






这是一种Decoupled training describe-then-detect pipeline(解耦式训练描述然后检测)的过程,把关键点检测网络分离出来,首先训练描述子生成网络,直到得到鲁棒的描述子后再对关键点检测网络进行训练。因为经过描述子对提取特征点也可以起到积极的作用,并且解耦的方式可以使得损失明确,知道损失到底是对应特征点的还是对应描述子的。
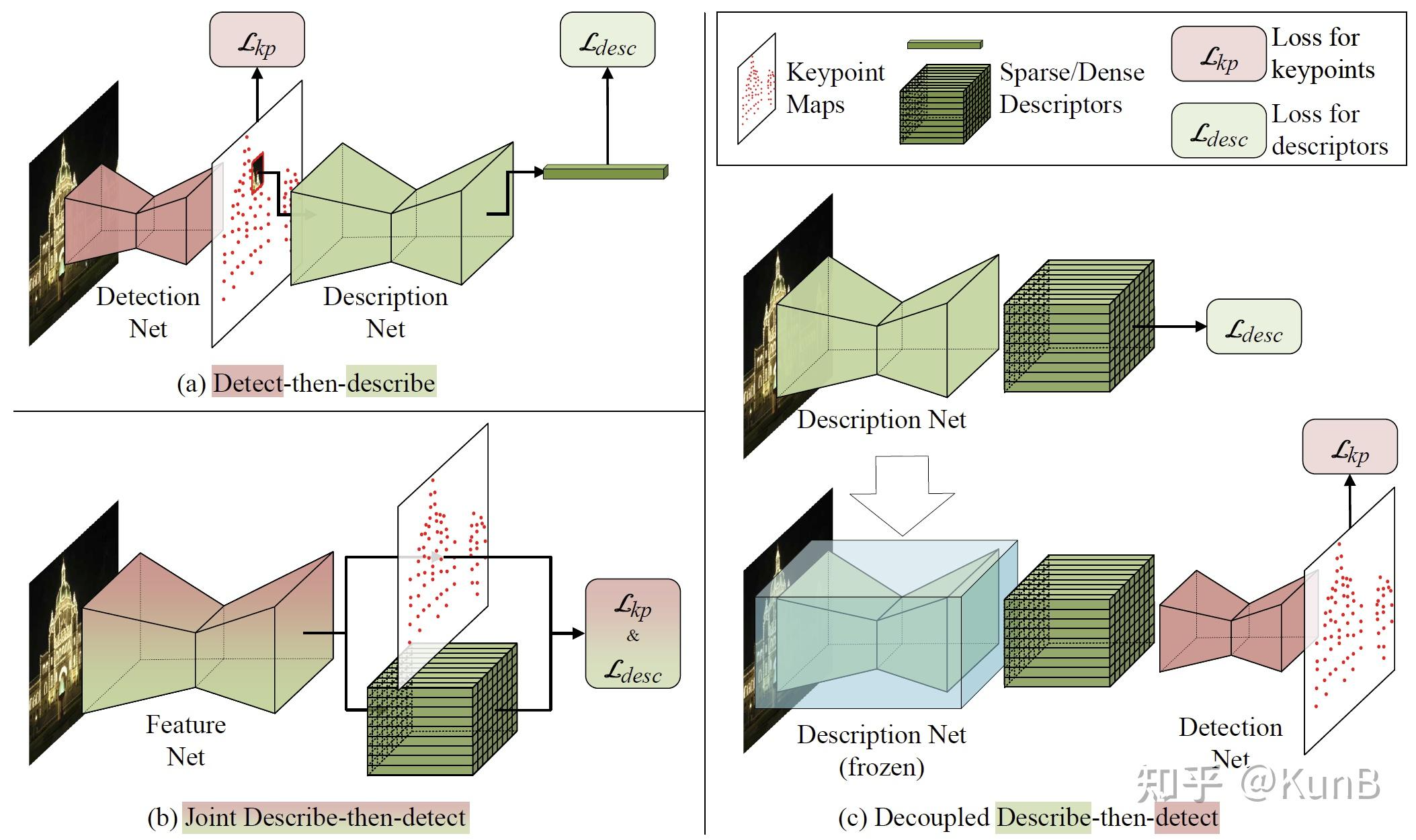
这就是传统三种特征检测匹配的框架,先检测后计算描述子,先训练描述子后检测和解耦式训练描述然后检测。
与detect-then-describe(先检测后计算描述子)仅利用低层结构信息检测关键点不同,本文的框架同时结合了低层结构信息和描述子中的高层语义信息,使得困难场景下的关键点检测更加鲁棒。与joint training describe-then-detect(先训练描述子后检测)不同,本文通过将关键点检测网络和描述子提取网络的训练解耦,避免了弱监督损失函数的模糊性导致的网络性能损失。
在训练的过程中,首先是训练描述子,会建立平均的网格,每个网格选出一个特征点进行训练,这样可能要比SIFT提取特征点训练描述子更好,因为SIFT方法提取的关键点分布可能不均匀,导致某些区域缺乏关键点。在这些缺乏关键点的区域,描述子网络可能无法很好地生成准确的描述子,因此在关键点检测时可能会产生错误的响应或表现不佳。
Line-to-window搜索策略
