









图表示学习-GraphEmbedding
GraphEmbedding方法根据图结构,生成新的节点特征,使相似度高的顶点拥有相似的Embedding。
Word2vec(2013)
Word2vec是Word Embedding 方式之一,属于 NLP 领域。他是将词转化为“可计算”“结构化”的向量的过程。
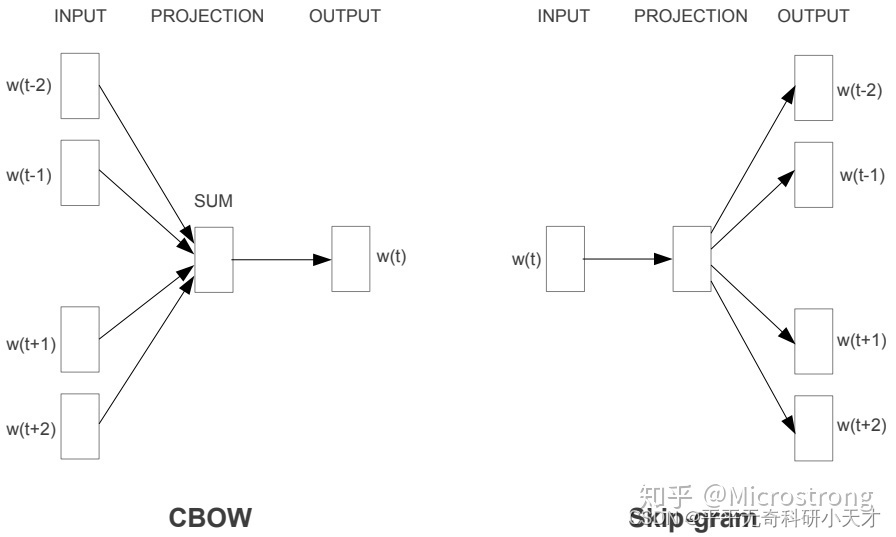
Word2Vec是轻量级的神经网络,其模型仅仅包括输入层、隐藏层和输出层。词向量原始输入为One-hot encoder。模型框架根据输入输出的不同,主要包括CBOW和Skip-gram模型。 CBOW的方式是在知道词
ω
t
\omega _t
ωt的上下文
ω
t
−
2
\omega _{t-2}
ωt−2,
ω
t
−
1
\omega _{t-1}
ωt−1,
ω
t
+
1
\omega _{t+1}
ωt+1,
ω
t
+
2
\omega _{t+2}
ωt+2的情况下预测当前词
ω
t
\omega _t
ωt。而Skip-gram是在知道了词
ω
t
\omega _t
ωt的情况下,对词的上下文
ω
t
−
2
\omega _{t-2}
ωt−2,
ω
t
−
1
\omega _{t-1}
ωt−1,
ω
t
+
1
\omega _{t+1}
ωt+1,
ω
t
+
2
\omega _{t+2}
ωt+2进行预测,如下图所示:
CBOW模型
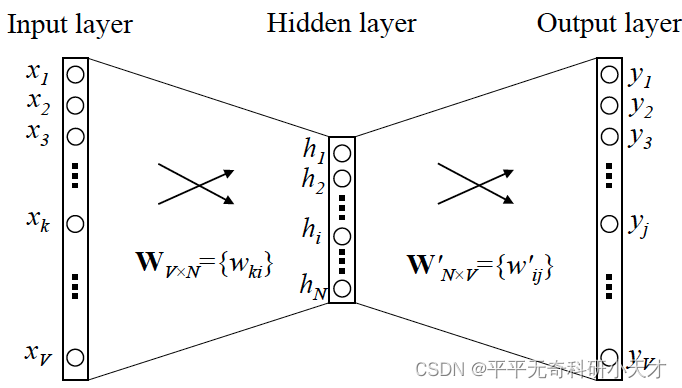
- 1V1的CBOW模型(输入1个词,输出1个词)
输入为单词x的维度为V的One-hot编码,通过一层神经网络映射到维度为N的隐藏层h,再通过一层神经网络映射到维度为V的输出向量,通过Softmax得到最终输出,概率值最大的则为预测词。
