






 本文介绍了SuperPoint和SuperGIue在特征点检测、描述子生成、匹配策略及外点去除等方面的神经网络优化,展示了这两种技术在SLAM和AR领域的优秀性能,探讨了神经网络方法在特征点提取中的优势和挑战。
本文介绍了SuperPoint和SuperGIue在特征点检测、描述子生成、匹配策略及外点去除等方面的神经网络优化,展示了这两种技术在SLAM和AR领域的优秀性能,探讨了神经网络方法在特征点提取中的优势和挑战。
这里写目录标题
I.SuperPoint和SuperGIue的背景介绍
特征点提取和匹配
特征点提取和匹配是多视图几何的基础理论知识,在SLAM相关领域有着重要作用。比如在视觉SLAM中,著名ORBSLAM就是基于特征点法的,一般通过特征点提取和匹配,再根据匹配关系进行几何求解就可以得到位姿。
一般流程为
1.输入一对图像
2.提取特征点
3.进行匹配
4.根据匹配关系,进行集合求解就可以得到位姿
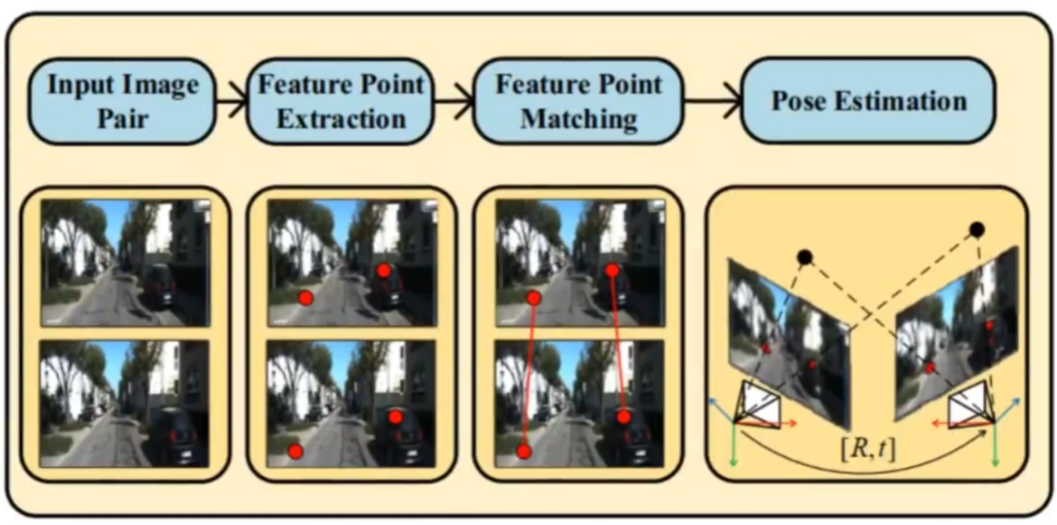
特征点提取与匹配通常在SLAM中作为前端的工作出现
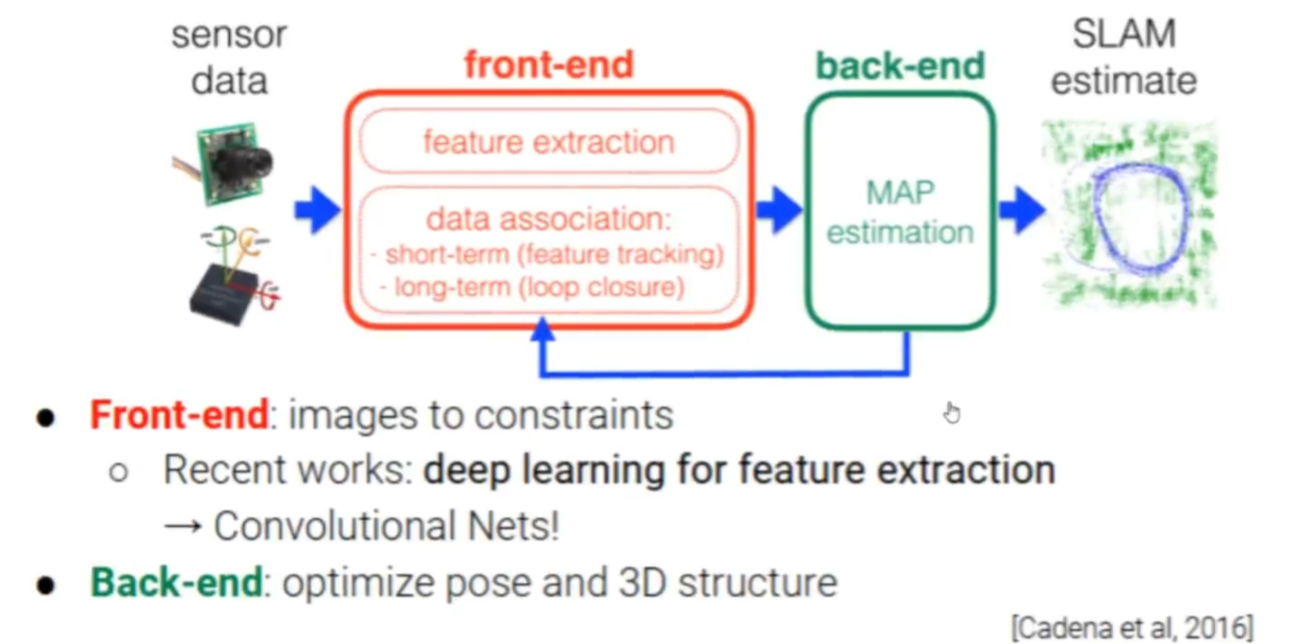
下面是superglue作者介绍的visual-slam架构
可以看到特征点提取与匹配,以及一些数据的关联是前端的工作,后端主要是做一些优化
理论上有了准确的特征点匹配关系,就能得到准确的位姿。多视图几何理论就是建立在这样的假设下的。但是现实中由于噪声,往往不能得到理想的特征点和匹配关系,比如特征点提取的位置不准确,特征点匹配错误等。现实场景中还会面临许多困难:视角的快速变换光照的剧烈改变,不同尺度的一致性问题,相似物体的干扰等。在多视图几何理论模型中,特征点提取和匹配的准确性,很大程度影响后面位姿计算的准确性。所以人们从传统方法到深度学习方法都在研究如何更好地解决这个问题。
特征点的构成
