家,负载均衡;缺少成功实践)
- 全局确定哪些 Token 应该分配给哪些 Expert(好处是最优分配,全局查找成本高;BASE layers)
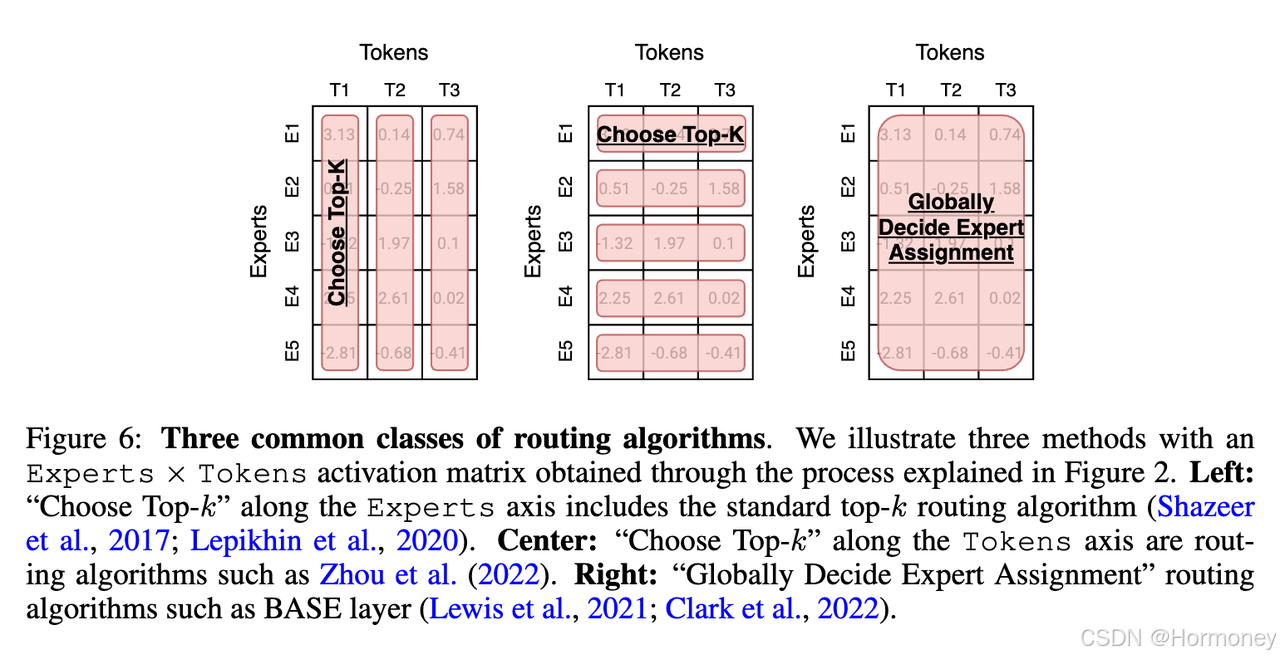
上面三张图对应三种策略: - 每个 Token 选择前 k 个 Expert(目前用的最多,需要考虑 balancing)
- 每个 Expert 选择前 k 个 Token(每个 Token 路由到可变数量专家,负载均衡;缺少成功实践)
- 全局确定哪些 Token 应该分配给哪些 Expert(好处是最优分配,全局查找成本高;BASE layers)
Top-K
经典的 top-k 实现,首先门控网络(W_r)经过学习针对不同输入会给不同 Expert 计算一个分数:
h
(
x
)
=
W
r
⋅
x
h(x)=W_r·x
h(x)=Wr⋅x
然后对该 MoE 层中可用的 N 个专家的分数做 softmax 归一化,可以得到每个专家的权重:
p
i
(
x
)
=
e
h
(
x
)
i
∑
j
N
e
h
(
x
)
j
p_i(x) = \cfrac{e^{h(x)_i}}{\sum_j^Ne^{h(x)_j}}
pi(x)=∑jNeh(x)jeh(x)i
最后选出权重最高的 k$个专家(T),则该层的输出是这些专家计算结果的线性加权组合:
y
=
∑
i
∈
T
p
i
(
x
)
E
i
(
x
)
