







一、推理加速背景知识
1.1 模型压缩
1.1.1 模型参数量化
量化(quantization),即将浮点数形式的模型参数和/或激活值转换为低比特的整型(int8、int4)或其它离散形式。量化后的模型,有着更小的内存容量与带宽占用、更低的功耗和更快的推理速度。(模型量化后是否一定提升推理速度,这一点是不确定的,如果部署平台的底层硬件并没有针对整型计算的优化,那么,由于量化/反量化等额外操作的加入,推理速度甚至会降低;不过,可以肯定的是,量化会降低内存需求,从而在推理阶段可以增加batch_size,提升Throughput)。
根据量化所应用的不同阶段,可以将量化方法分为三类:量化感知训练(QAT,Quantization-Aware Training)、量化感知微调(QAF,Quantization-Aware Fine-tuning)及训练后量化(PTQ,Post-Training Quantization)。QAT在模型的训练过程中采用量化(如LLM-QAT),QAF在预训练模型的微调阶段应用量化(如PEQA、QLORA),PTQ在模型完成训练后对其进行量化。
PTQ由于实现方式简单,不涉及对模型架构的改动也无需额外的训练,因此成为多数LLM首选的量化方式。PTQ大体可分为两类,一类只量化模型参数,如LLM.int8()、ZeroQuant、GPTQ等,另一类同时量化模型参数和激活值,如SmoothQuant、RPTQ、OliVe等。PTQ的缺点也很明显,若将模型量化至更低bit(如int4),会产生较明显的精度损失。
1.1.2 KV cache量化
在模型推理时,我们可以将中间结果key以及value的值量化后压缩存储,这样便可以在相同的卡上存储更多的key以及value,增加样本吞吐。
在config.json里提供了use_cache_quantization和use_cache_kernel两个参数来控制是否启用KV cache量化,具体使用方法如下:
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen-7B-Chat",
device_map="auto",
trust_remote_code=True,
use_cache_quantization=True,
use_cache_kernel=True,
use_flash_attn=False
)
注意:当前该功能不支持与flash attention同时开启,如果你开了KV cache量化的同时又开了flash attention(use_flash_attn=True,use_cache_quantization=True, use_cache_kernel=True),程序默认将关闭use_flash_attn。
1.2 底层优化
底层优化,最常见的是算子融合——将多个OP(算子)合并成一个OP(算子),来减少kernel的调用。因为每一个基本OP都会对应一次GPU kernel的调用和多次显存读写,这些都会增加大量额外的开销。另外一种底层优化,是改用C++来实现模型推理(如llama.cpp),较之Python,C++运行速度更快。