特征点是图像中特殊的像素点主要是帮助人们找到两张甚至多张图片之间的数据关联。特征点的构成主要分为两分:关键点和描述子。
关键点就是特征点的2D坐标描述的是特征点的位置信息。
描述子是指一组特定的向员用来描述特征点的周围信息情况,将抽象的图片信息,转换为向量,方便利用数学知识进行分析。有的时候特征点可以只有关键点,比如FAST,有的时候是同时具备关键点和描述子,比如ORB
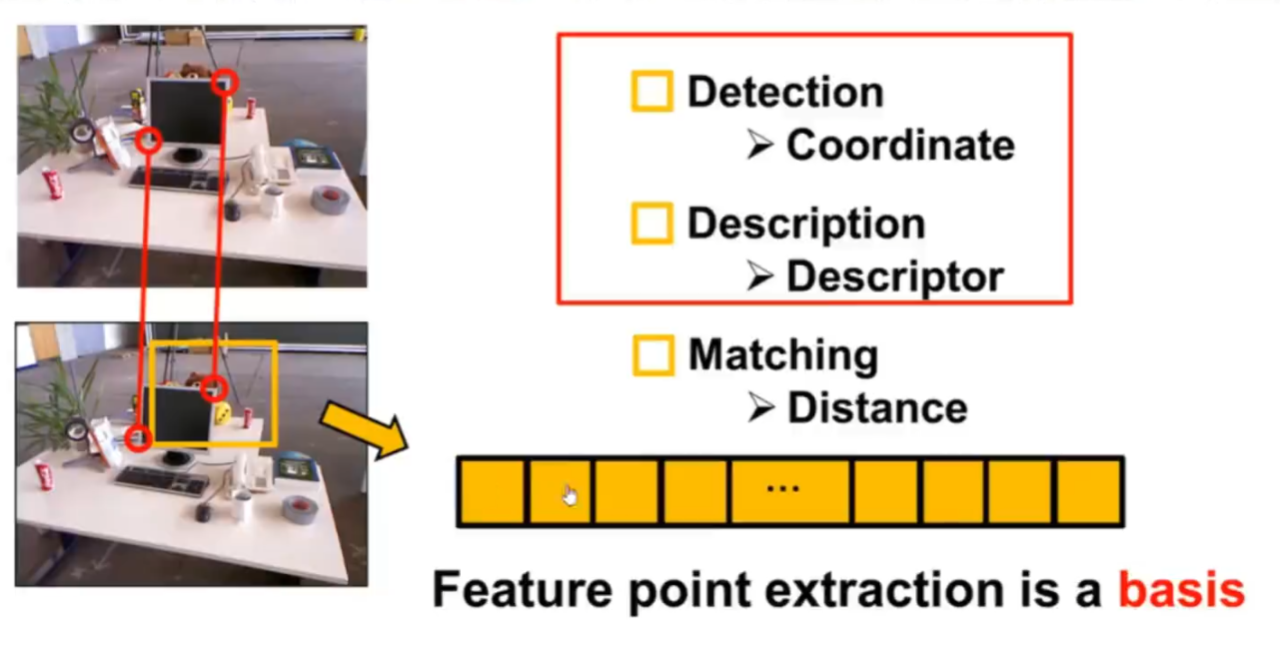
下面我们具体看一下神经网络都从哪些方面来进行研究改进
基于神经网络的方法
下面是superglue作者介绍的匹配流程
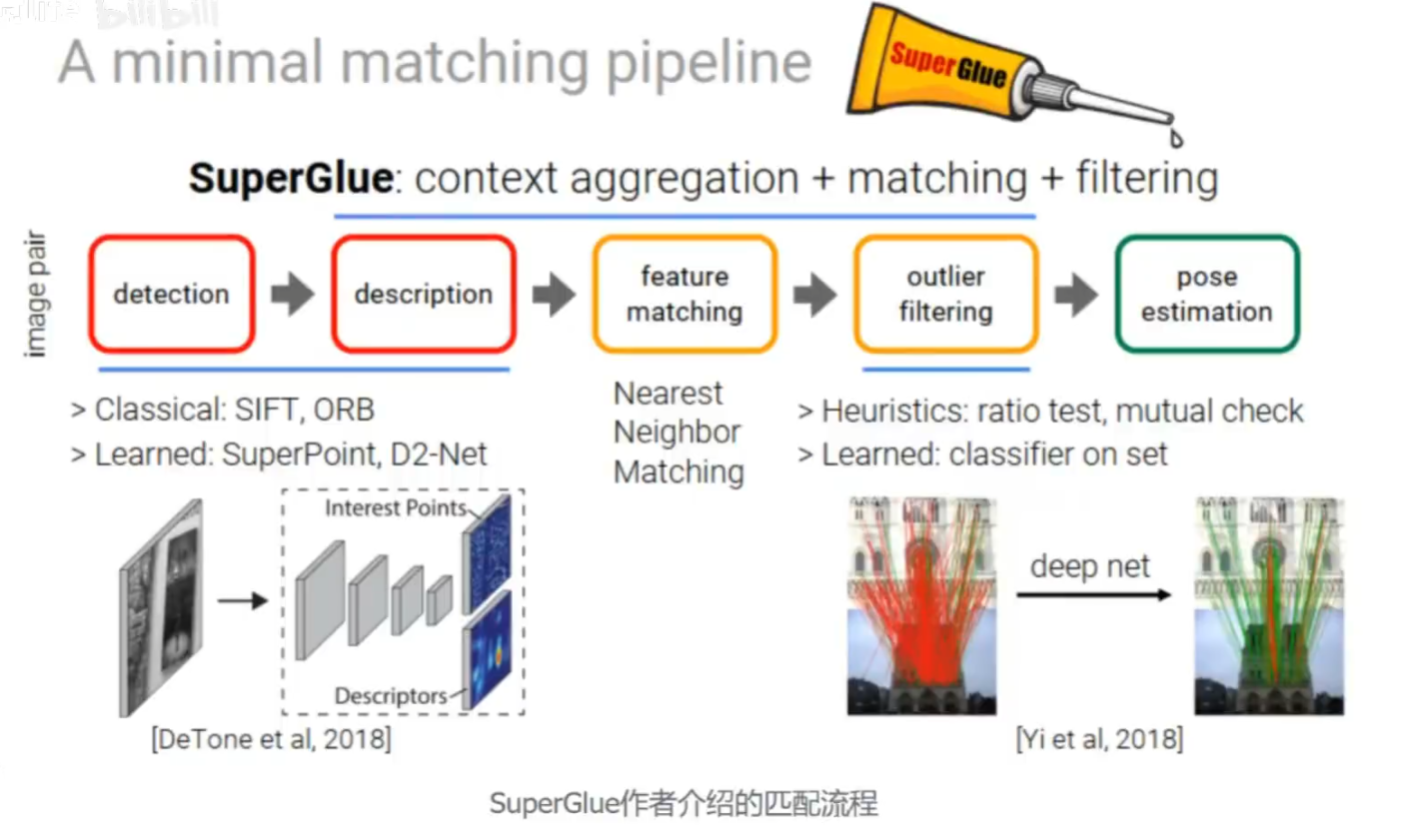
其中每个环节都有可以改进的地方
位置的检测->描述子的生成->特征匹配的方式->外点去除的策略->最后得到位姿
优化方向一:增强特征点检测和描述子生成
下面是一些特征点提取算法(传统+神经网络)的总结
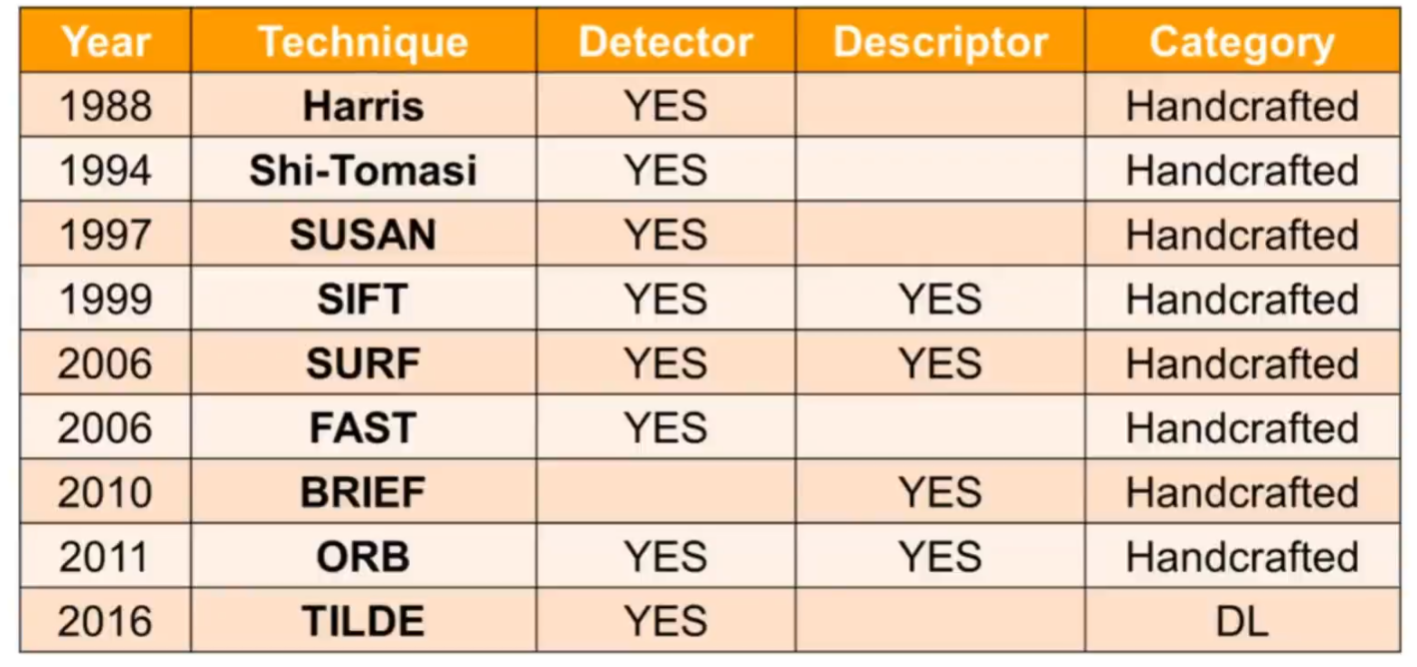
一开始的话只优化一部分,位置检测或者描述子的生成,后来两个部分都优化
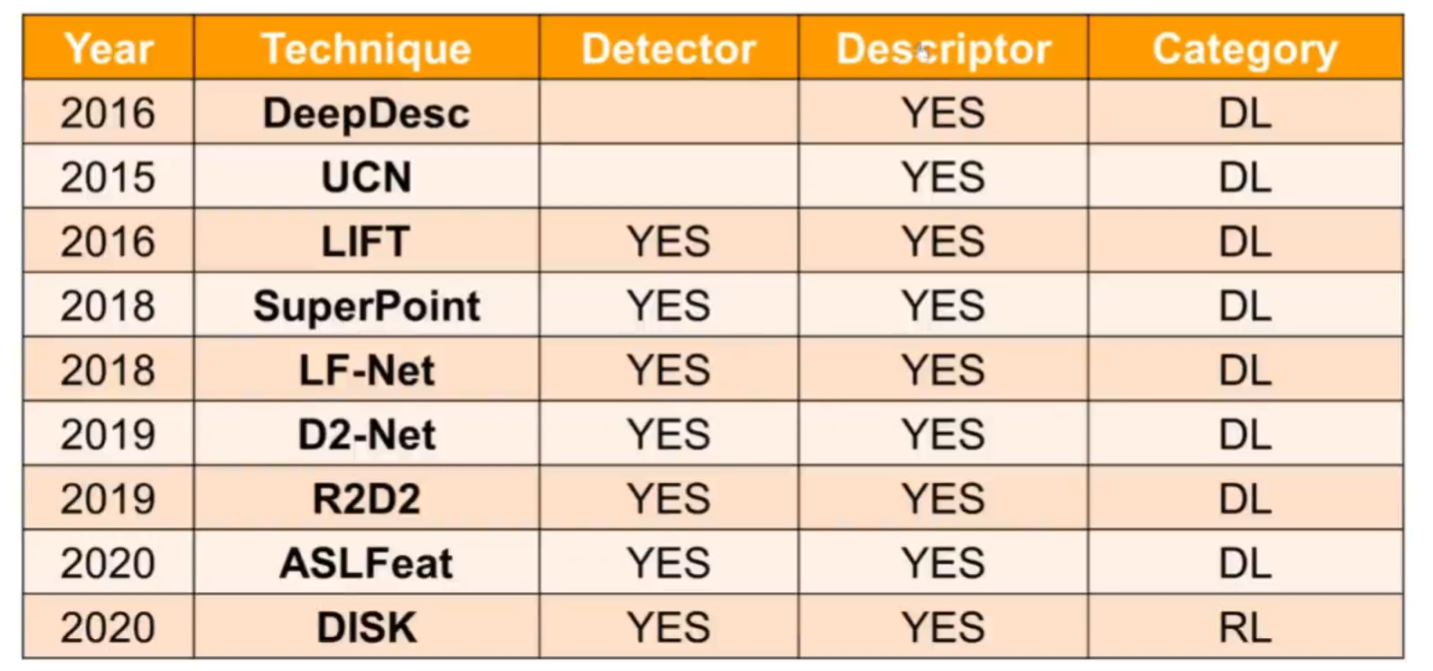
基于神经网络的方法,对于描述子信息的学习更加丰富
优化方向二:增强匹配和外点去除策略

核心思想:通过网络来学习更丰富的信息得到更准确的匹配
简单了解了神经网络在特征点提取和匹配领域的研究方向,我们来看一下SurperPoint和Superglue的背景和效果
背景和效果
SuperPoint是AR公司—magicleap的工作
Superglue是magicleap和苏黎世联邦理工学院(ETH)一起合作的
在2020年附近,SuperPoint+Superglue在特征点提取和匹配上有很好的效果,可以达到世界第一的水平

神经网络真的优于传统方案吗?
