










1. 简介
1.1 定义
步长(Learning rate):步长决定了在梯度下降迭代的过程中,每一步沿梯度负方向前进的长度
是超参数 0.1 0.01
特征(feature):
- 指的是样本中输入部分
假设函数(hypothesis function):根据经验观察得到的目标值和特征值之间的关系的表达式
损失函数(loss function):
- 为了评估模型拟合的好坏,通常用损失函数来度量拟合的程度。
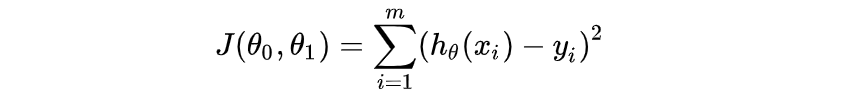
1.2 推导流程
1 构建假设函数,表示的是标签值和特征值之间的关系
2 根据假设函数构建损失函数
3 求损失函数对参数的偏导数
4 带入到更新公式中对参数进行更新
5 按照更新公式写代码实现
2. 分类
- 全梯度下降算法(Full gradient descent)
- 计算训练集所有样本误差,对其求和再取平均值作为目标函数。
- 随机梯度下降算法(Stochastic gradient descent),
- 每次只代入计算一个样本目标函数的梯度来更新权重,再取下一个样本重复此过程
- 小批量梯度下降算法(Mini-batch gradient descent),
- 每次从训练样本集上随机抽取一个小样本集,在抽出来的小样本集上采用FG迭代更新权重。
- 随机平均梯度下降算法(Stochastic average gradient descent)
- 在内存中为每一个样本都维护一个旧的梯度,随机选择第i个样本来更新此样本的梯度,其他样本的梯度保持不变,然后求得所有梯度的平均值,进而更新了参数。
3. 线性回归api
sklearn.linear_model.LinearRegression(fit_intercept=True)
- 通过正规方程优化
sklearn.linear_model.SGDRegressor(loss=“squared_loss”, fit_intercept=True, learning_rate =‘invscaling’, eta0=0.01)
- SGDRegressor类实现了随机梯度下降学习
4. 应用
案例:波士顿房价预测
步骤
0 准备工作:查看数据,特征列都和房价有关系,所有使用全部特征
1.获取数据
2.数据集划分 train_test_split
3.特征工程-标准化 StandardScaler
4.机器学习-线性回归(正规方程/梯度下降)
LinearRegression/SGDGregressor
5.模型评估
mean_squared_error(y_test, y_predict)
5. 欠拟合和过拟合
5.1 简介
- 过拟合:一个假设在训练数据上能够获得比其他假设更好的拟合, 但是在测试数据集上却不能很好地拟合数据(体现在准确率下降),此时认为这个假设出现了过拟合的现象。(模型过于复杂)
- 欠拟合:一个假设在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)

构造数据,构造符合二次曲线的数据
1 用一次线性方程去拟合,这种情况是欠拟合,训练集和测试集误差都比较大
2 用二次方程去拟合,刚刚好
3 用高次方程去拟合,这种情况是过拟合,训练集误差小,测试集误差大
5.2 原因以及解决办法
欠拟合原因以及解决办法
- 原因:学习到数据的特征过少
- 1)添加其他特征项
- 2)添加多项式特征
过拟合原因以及解决办法
- 原因:原始特征过多
- 解决办法:
- 1)重新清洗数据
- 2)增大数据的训练量
- 3)正则化
- 4)减少特征维度,防止维灾难
6. 正则化
6.1 简介
在学习的时候,数据提供的特征有些影响模型复杂度或者这个特征的数据点异常较多,所以算法在学习的时候尽量减少这个特征的影响(甚至删除某个特征的影响),这就是正则化
6.2 分类
1. 正则化类别
- L2正则化
- 作用:可以使得其中一些W的都很小,都接近于0,削弱某个特征的影响
- 优点:越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象
- Ridge回归
- L1正则化
- 作用:可以使得其中一些W的值直接为0,删除这个特征的影响
- LASSO回归
2. 正则化线性模型
2.1 Ridge Regression 岭回归 L2正则化
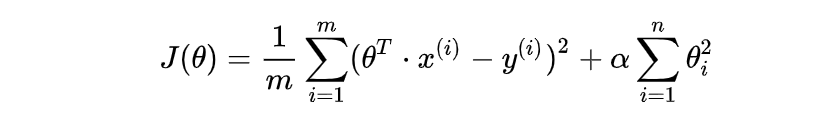
2.2 Lasso Regression(Lasso 回归) L1正则化
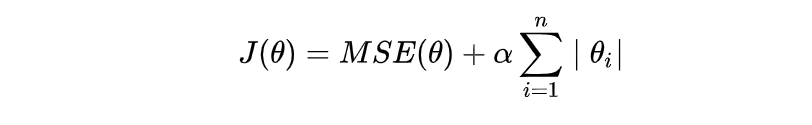
2.3 Elastic Net (弹性网络)
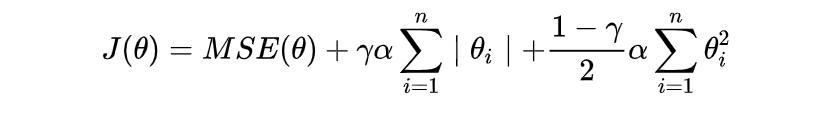
from sklearn.linear_model import Ridge, ElasticNet, Lasso
6.3 岭回归APi
sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver=“auto”, normalize=False)
- 具有l2正则化的线性回归
- alpha:正则化力度,也叫 λ
- λ取值:0~1 1~10
- solver:会根据数据自动选择优化方法
- sag:如果数据集、特征都比较大,选择该随机梯度下降优化
- normalize:数据是否进行标准化
- normalize=False:可以在fit之前调用preprocessing.StandardScaler标准化数据
- Ridge.coef_:回归权重
- Ridge.intercept_:回归偏置
sklearn.linear_model.RidgeCV
cross valiation交叉验证
- 正则化力度越大,权重系数会越小
- 正则化力度越小,权重系数会越大
6.4模型的保存和加载
import joblib
- 保存:joblib.dump(estimator, ‘test.pkl’)
- 加载:estimator = joblib.load(‘test.pkl’)
pkl文件是二进制文件,保存&加载速度快
7. 线性回归应用-回归分析
回归分析的落地场景
- 在各种媒体上投放的广告对最终销售所产生的效果研究
- 公司可以投入的营销渠道
- 通过回归分析可以回答
- 各个营销渠道如何互相营销促进销售
- 如何调整营销组合使每一份支出获取最大收益
- 同时在不同渠道进行广告营销,哪个效果更明显
销售额预测分析
- 快消企业,分析目的
- 对商超门店的销售额进行预测
分析流程:数据概况分析->单变量分析->相关性分析与可视化->回归模型















 1646
1646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