分布式并行推理,主要包括张量并行(Tensor Parallelism,TP)、流水线并行(Pipeline Parallelism,PP),并行可以降低Latency。值得注意的是,多GPU并行度选择需要慎重,毕竟过多的GPU并行,会增加跨GPU通信开销和降低每个GPU的计算粒度,从而导致最终结果是增加而不是降低Latency。
1.2.1 Flash-Attention 2
FlashAttention主要应用了tiling技术来减少内存访问,将内存开销降低到线性级别,以此来提升速度,具体来说:
- 从HBM中加载输入数据(K,Q,V)的一部分到SRAM中
- 计算这部分数据的Attention结果
- 更新输出到HBM,但是无需存储中间数据S和P
FlashAttention 2在FlashAttention算法基础上进行了调整,减少了非矩阵乘法运算(non-matmul)的FLOPs。
1.3 解码方式优化
1.3.1 Medusa
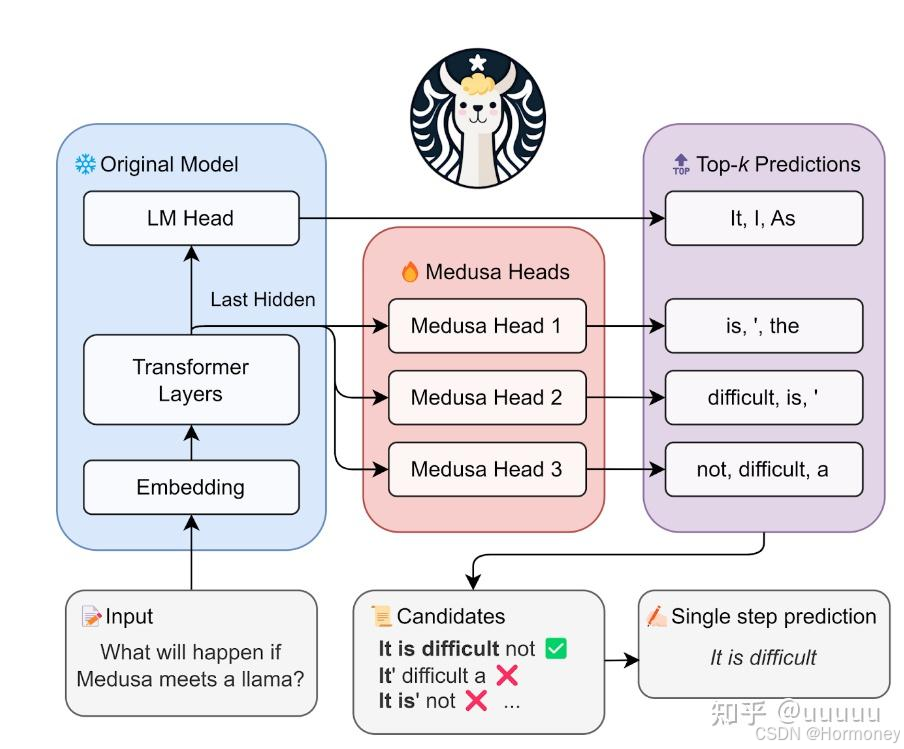
主要思想是在正常的LLM的基础上,增加几个解码头,并且每个头预测的偏移量是不同的,比如原始的头预测第i个token,而新增的medusa heads分别为预测第i+1,i+2…个token。如上图,并且每个头可以指定topk个结果,这样可以将所有的topk组装成一个一个的候选结果,最后选择最优的结果。
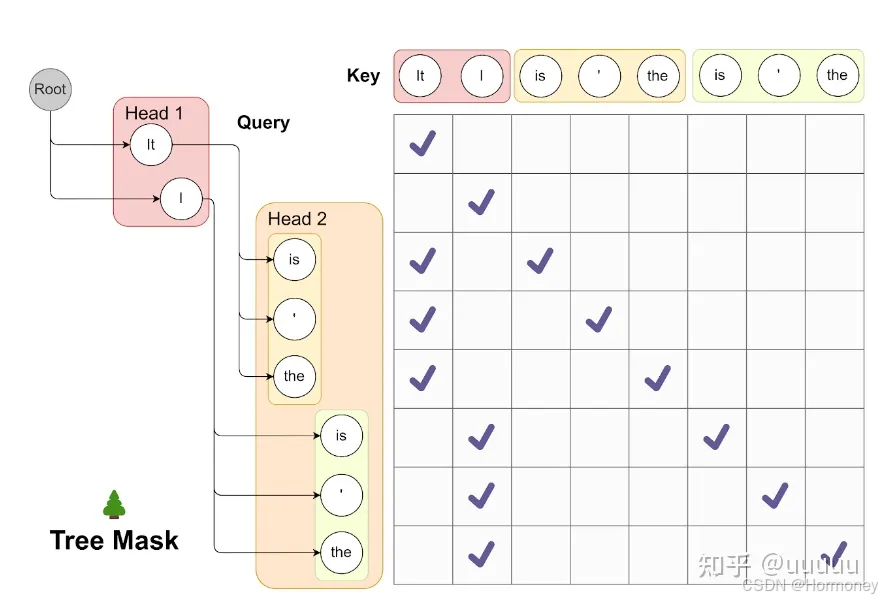
该方案需要新增解码head,并冻结除新增head之外的其它部分参数,只训练新增的head。
1.3.2 SpecInfer
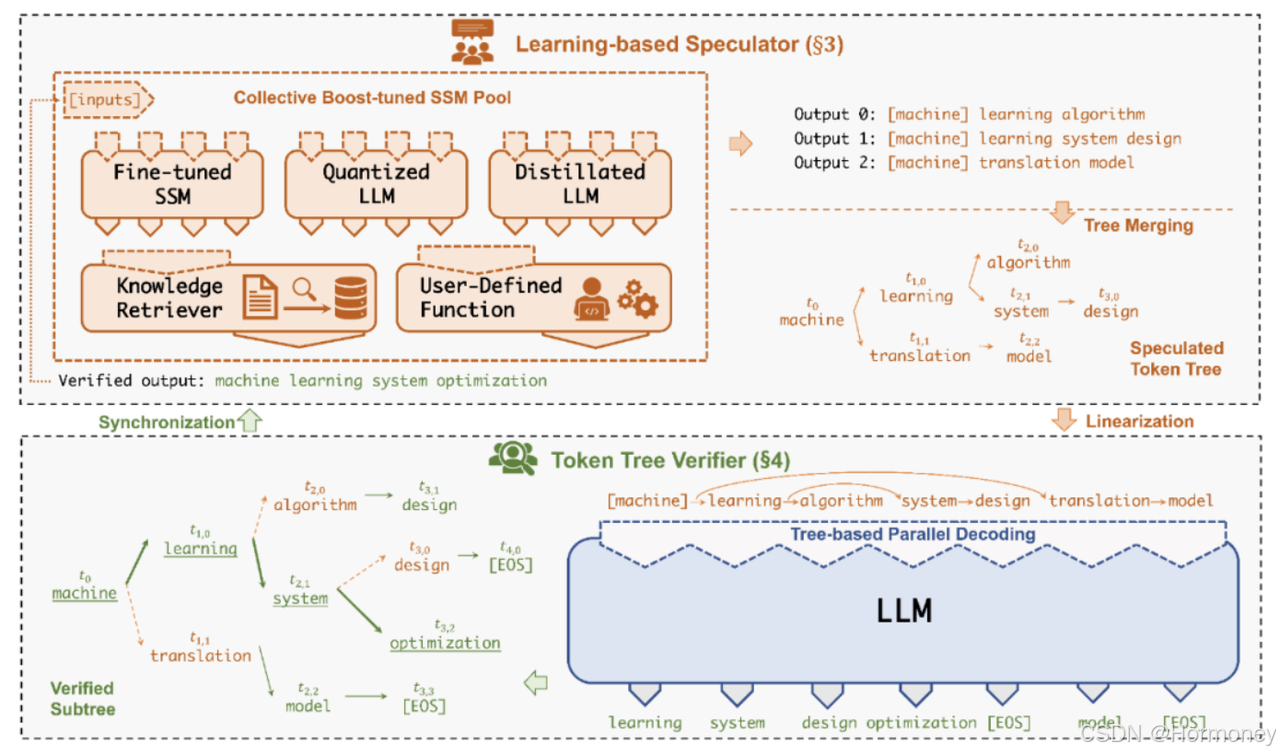
核心思想是通过计算代价远低于 LLM 的 “小模型” SSM(Small Speculative Model)替代 LLM 进行投机式地推理(Speculative Inference),每次会试探性地推理多步,将多个 SSM 的推理结果汇聚成一个 Speculated Token Tree,交由 LLM 进行验证,通过高效的树形解码算子实现并行化推理,验证通过的路径将会作为模型的推理结果序列,进行输出。
Speculator 的主要作用是利用 SSM 快速产生对 LLM 未来输出的推测结果,SSM 可以是(微调后)小版本的 LLM(如 LLaMA 7B),也可以是量化或蒸馏的小规模 LLM,还可以是可供检索的知识库(如参考文本)亦或是用户的自定义函数。总之,SSM 的输出结果越接近 LLM,验证时才会更容易通过,整体的推理效率才会更高。
由于SSM的参数规模通常会小2-3个数量级,能力有限,SpecInfer引入了“collective boost-tuning”技术,基于adaptive boosting的思想,对SSM进行微调,让SSM与原始LLM更好地对齐,提升预测准确率,降低Verification的成本
总体上来说,SpecInfer 利用了 SSM 的内在知识帮助 LLM 以更低廉的计算成本完成了主要的推理过程,而 LLM 则在一定程度上破除了逐 token 解码的计算依赖,通过并行计算确保最终输出的结果完全符合原始的推理语义。