谷歌的一项工作,lmage Matching Across Wide Baselines: From Paper to Practice[1]提出了一个发现,有些神经网络的特征点提取效果在论文上看优于SIFT,但是实际中却不见得。由此准备了lmage Matching Challenge(图像匹配挑战赛)

SuperP。c在PR2020图像匹配挑战赛中排名第一
并且通过对SuperPoint+Superglue的优化,许多工作在CVPR2021图像匹配挑战赛中也名列前茅
案例:旷视科技,在2020和2021PRSLAMBE战赛上都用基于SuperPoint+Superglue的 方案登顶
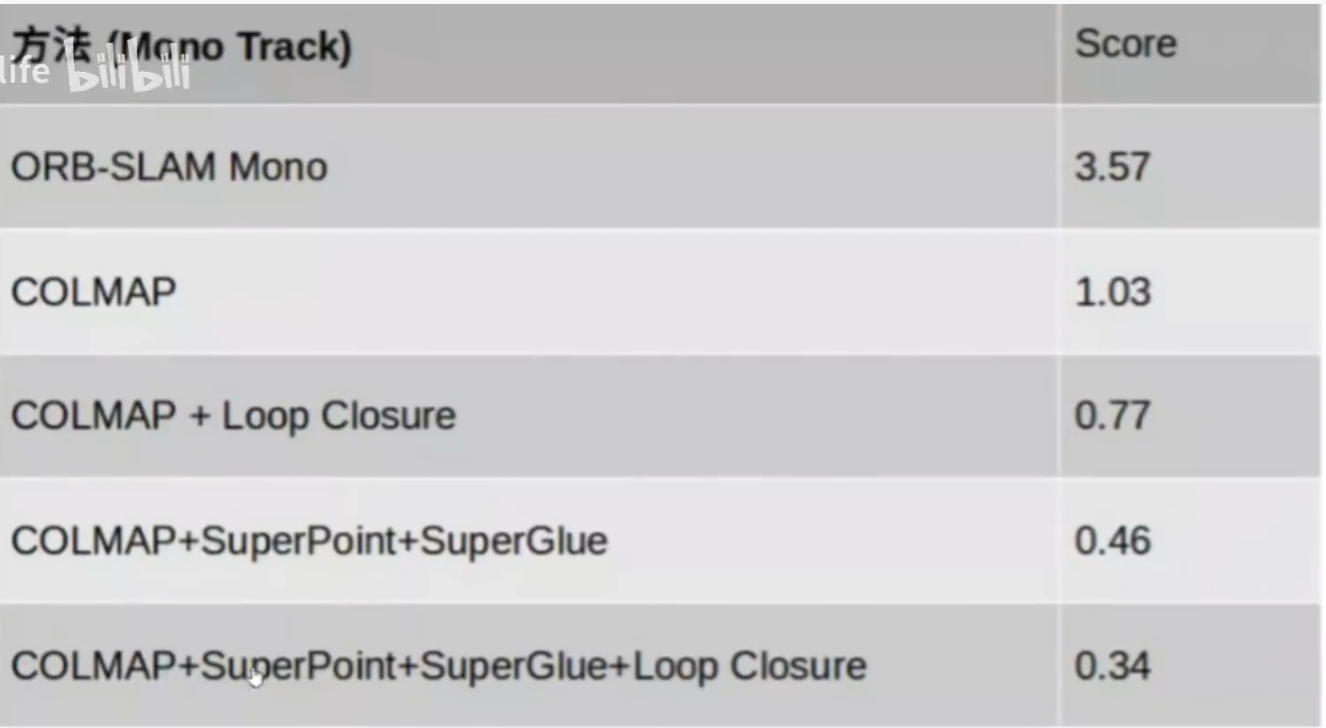
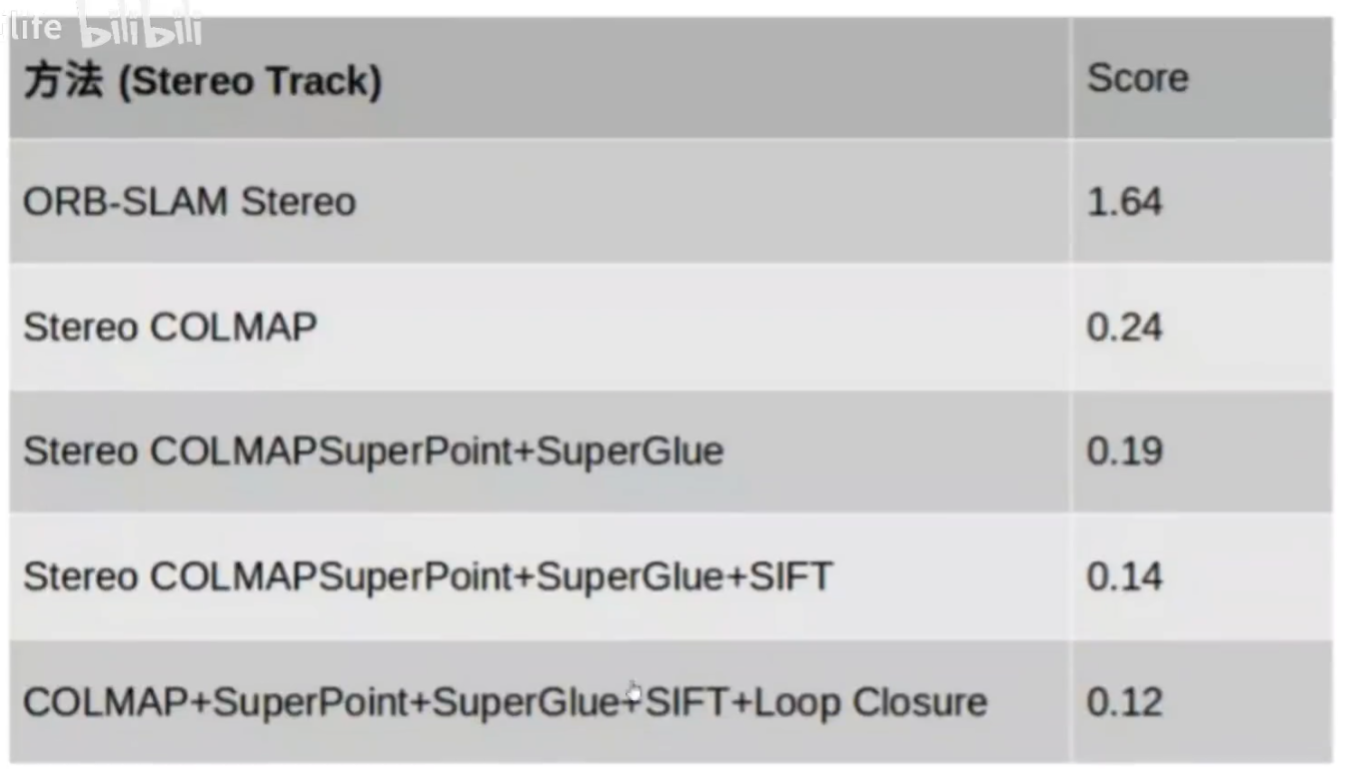
挑战赛官网,这个2020CVPR SLAM挑战赛跟刚才的那个图像挑战赛还有点不一样

这里score其实就是旋转误差和平移误差的综合,有点类似我们平时说的ATE,越小越好

由此可见,在特征点提取与匹配方面,SuperPoint+Superglue的组合是非常经典和优秀的,值得我们研究。
DEMO演示
SuperPoint的demo

Superglue的demo
 Superglue的主页
Superglue的主页
为什么研究
1·基于深度学习的SLAM,主要分为两个方面
a·端到端的SLAM,完全用深度学习来完成SLAM
b.传统sLAM框架+深度学习,神经网络替换或者增强传统模块,比如用神经网络实现特征点提取和匹配,单目深度估计,光流等
2·目前来看,传统SLAM框架+深度学习在一些移动平台上,更有可能落地。
3·SuperPoint,Superglue的网络和思想都很经典,而且效果也很好,对于初学者来说,是很好的研究案例。目前也有很多工作基于它们进行开展。