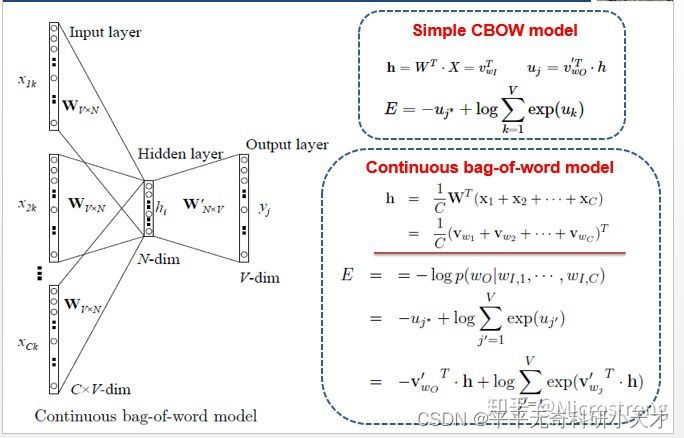
- NV1的CBOW模型(输入N个词,输出1个词)
对比1V1的CBOW模型,NV1的CBOW只是先将多个单词的输入进行加和,通过一层神经网络后再平均获得隐含层h;其余部分与1V1的CBOW模型相同。
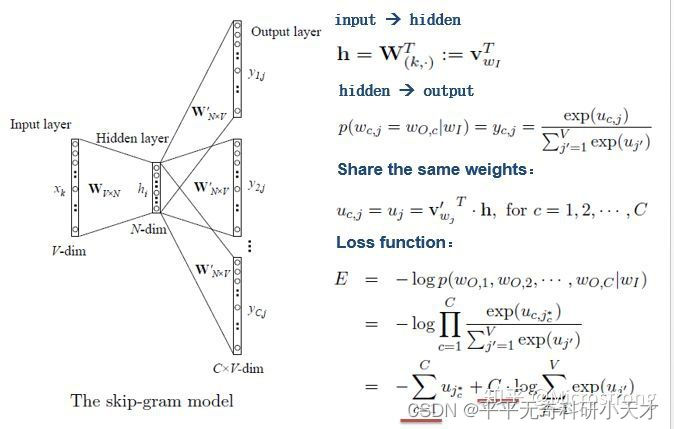
Skip-gram模型
输入为1个词,输出为N个词。
可以把Skip-gram看做预测多次的1V1的CBOW模型,每次预测1个上下文单词出现的概率。用同一个单词作为输入,预测C次后得到C个上下文单词出现的概率,利用Softmax使之和为1。将C个单词的总损失作为损失函数。
参考
https://zhuanlan.zhihu.com/p/26306795
https://easyai.tech/ai-definition/word2vec/
https://zhuanlan.zhihu.com/p/114538417
https://blog.csdn.net/weixin_43578660/article/details/106817045
DeepWalk(2014,KDD)
基于随机游走的经典GraphEmbedding方法,使用DFS随机游走在图中进行节点采样,使用word2vec在采样的序列学习图中节点的向量表示。
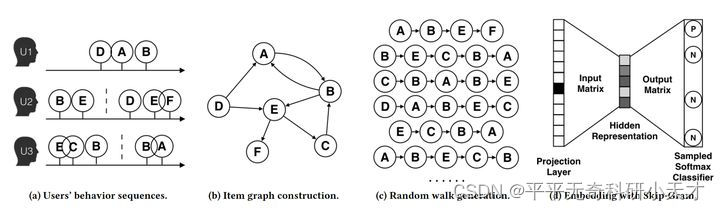
- 图a展示了原始的用户行为序列
- 图b基于这些用户行为序列构建了物品相关图,可以看出,物品A,B之间的边产生的原因就是因为用户U1先后购买了物品A和物品B,所以产生了一条由A到B的有向边。如果后续产生了多条相同的有向边,则有向边的权重被加强。在将所有用户行为序列都转换成物品相关图中的边之后,全局的物品相关图就建立起来了。