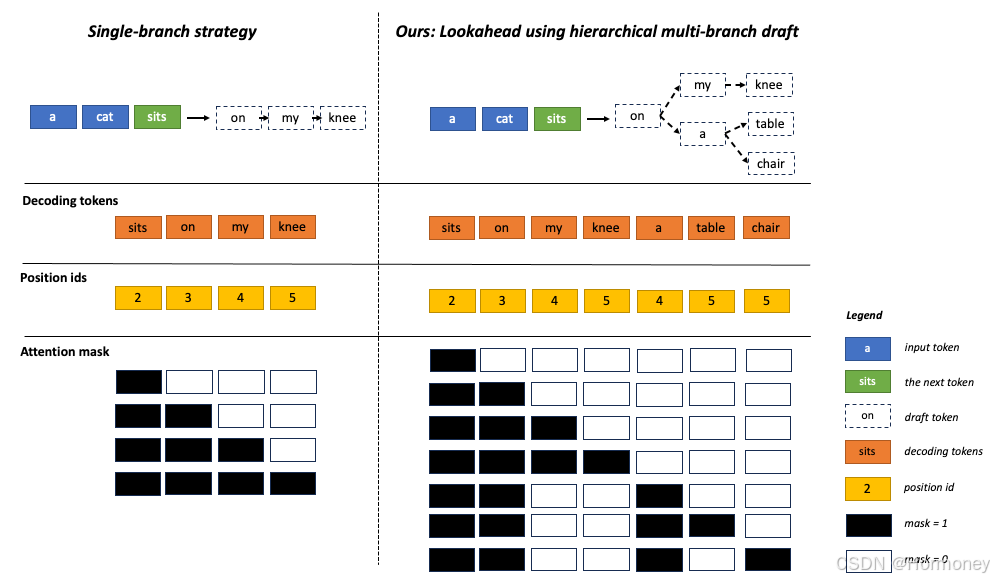
1.3.3 Lookahead Decoding
这是一种并行解码算法,即前向解码,它主要利用雅可比(Jacobi)迭代法首次打破自回归解码中的顺序依赖性。作者观察到,尽管一步解码多个新token是不可行的,但LLM确实可以并行生成多个不相交的n-grams——它们可能适合生成序列的未来部分。
这可以通过将自回归解码视为求解非线性方程,并采用经典的Jacobi迭代法进行并行解码来实现。
在过程中,让生成的n-grams被捕获并随后进行验证,如果合适就将其集成到序列中,由此实现在不到m个步骤的时间内生成m个token的操作。
该方法无需训练,但只适用于LLama架构和greedy search。
1.3.4 EAGLE
EAGLE 利用原始 LLM 提取的上下文特征(即模型第二顶层输出的特征向量)。EAGLE 建立在以下第一性原理之上:
- 特征向量序列是可压缩的,所以根据前面的特征向量预测后续特征向量比较容易。
EAGLE 具有以下特点:
- 比普通自回归解码(13B)快 3 倍;
- 比 Lookahead 解码(13B)快 2 倍;
- 比 Medusa 解码(13B)快 1.6 倍;
- 可以证明在生成文本的分布上与普通解码保持一致;
- 可以在 RTX 3090 上进行训练(1-2 天内)和测试;
- 可以与 vLLM、DeepSpeed、Mamba、FlashAttention、量化和硬件优化等其他平行技术结合使用。
EAGLE 训练了一个轻量级插件,称为自回归头(Auto-regression Head),与词嵌入层一起,基于当前特征序列从原始模型的第二顶层预测下一个特征。然后使用原始 LLM 的冻结分类头来预测下一个词。特征比词序列包含更多信息,使得回归特征的任务比预测词的任务简单得多。总之,EAGLE 在特征层面上进行外推,使用一个小型自回归头,然后利用冻结的分类头生成预测的词序列。与投机采样、Medusa 和 Lookahead 等类似的工作一致,EAGLE 关注的是每次提示推理的延迟,而不是整体系统吞吐量。
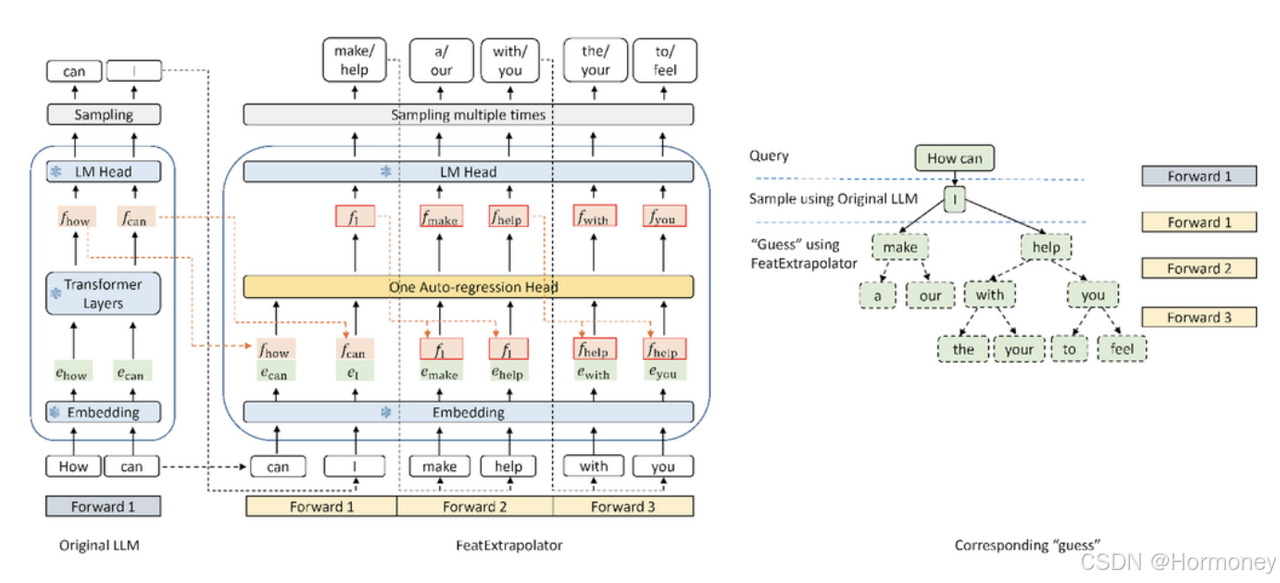
EAGLE 使用轻量级的自回归头来预测原始 LLM 的特征。为了确保生成文本分布的一致性,EAGLE 随后验证预测的树状结构。这个验证过程可以使用一次前向传播完成。通过这个预测和验证的循环,EAGLE 能够快速生成文本词。
训练自回归头代价很小。EAGLE 使用 ShareGPT 数据集进行训练,该数据集包含不到 70,000 轮对话。自回归头的可训练参数数量也很少。如上图中的蓝色部分所示,大多数组件都是冻结的。唯一要额外训练的是自回归头,这是一个单层 Transformer 结构,具有 0.24B-0.99B 参数。即使是 GPU 资源不足的情况下,也可以训练自回归头。例如,Vicuna 33B 的自回归头可以在 8 卡 RTX 3090 服务器上在 24 小时内完成训练。
1.3.5 Lookahead(蚂蚁开源版)
蚂蚁集团开源的一套新算法,可帮助大模型在推理时,提速2至6倍。能做到效果无损,即插即用,支持包括 Llama、OPT、Bloom、GPTJ、GPT2、Baichuan、ChatGLM、GLM 和 Qwen 在内的一系列模型。该算法已在蚂蚁大量场景进行了落地,大幅降低了推理耗时。