2.SuperPoint学习经验分享
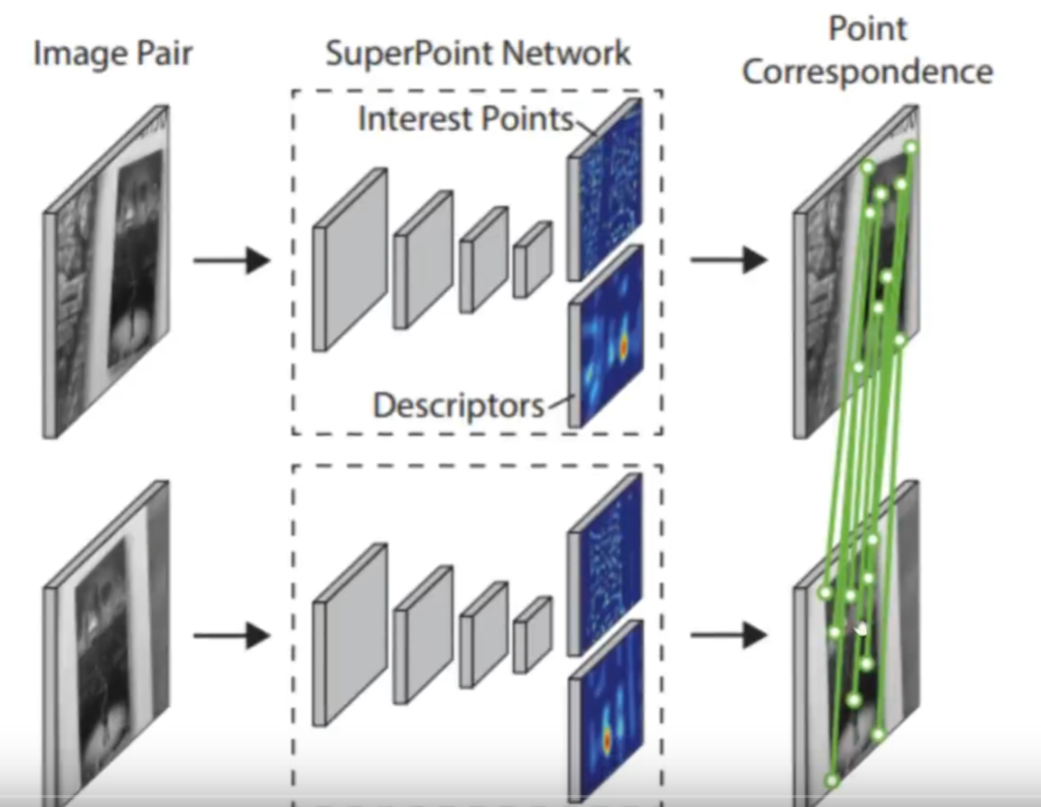
整体架构
输入是一张图像,然后经过superpoint的网络,先会经过一个编码器,然后分别得到特征点位置和描述子。如果对两张图像都进行这样的操作,最后就可以完成特征点的匹配
核心技术
1.自适应单应变换
单应变换就是表示两张图像间的映射关系
对图像施加不同的单应变换,可以模拟不同相机视角看到图像
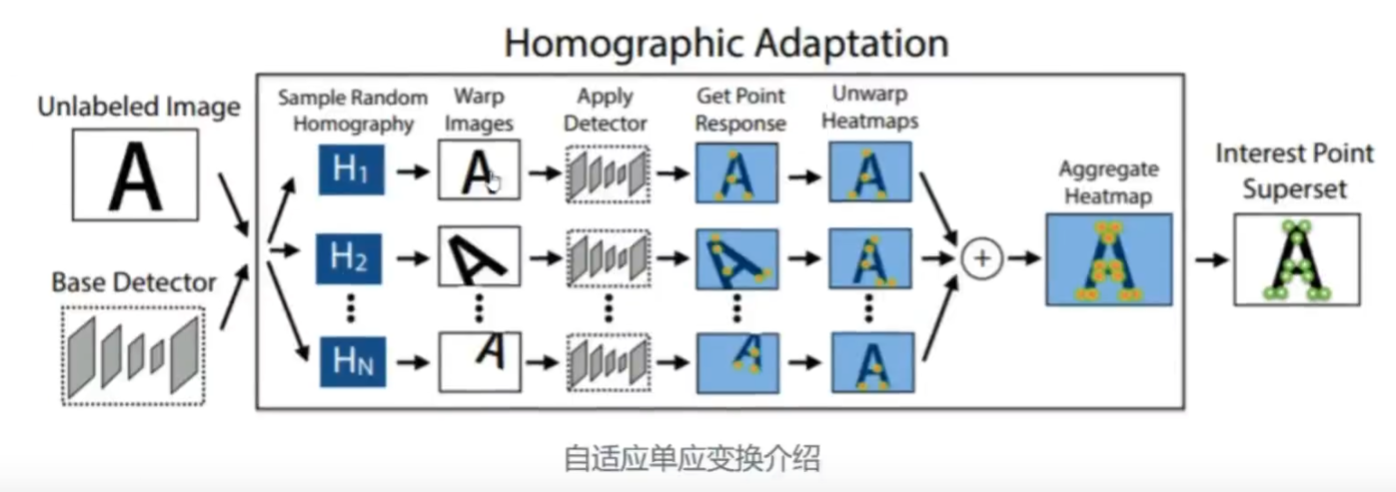
我们有一个图像,对他施加不同的单应变换,就会出现不同的变换,这样分别进行一个提点,再把它反变换回去,聚合起来,这样就可以生成一个特征点的伪真值,就类似于标签
2 Encoder-Decoder的网络结构
a·输入是一张图像
b·经过一个Encoder(类似VGG的结构)
c.送到两个Decoder里面
i,lnterestPoint:特征点位置检测,Softmax和NMS(非极大值抑制),reshape
ii.Descriptor:描述子生成,插值,L2-Norm
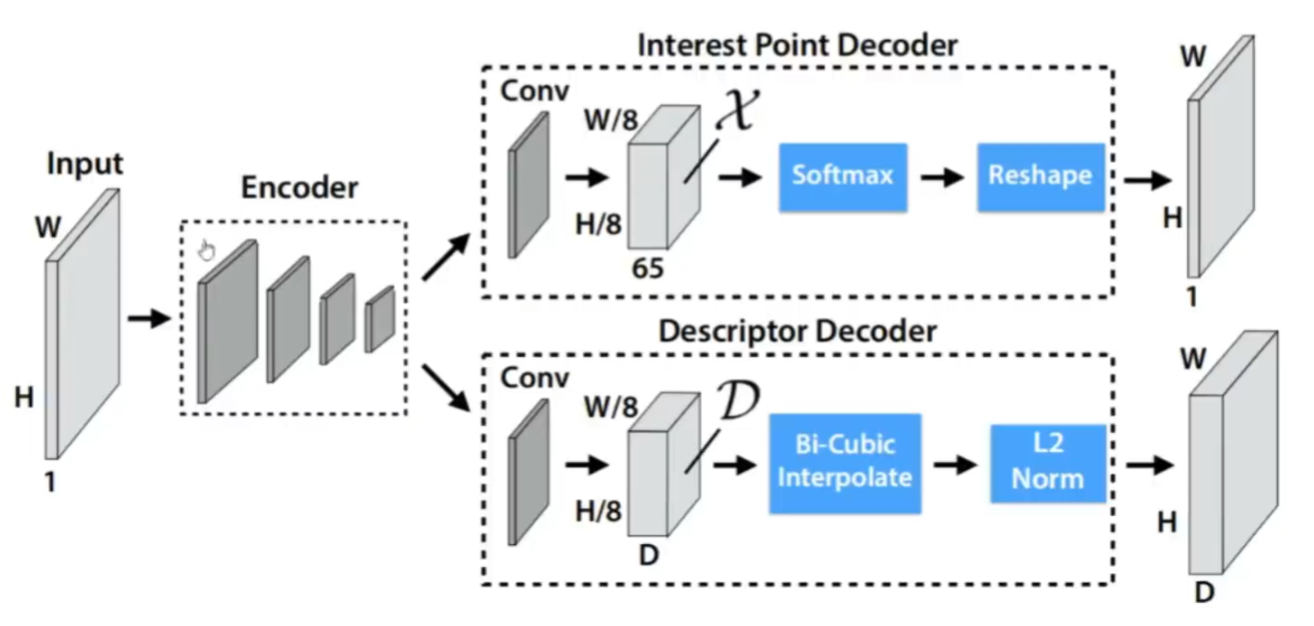
输入是一个图像,有一个共享的Encoder,类似于VGG的结构,拿到输出后同时会送给两个decoder,一个是point Decoder负责特征点位置的提取,在拿到输入之后经过Softmax和NMS(非极大值抑制),reshape,此处NMS没有标,但是用了的,然后就可以得到特征点的位置,然后下面是描述子生成的Decoder,得到网络输出之后,通过插值和标准化,就可以拿到描述子的输出了
评价;
1.提出了自监督的学习方法:图像中的标签和特征点是自动标注的,不需要人工标注