- 图c采用随机游走的方式随机选择起始点,DFS构造邻域,重新产生物品序列。
- 图d最终将这些物品序列输入word2vec模型,生成最终的物品Embedding向量。
LINE(2015)
使用BFS构造邻域,可以应用于带权图中(DeepWalk仅能用于无权图)
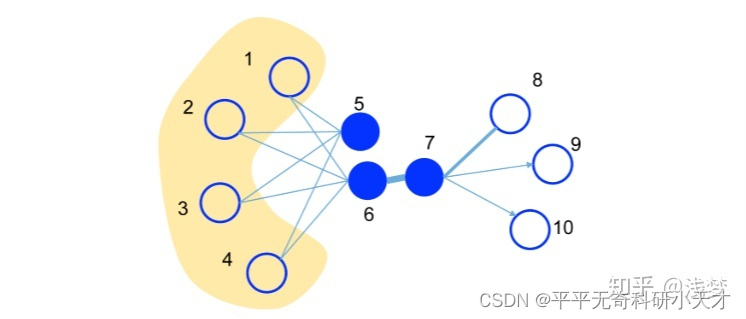
1阶相似度衡量的是,相邻的两个顶点对之间相似性。
2阶相似度衡量的是,两个顶点他们的邻居集合的相似程度。
TADW(2015,IJCAI)
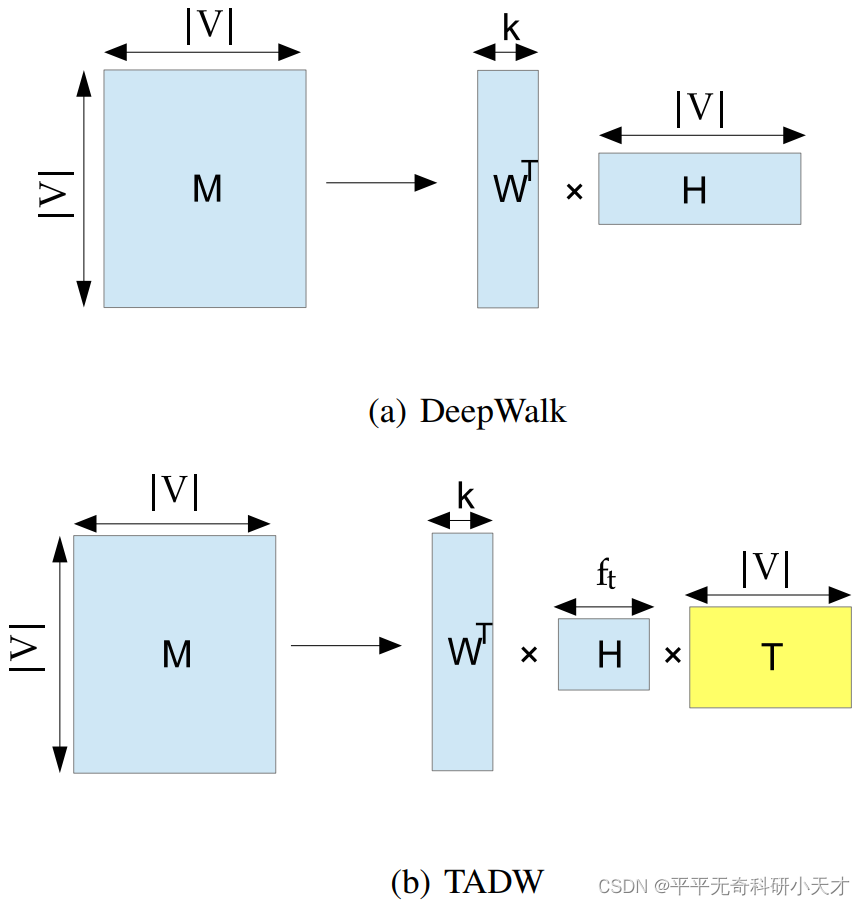
- 主要思想:
考虑了节点本身蕴含的信息(文中为文本信息),将 Deepwalk 思想采用矩阵分解方法进行实现,并在矩阵分解的过程中引入了节点的文本信息,提高了 embedding 的表达效果。 - 优点:
引入了节点蕴含的信息。在应用数据图中,如果节点的类别不仅仅是应用,还包括各种组件,引入节点信息将有助于最终 embedding 的表达结果。 - 缺点:
涉及矩阵分解操作,当数据图过大时时间复杂度过高,难以应用。可扩展性差
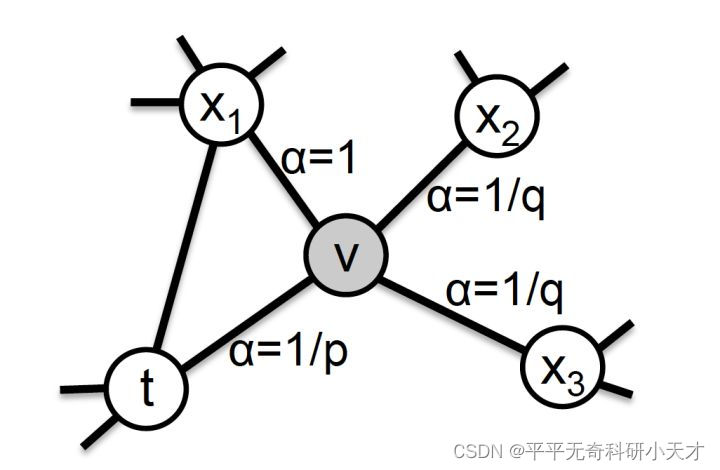
Node2vec(2016,KDD)
DeepWalk的改进算法,调整随机游走权重,权衡网络的同质性(homophily)和结构性(structural equivalence),权衡DFS与BFS
SDNE(2016,KDD)
SDNNE是LINE的改进算法,是第一个将深度学习应用于网络表示学习中的方法。SDNE使用一个自动编码器来同时优化1阶和2阶相似度(LINE是分别优化的),学习得到的向量表示能够保留局部和全局结构,并且对稀疏网络具有鲁棒性。