总结:
以下数据均为bs=1的情况下得到。
| 方法 | GPU Mem (GB) | Speed (Tokens/s) | 适用模型 | 使用成本 |
|---|---|---|---|---|
| int8量化 | 18.81 (来自qwen-14b官方) | 29.28 | 所有模型 | 无需训练,qwen需使用GPTQ离线量化,baichuan在线和离线均可 |
| int4量化 | 13.01 (来自qwen-14b官方) | 38.72 | 所有模型 | 无需训练,qwen需使用GPTQ离线量化,baichuan在线和离线均可 |
| KV cache量化 | 15.5 (来自qwen-14b官方) | - | qwen | 无需训练,在线量化 |
| Flash attention 2 | 理论上节约10倍 | 5000左右的context length,提速有20%以上;50左右的context length,提速不到5% | qwen,Llama, OPT,bigcode,falcon,GPT-NeoX,GPTJ | 无需训练,目前只支持A100和H100 |
| medusa | 显存增大 | 理论上推理加速比可以达到2x | Vicuna | 需要额外训练增加的head |
| spechinfer | 显存增大 | 理论上推理加速比可达到2.6x~3.5x | 所有模型 | 需要额外的小模型,并联合微调小模型。适合分布式部署 |
| Lookahead decoding | 不变 | 理论上推理加速比可达到1.5x~2.3x | LLama架构 | 无需训练,只能使用greedy search采样方法 |
| EAGLE | 显存增大 | 理论上比普通自回归解码(13B)快 3 倍 | LLama,Vicuna | 需要训练 |
| Lookahead(蚂蚁开源版) | 不变 | 2.66-6.26 倍的加速比 | Llama, OPT, Bloom, GPTJ, GPT2, Baichuan, ChatGLM, GLM, and Qwen | 无需训练 |
| Heavy-Hitter Oracle | 在KV Cache开启下,降低KV Cache缓存,最多可减少20X | 理论上加速比可达到3x | LLama,GPT-NeoX,OPT | 无需训练,需要改造attention部分 |
| Flash-Decoding | 理论上节约10倍 | 当context length增长到64k时(batch_size=1),理论上可达到8x加速比,越长加速越明显 | LLama | 无需训练,但没有开源代码。目前只有flashattention和xformer环境下使用 |
| vllm | - | 比HuggingFace Transformers(HF)高14x-24倍 | 几乎所有模型,LLaMA系列、ChatGLM系列、GPT系列、Baichuan、BLOOM、OPT、Falcon,Qwen。但只支持cuda 11.8和12.1 | 安装方便,需要将LLM和adapter合并后使用 |