2.提出了编码器·解码器的结构,同时完成特征点位置检测和描述子生成
可以一起学习某些特征,同时又针对特征点位置检测和描述子生成这两个任务的特点,又分别处理
3.效果很好,精度可以,网络也不算太复杂
SuperPoint后面工作绕不开的经典
2.Superglue学习经验分享
整体架构
输入
两组图像的特征点坐标和描述子。比如图像A的特征点坐标pA,描述子dA;图像B的特征点坐标 pB,描述子dB
网络模型
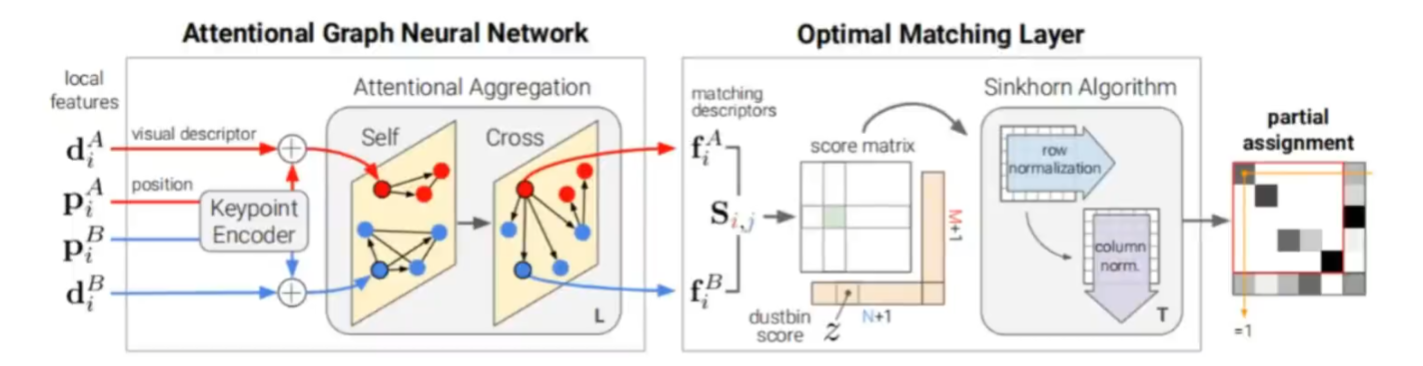
Superglue主要由两部分组成,基于注意力机制的图网络和最优化匹配层。
其中注意力机制网络先对输入的描述子和坐标通过一个encoder行聚合,然后送到带有注意力
机制的网络层进行聚合,最终得到matching descriptors
接着把匹配问题建模成运输问题,利用经典算法去sinkhorn算法求解。
核心技术
1,self·cross的注意力机制
这个是Superglue的核心思想之一,也是很值得借鉴的思想。这个方法的思路,主要还是借鉴了人类在进行两张图片之间匹配时的行为。假设我们现在人类来进行两幅图像中相似模块的匹配,比如找不同那种游戏,大家可以想想看,我们会怎么做呢?当然每个人的行为相同,但是绝大多数情况,我们是不是会分为两个步骤。
第一个步骤,先看本图像内有哪些特征和对应关系
第二个步骤,看另外一个图像中是否有相同的地方。如果有就匹配成功,如果没有,是不是我们还需要,看另外一个图像中有哪些特征关系并且带着这些特征和关系,回到本图像上继续看特征或者细节。然后重复
这里作者就是借鉴了这个思想,把它抽象了两个行为,self-attention自注意力机制和cross-attention交叉注意力机制
SeIf-attention,就是本图像的点,聚合自己图像中其他特征点的信息