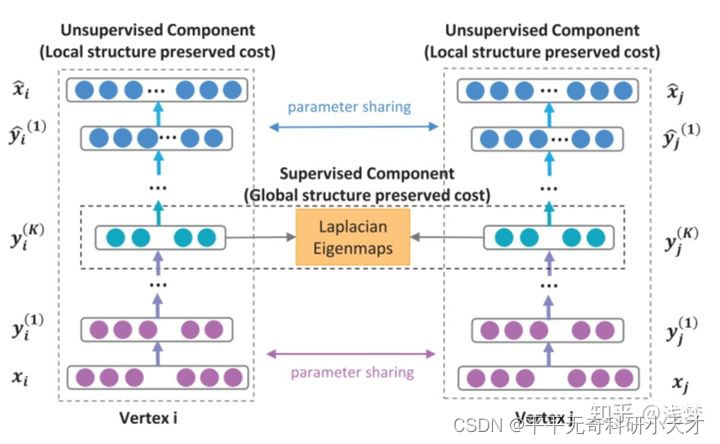
先看左边,是一个自动编码器的结构,输入输出分别是邻接矩阵和重构后的邻接矩阵。通过优化重构损失可以保留顶点的全局结构特性(论文的图画错了,上面应该是Global structure preserved cost)。
再看中间一排, 就是我们需要的embedding向量,模型通过1阶损失函数使得邻接的顶点对应的embedding向量接近,从而保留顶点的局部结构特性(中间应该是 Local structure preserved cost)
Struc2Vec(2017,KDD)
以上方法均是基于近邻相似的假设。事实上,在一些场景中,两个不是近邻的顶点也可能拥有很高的相似性,对于这类相似性,上述方法是无法捕捉到的。Struc2Vec就是针对这类场景提出的。
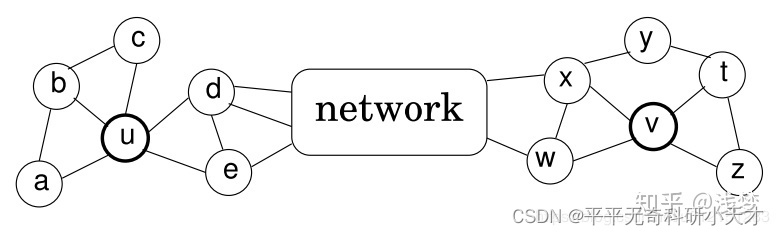
基于近邻相似的假设中,u和v不相似,因为他们无共享邻居且距离远;但在基于空间结构相似的假设中,u和v是相似的。
参考
- https://zhuanlan.zhihu.com/p/64200072
- DeepWalk:https://zhuanlan.zhihu.com/p/56380812
- LINE:https://zhuanlan.zhihu.com/p/56478167
- SDNE:https://zhuanlan.zhihu.com/p/56637181
- 代码:https://github.com/shenweichen/GraphEmbedding















 381
381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