| FlexGen | 16 GB的T4卡+208G内存+1.5TB SSD,就可以完成一个175B规模大模型的serving | 与HuggingFace Transformers(HF)基本持平 | opt模型 | 无需训练,具体如何但推理延迟巨大 |
| TensorRT-LLM | - | 6,818(LLama 7B,bs=112,input length=128,output length=2048) | 几乎所有模型,LLaMA系列、ChatGLM系列、GPT系列、Baichuan、BLOOM、OPT、Falcon,Qwen | 需要将hugging face格式模型转换为TensorRT-LLM Engine。只支持H100,A100,A30,L30s |
| Text Generation Inference | - | - | Llama, Falcon, StarCoder, BLOOM, GPT-NeoX, T5 | 使用docker进行部署,只支持A100,A10G,T4 |
| DeepSpeed-MII | - | 比vLLM高2.3x | Llama, Falcon, Opt,Mistral | 安装方便,需要将LLM和adapter合并后使用 |
二、实验方法
2.1 实验模型
- 基于qwen-14b-chat的业务模型。
- 基于baichuan-13b-chat的业务模型。
2.2 实验数据
两份真实的业务评测数据。
2.3 评测方式
参考上述总结,在此次实验中,为了测试和以后使用方便。因此我只实验KV Cache量化、Lookahead(蚂蚁开源版)解码方法和vLLM。
- 实验环境:V100,32G,单卡(最好能在A800/A100上实验)
- 评测指标:
- GPU内存占用
- batch size大小
- 平均推理速度(Tokens/s)
- 推理总耗时(s)
- 准确率
- 评测对象:
- fp16(V100只能使用fp16,A800和A100可以使用bf16)
- KV Cache量化
- vLLM
- Lookahead(蚂蚁开源版)
三、实验结果
因为FP32精度,显卡无法加载模型,因此默认精度是fp16。
1. 基于qwen-14b-chat的业务模型
注意:lookahead目前不支持qwen batch推理
| 方法 | bs=1 | bs=2 | bs=3 | bs=4 | bs=5 | bs=6 | bs=7 | bs=8 | bs=9 | bs=10 | bs=11 | bs=12 | bs=13 | bs=14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| fp16 | Speed (Tokens/s) | 5.35 | 25.54 | 32.28 | |||||||||||
| qps | 0.27 | 1.31 | 1.76 | ||||||||||||
| 时延(s) | 3.74 | 0.76 | 0.57 | ||||||||||||
| GPU Memory Usage | 27.48 | 28.50 | 29.51 | OOM | |||||||||||