Cross-attention,就是本图像的点,聚合其他图像中特征点的信息
两者交叉进行,信息在不断聚合累积,搭配上注意力机制,就做到了很强的信息聚合能力。最终输出的是matching descriptor所以这一步也可以看成是描述子增强。

2.用运输问题建模求解匹配问题
这个当时是很巧妙的思路。
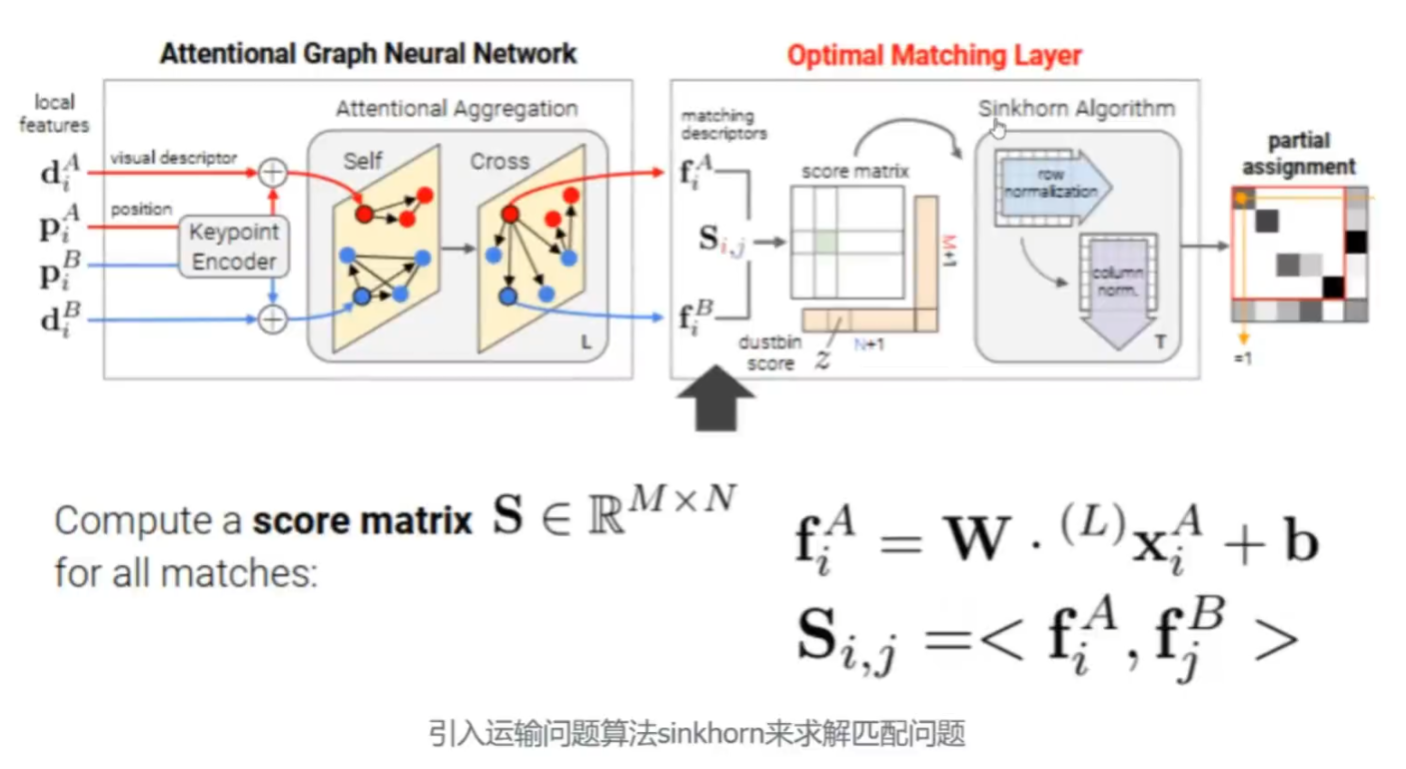
下面我们可以简单看一下运输问题是如何建模求解匹配问题的
运输问题
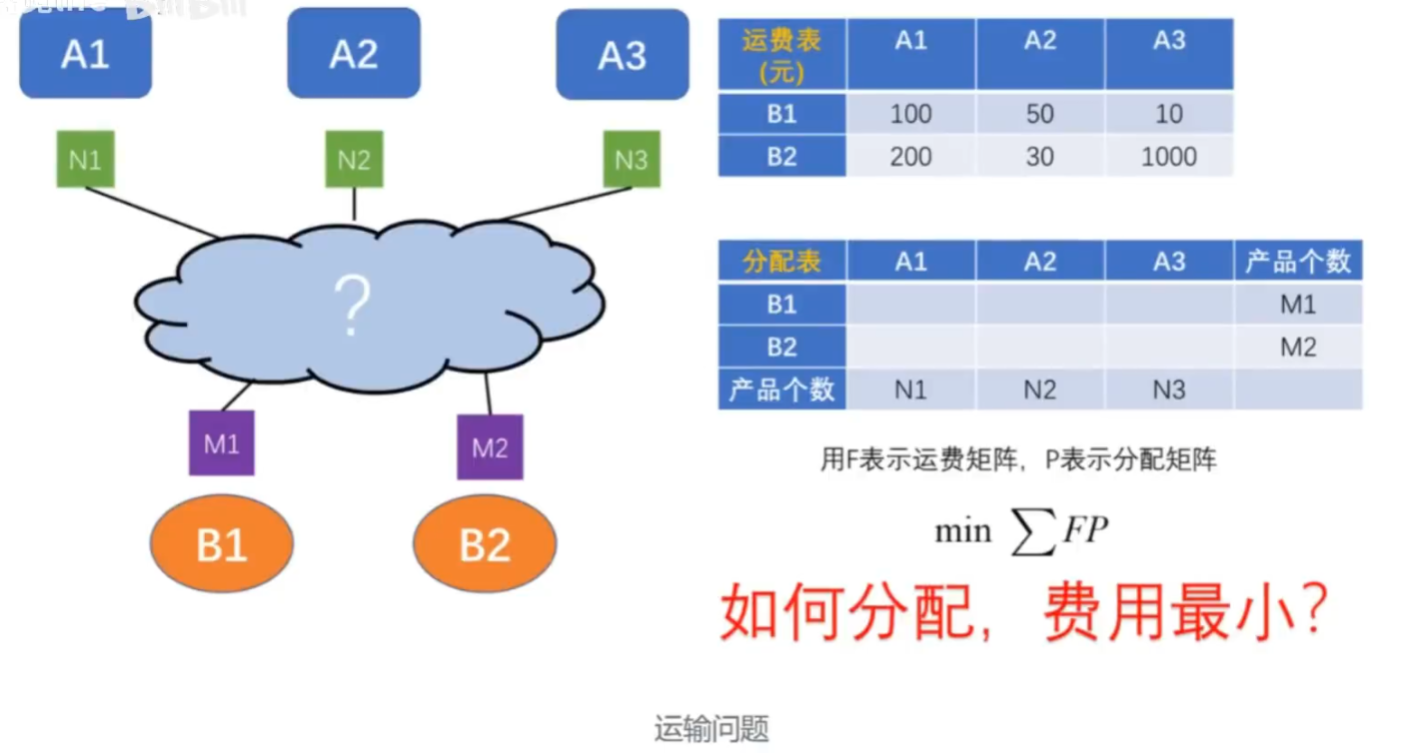


我们计算A中每个点和B中每个点的距离,就可以得到一个距离矩阵

这里12与21不一样要注意,优化不可以使用对称矩阵优化
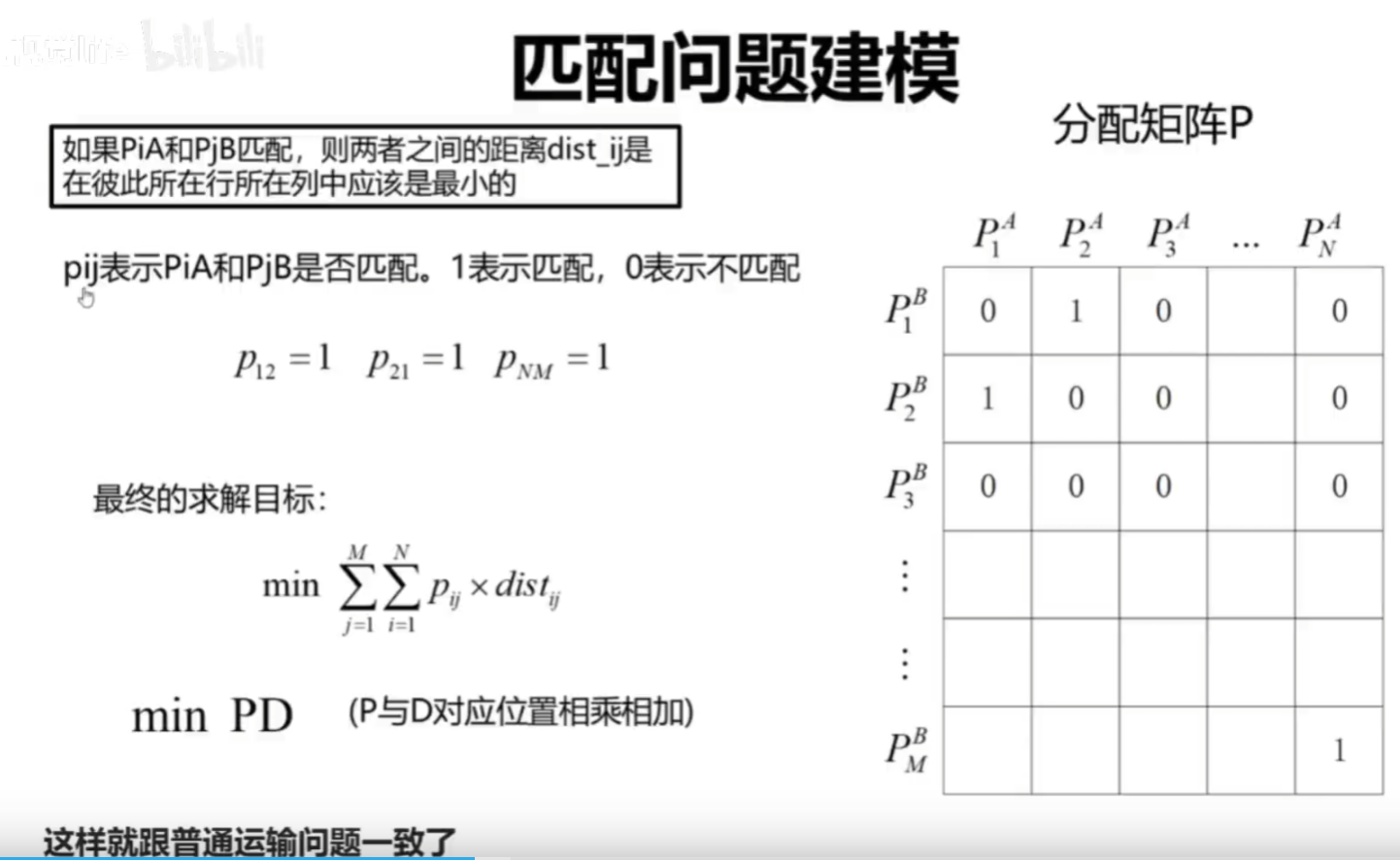
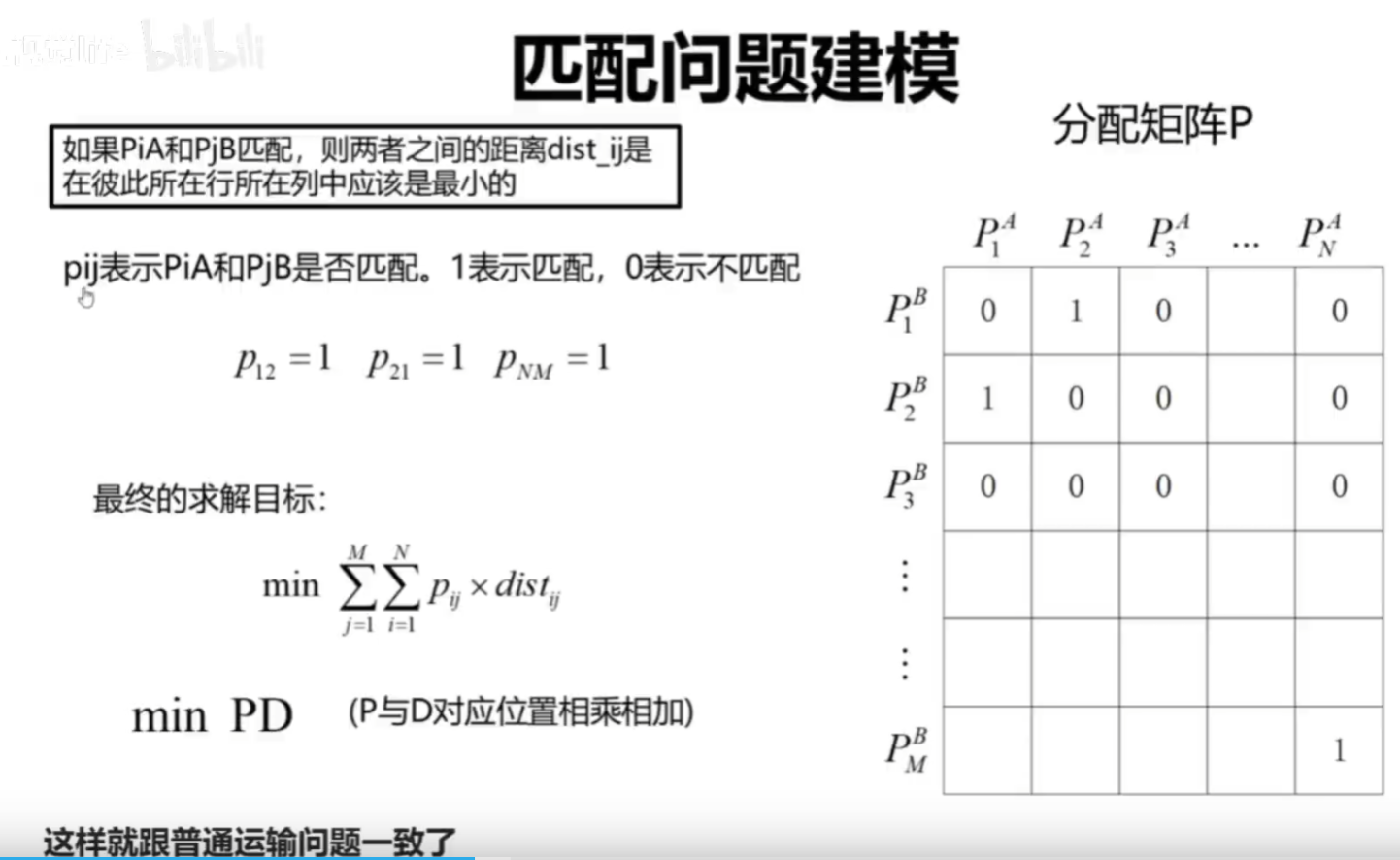
Superglue用到的sinkhorn算法就是经典的求解运输问题的一个方法
其实严格来说,特征点匹配问题是01分配问题(匈牙利算法),sinkhorn是匈牙利算法的可微分版本
输出
Superglue的输出是,对应匹配的索引和对应匹配的分数
评价
1.成功的引入了self-cross注意力机制,大大改善了特征点匹配的效果
2·提供了新的解决匹配问题的思路
3·成为后面很多工作的参考
4.Superpoint和SuperGIue的应用
基于SP和SG的SFM
利用Superpoint和SuperGIue完成特征点提取和匹配,利用SFM完成建图。然后进行定位
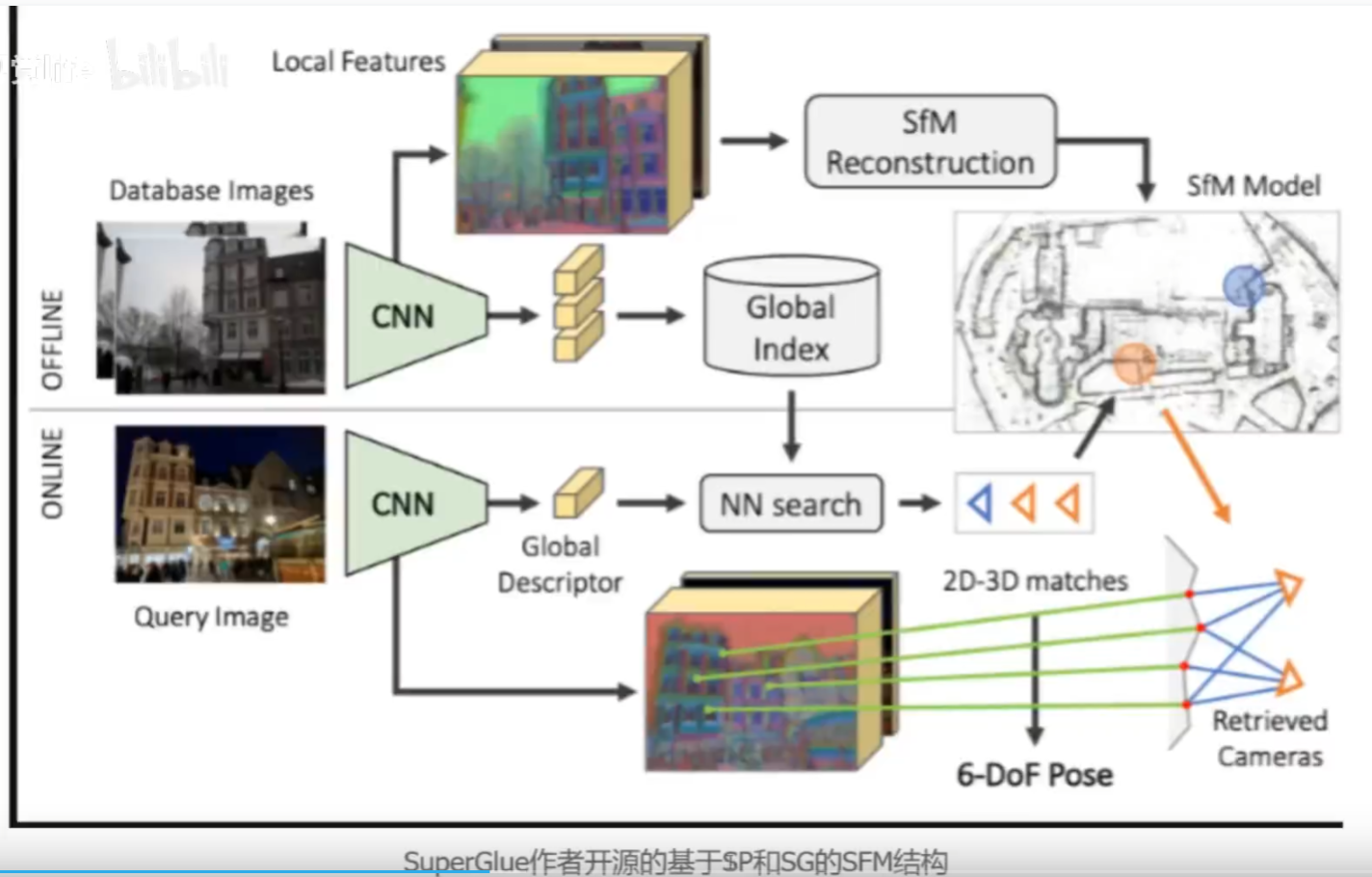
基于SP的SLAM
目前工作基本就是在原有slaM的框架下,把传统的特征点提取算法换成superpoint