y=\sum_{i\in{T}}p_i(x)E_i(x)
y=i∈T∑pi(x)Ei(x)
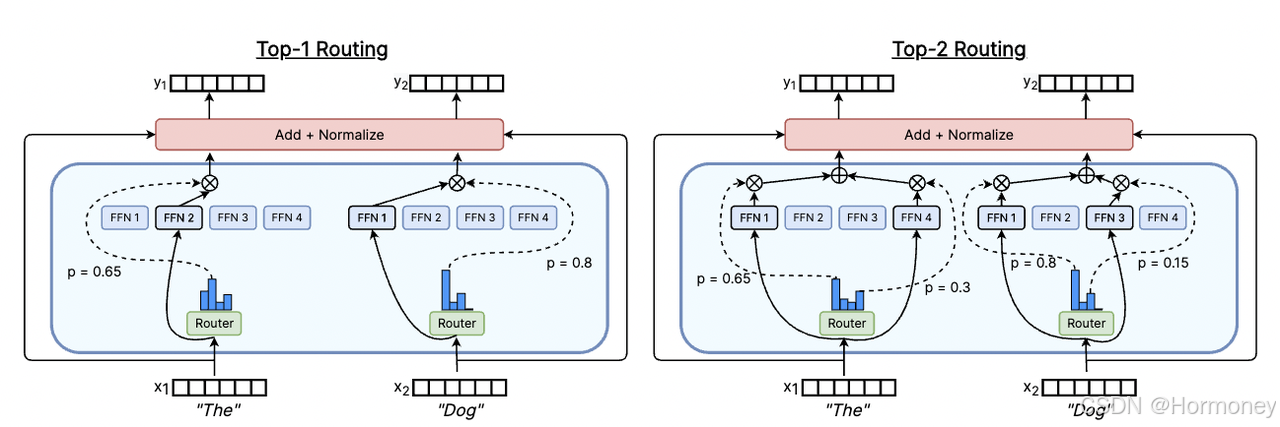
为了避免不同专家的负载不均,通常会在训练过程中添加辅助损失来处理负载平衡,以鼓励将相同数量的令牌发送到不同的专家。
直觉上参与计算的专家数(k值)多一些可能拿到更好的效果(在不同任务上,研究结论不一致),但同时计算量也会随之线性增长(Sparsity 降低),目前的应用主要集中在 top1 和 top2。
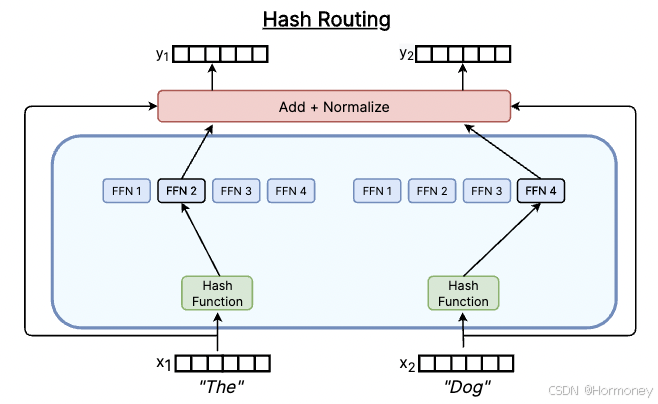
Hard Gate
硬路由也叫静态路由。大多数路由算法在训练时动态学习路由决策,硬路由则是在训练开始前通过规则静态确定,相同输入永远分配给同一个专家。
BASE Layer
平衡专家分配层(Balanced Assignment of Experts),将 token-to-expert 转化为线性分配问题,可以得到一个每个专家接收相等数量 token 的最优分配。
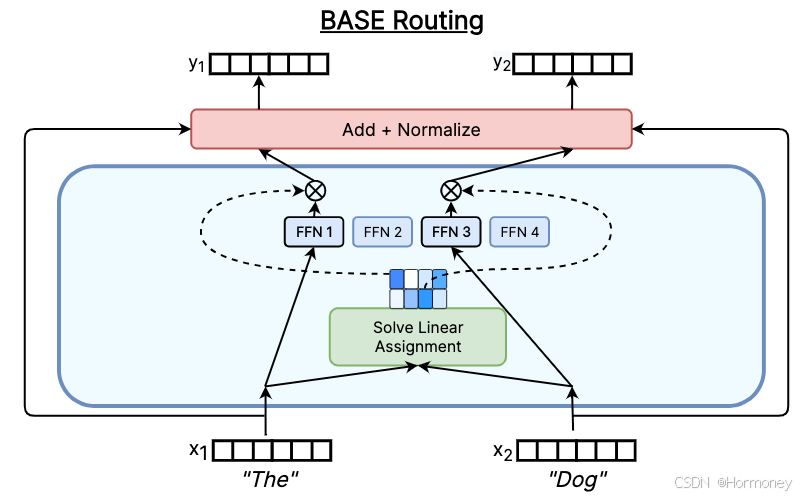
优点是解决了 tok-k 的负载不均问题,但路由开销更高。
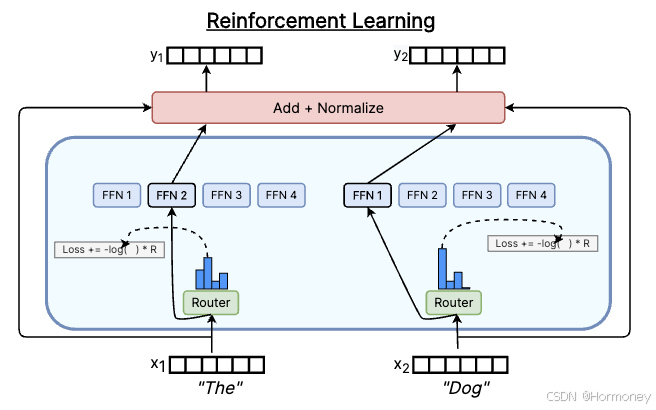
RL-R