| KV Cache 量化 | Speed (Tokens/s) | 2.85 | 4.55 | 4.41 | 4.51 | 4.96 | 5.01 | 5.01 | 5.07 | 5.07 | |||||
| qps | 0.14 | 0.22 | 0.23 | 0.23 | 0.22 | 0.22 | 0.23 | 0.23 | 0.23 | ||||||
| 时延(s) | 7.10 | 4.49 | 4.38 | 4.37 | 4.52 | 4.46 | 4.42 | 4.38 | 4.38 | ||||||
| GPU Memory Usage | 26.86 | 27.30 | 27.72 | 28.13 | 28.58 | 29.01 | 29.44 | 29.87 | 30.30 | OOM | |||||
| VLLM | Speed (Tokens/s) | 17.09 | 30.64 | 39.88 | 47.73 | 52.21 | 57.46 | 61.30 | 66.56 | 69.56 | 72.40 | 64.01 | 65.74 | 65.62 | 67.01 |
| qps | 0.95 | 1.75 | 2.34 | 2.63 | 2.77 | 3.02 | 3.27 | 3.52 | 3.66 | 3.87 | 3.45 | 3.57 | 3.57 | 3.68 | |
| 时延(s) | 1.05 | 0.57 | 0.42 | 0.38 | 0.36 | 0.33 | 0.31 | 0.28 | 0.27 | 0.26 | 0.29 | 0.28 | 0.28 | 0.27 | |
| GPU Memory Usage | 29.81 | 29.85 | 29.9 | 29.94 | 29.99 | 29.99 | 29.99 | 29.99 | 29.99 | 29.99 | 29.99 | 29.99 | 29.99 | 29.99 | |
| Lookahead | Speed (Tokens/s) | 11.42 | |||||||||||||
| qps | 0.47 | ||||||||||||||
| 时延(s) | 2.08 | ||||||||||||||
| GPU Memory Usage | 27.59 |
2. 基于baichuan-13b-chat的业务模型
注意:lookahead目前不支持baichuan-13b batch推理,只支持baichuan2-7b batch推理
| 方法 | bs=1 | bs=2 | bs=3 | bs=4 | bs=5 | bs=6 | bs=7 | bs=8 | bs=9 | bs=10 | bs=11 | bs=12 | bs=13 | bs=14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| fp16 | Speed (Tokens/s) | 2.04 | 35.01 | 56.36 | 71.72 | 90.20 | 107.99 | 119.31 | 134.15 | 148.12 | 162.22 | 172.68 | 190.4 | 202.92 | 203.84 |