最常见就是在ORBSLAM2的基础上,把ORB提取换成superpoint这部分有很多开源的工作,也有论文
比如DXSLAM(IROS2020),利用HF-Net和ORBSLAM2结合
这里用到的HF-Net正好是SuperGIue—作在CVPR2019年发表的工作,是在Superpoint的网络基础上增加了一个全局描述子的decoder

还有GCN—SLAM(还有个GCNv2),也是类似SuperPoint的结果做的提点网络,但是描述子是二值的(01构成),这点跟ORB保持一致
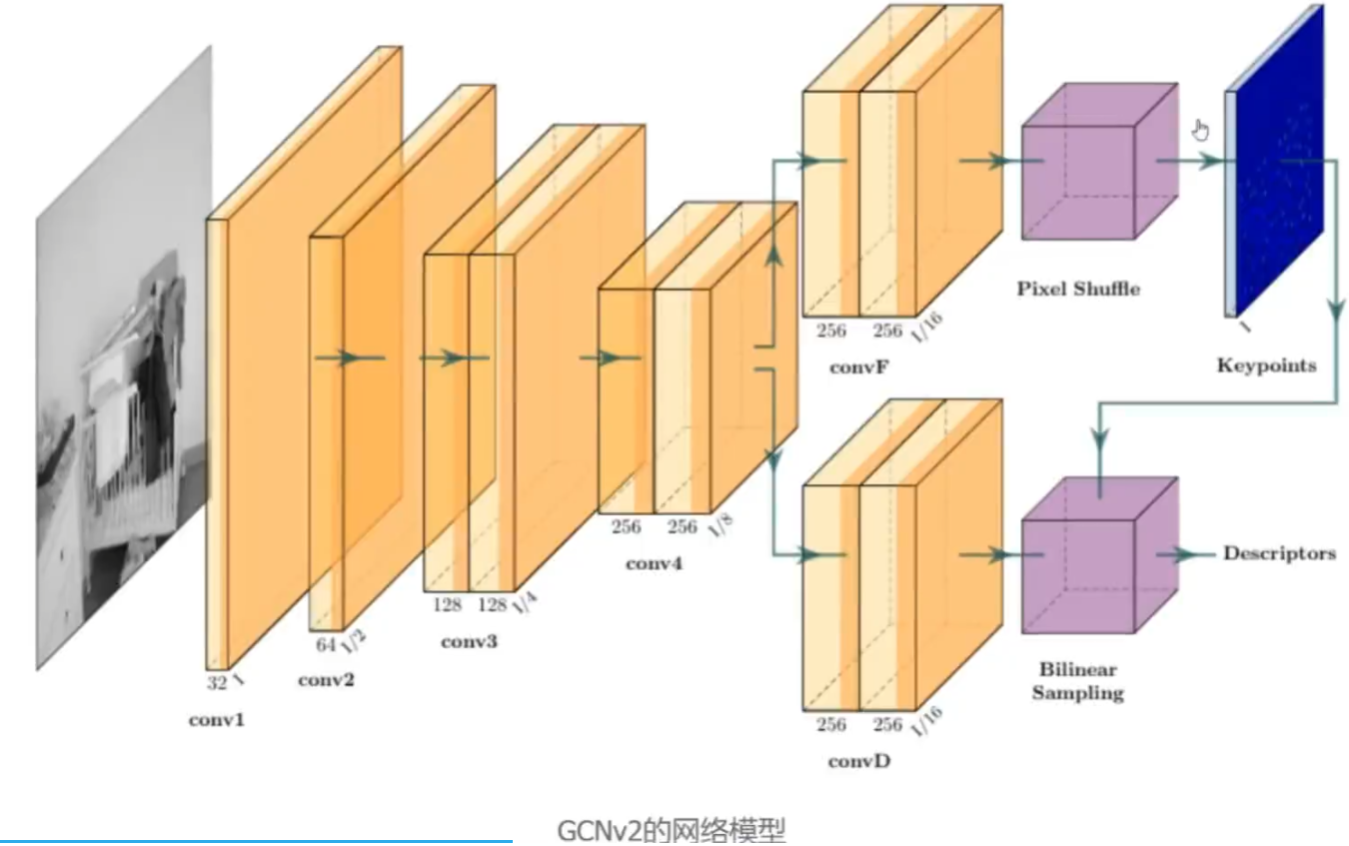
也有开源工作,比如SuperPoint_SLAM,用SuperPoint替换ORBSLAM2中的ORB提点
应用场景
应用场景
1·AR的室内导航(旷视科技例子)
2·室内定位
比如个人早期实验,基于SuperGIue作者的开源工作,对楼层某个区域进行SFM建图,先采集了图像,然后用SFM建图。这里就是用superpoint提点和superglue匹配的
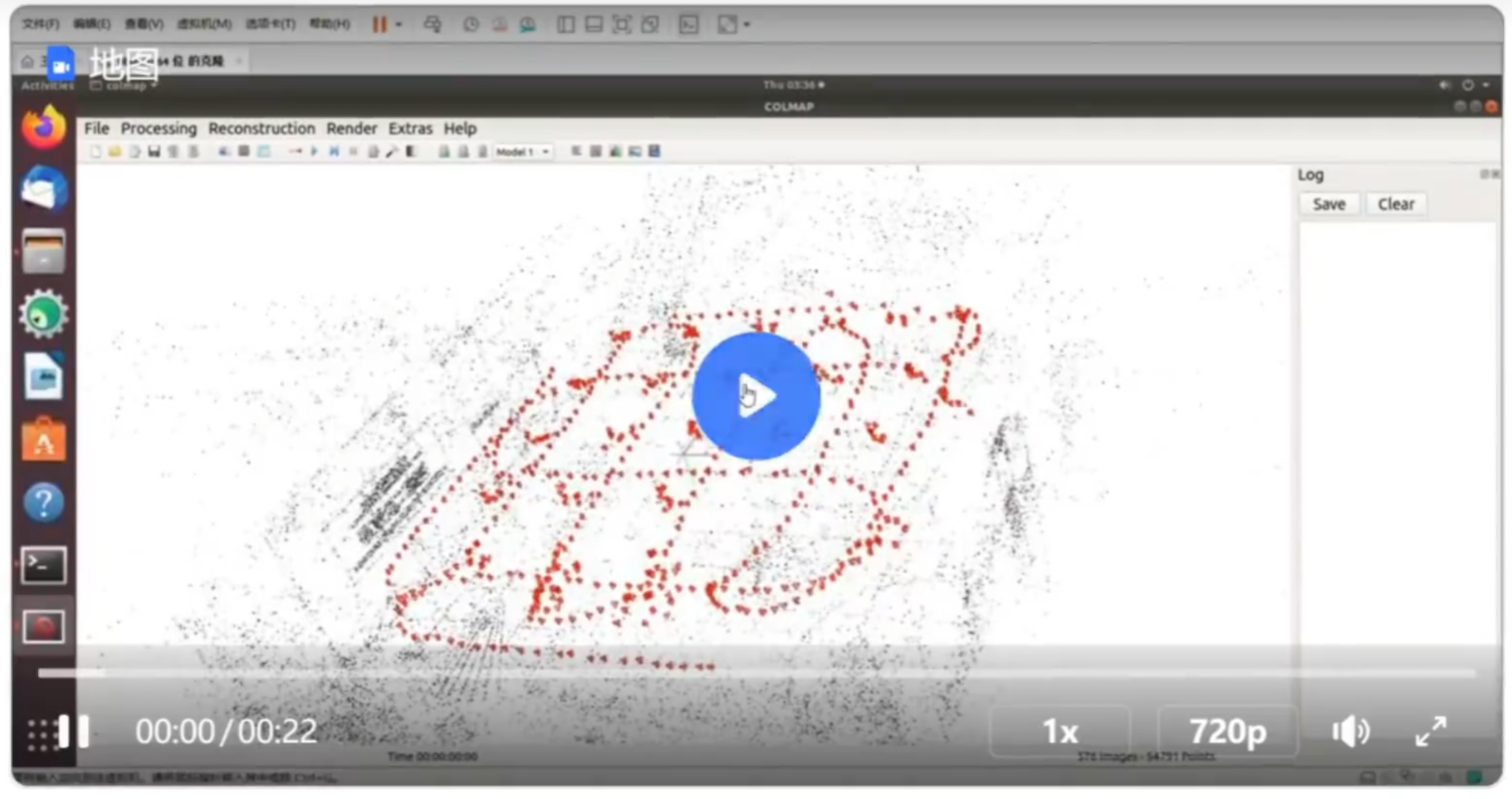
通过拍摄图片,完成定位。这里的图片不是我建图的图片,是我自己重新任意选择位置拍摄
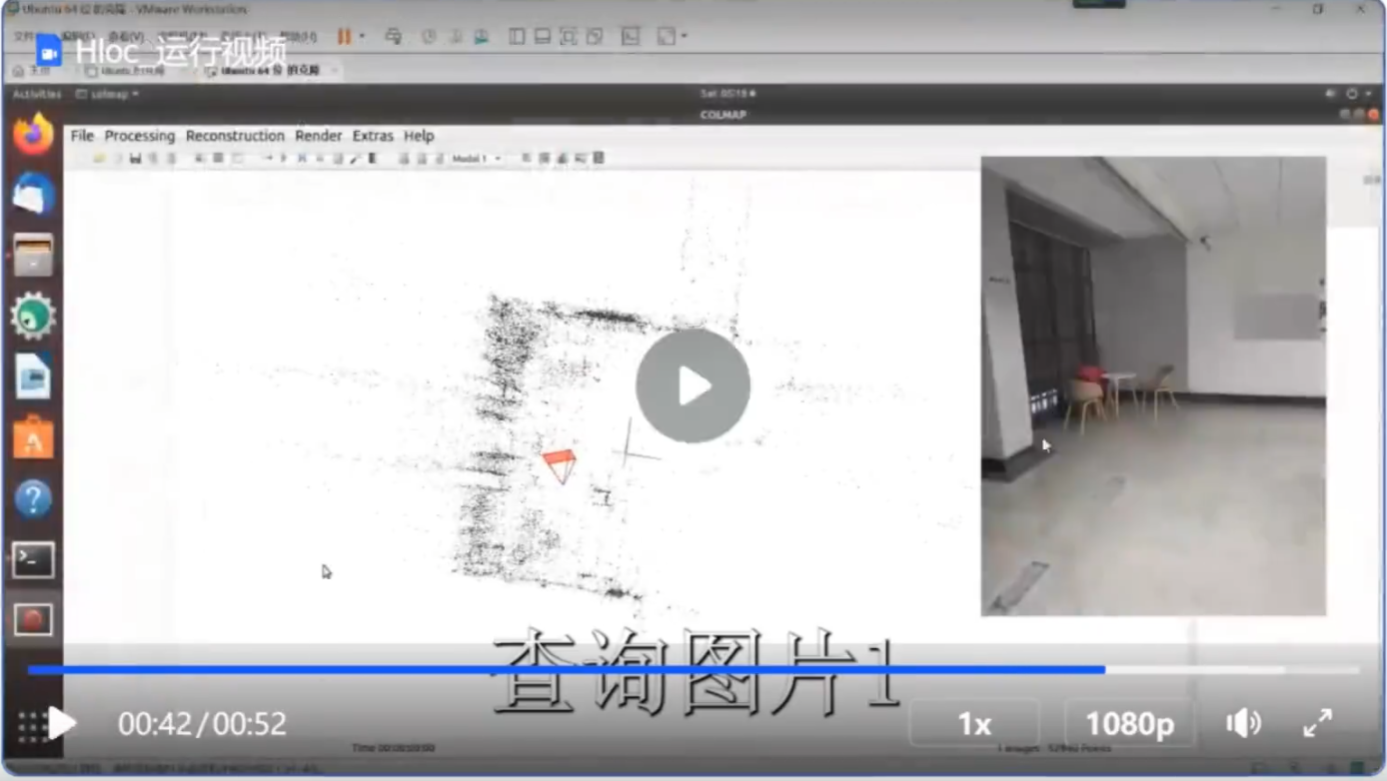
3·移动机器人
4·AR/VR,…
5.研究现状和未来
1·SuperPoint和superglue在特征点提取和匹配方面,还是有很好的表现
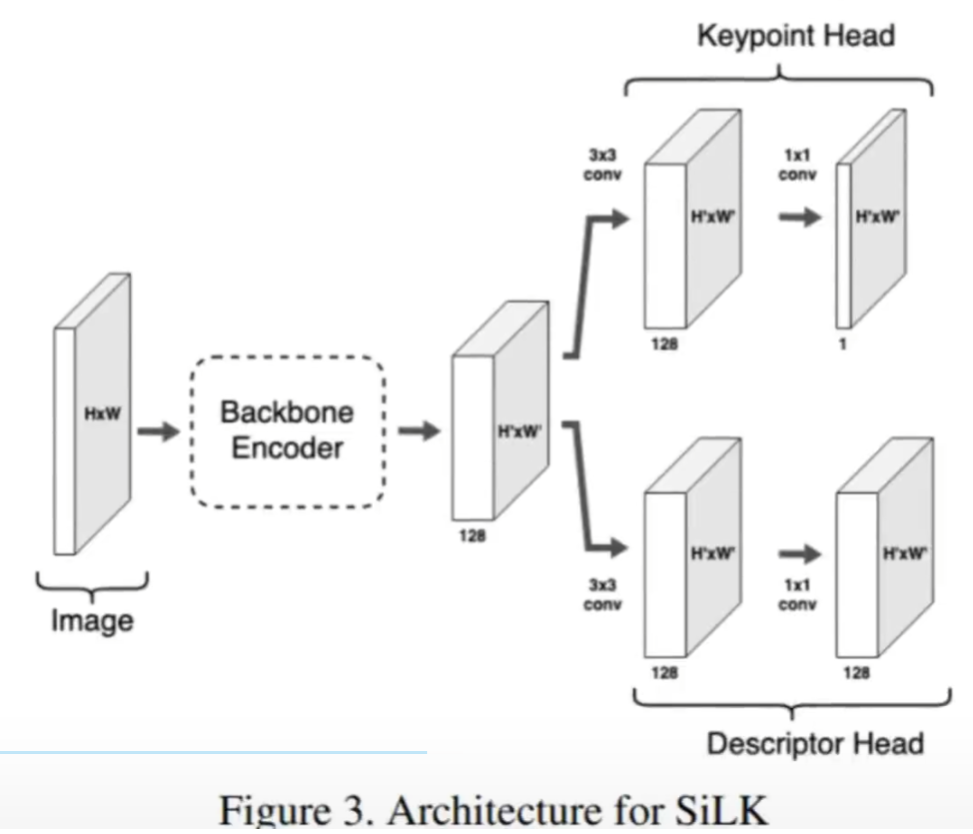
2·后续的特征点提取工作基本都会借鉴SuperPoint的Encoder-Decoder模型比如,SiLK: Simple Learned Keypoints,ICCV 2023,也是基于这个结构的,跟SuperPoint很像