基于强化学习的路由算法,代表工作有 Unified Scaling Laws for Routed Language Models,使用 top1 路由,将预测出来的 token 的负交叉熵作为奖励。
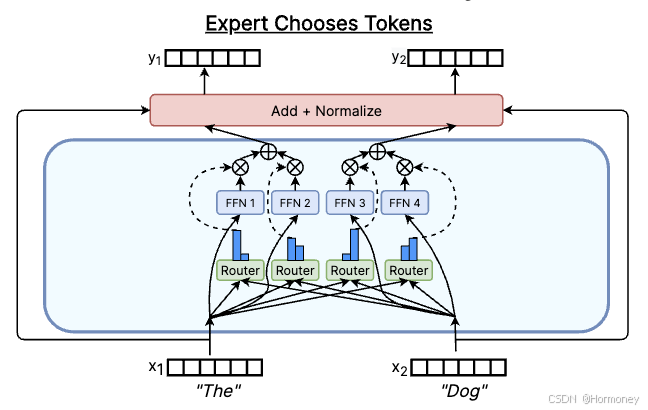
Expert Choose Tokens
每个 Expert 选择前 k 个 Token,代表工作有 Mixture-of-Experts with Expert Choice Routing,彻底解决了训练期间不同专家的负载平衡问题(不需要辅助平衡损失或线性分配算法)。
缩放属性(Scaling)
由于增加了专家维度,对稀疏专家模型的缩放效果的验证变得更加复杂。稠密语言模型的性能被证明与模型参数数量、数据量成幂律关系,但针对稀疏专家模型,目前更多的是基于经验结果的启发式缩放,还没有形成稳定的缩放定律。
适用场景
- 从任务角度看,比较适合输入特征明确的多任务、多分域场景
- 从效率角度看,如果模型受限于 Flops 预算,可以考虑 Sparse MoE
简短的总结
优点
- 预训练收益更高,速度更快
- 推理速度更快
- 架构潜力尚未完全挖掘,比较有潜力
缺点
- 需要更多显存
- 需要考虑路由策略和均衡问题
- Finetune 结果不稳定,Pretrain 超参试错成本高

















 8001
8001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