| qps | 0.18 | 3.18 | 5.12 | 6.52 | 8.20 | 9.82 | 10.85 | 12.20 | 13.47 | 14.75 | 15.69 | 17.31 | 18.45 | 18.53 | |
| 时延(s) | 5.4 | 0.31 | 0.20 | 0.15 | 0.12 | 0.10 | 0.09 | 0.08 | 0.07 | 0.06 | 0.06 | 0.06 | 0.05 | 0.05 | |
| GPU Memory Usage | 26.07 | 26.14 | 26.22 | 26.30 | 26.39 | 26.47 | 26.54 | 26.62 | 26.70 | 26.78 | 26.86 | 26.96 | 27.02 | 27.11 | |
| VLLM | Speed (Tokens/s) | 18.43 | 34.58 | 46.84 | 60.41 | 85.33 | 102.59 | 109.68 | 124.96 | 138.47 | 150.37 | 159.91 | 132.24 | 140.82 | 148.29 |
| qps | 1.67 | 2.88 | 3.70 | 4.83 | 7.62 | 9.05 | 9.48 | 10.75 | 11.87 | 13.08 | 13.96 | 10.87 | 11.73 | 11.86 | |
| 时延(s) | 0.60 | 0.34 | 0.27 | 0.21 | 0.13 | 0.11 | 0.11 | 0.09 | 0.08 | 0.08 | 0.07 | 0.09 | 0.09 | 0.08 | |
| GPU Memory Usage | 30.18 | 30.19 | 30.18 | 30.20 | 30.21 | 30.21 | 30.21 | 30.22 | 30.22 | 30.23 | 30.23 | 30.24 | 30.24 | 30.25 | |
| Lookahead | Speed (Tokens/s) | 16.93 | |||||||||||||
| qps | 1.67 | ||||||||||||||
| 时延(s) | 0.59 | ||||||||||||||
| GPU Memory Usage | 26.15 |
3. 使用VLLM在Bernard上部署基于qwen-14b-chat的业务模型
结果就是VLLM框架成功提升了推理速度,8卡部署,bs=60,qps(query/s)从23->60(+160.86%)。当然效果也有一些下降,与未加速版本相比,diff率=2.5%,gsb=27:59:14,还在可接受范围内。
四、结论
- 从推理加速性能上比较,VLLM的加速更明显,速度更快,显存占用稳定,支持更大的batch size。
- 测试的所有的推理加速方法都会导致推理效果的下降,越是对结果要求严格的任务(结果只有唯一答案),效果下降越明显。

















 9182
9182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