3·Superglue之后也有很多在此基础上开发的工作,主要借鉴的是self-cross注意力机制,Transformer结构比如LoFTR(商汤和浙大,CVPR2021)。最近Superglue的团队发表了LightGlue(ICCV2023),实现了更加的轻量化;FeatureBooster(CVPR2023),也是借鉴了self-cross和Transformer思想,来增强描述子
目前轻量化是个重点关注的地方,因为目前的应用场景都是些嵌入式设备,要想落地的话还是要尽可能保证轻量化。
另外一个就是,基于神经网络的SLAM将这些网路模型结合SLAM,实现可以更优秀的SLAM。
6·学习应用经验
这里主要分享一下我从刚开始学习这个领域到现在的一些经验和感想,仅代表个人的一些思考。
1·对某个领域的发展有一定的了解。特别是学习一个新的领域,要对这个领域的发展情况有一定的了解,从传统到现状。最好的方式就是阅读经典之作。这样可以打破陌生感,也是为你后续工作打下基础,经典之作的特点,对之前的工作进行了总结提升或者提出了创新的方法
2·追踪前沿工作。每年的三大顶会,ICCV,CVPR,ECCV,要去关注最新提出的算法,学习他们的思想
3·要尽可能去搜索论文,去快速阅读,每天留出固定的时间,专门搜索。不要固步自封。有了积累,才能产生自己的想法。
4.动手能力也很重要,特别是如果关注落地的话,包括运行速度,真实场景的准确度等。不知道做什么的时候,多去尝试复现别人的工作。跟自己研究相关的,要尽可能复现,锻炼自己的工程和代码能力。
5·多交流,如果有一批小伙伴一起交流学习的话,相互之间碰撞,对这个领域认识会更加深刻。


















 2131
2131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