由于描述子网络的训练目的,是希望匹配点的描述子之间尽可能相似,而非匹配点的描述子之间尽可能不相似。因此,我们在没有匹配真值的情况下,需要首先寻找匹配关系。CAPS采用了一种coarse-to-fine(粗到细)的搜索方式,这种方式效率很高,但容易引入训练噪声。假设在粗略搜索过程中,就定位错了位置,那么精细搜索得到的匹配点一定是不准确的,由此计算的损失函数就只能是训练噪声,会降低描述子网络的性能。为了缓解这一问题,作者提出了line-to-window(线到窗口)搜索策略,通过充分利用相机位姿提供的几何信息,使得训练更加有效。
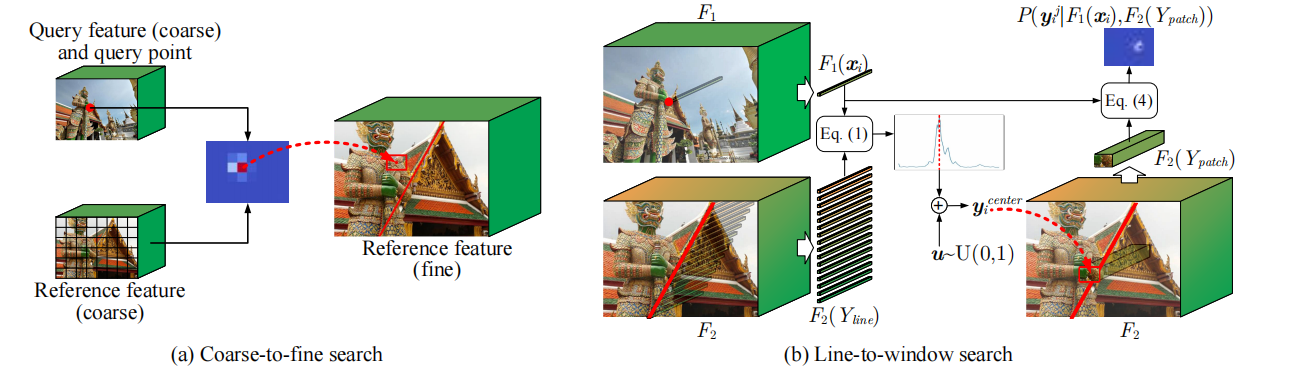
这就是由粗到细匹配(a)和线到窗口搜索策略(b)的示意图,其中F2当中的红线代表F1中的特征点在F2中对应的极线。
训练描述子
使用的网络是和CAPS中一样的ResUnet。
1.沿极线搜索
对于任意一个查询点xi(在I1中提取到的点),首先利用相机位姿计算这个点在I2图像中的极线Fxi,然后沿着极线均匀采样Nline个点组成搜索空间。
![]()

2.局部搜索
因为Yline中的坐标点具有离散性,所以选出的坐标
![]()
可能不是准确的,所以需要在一个局部窗口搜索xi的匹配点,首先根据
![]()
确定搜索窗口的中心位置。
![]()

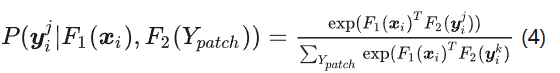
就是用xi处的描述子和Ypatch所有点的描述子进行计算相关性,然后再softmax一下。
由于这一步得到的匹配中心要参与损失函数计算并且进行反向传播,所以需要用一种可微的方式进行计算:
![]()
上述公式就是计算平均期望,Ypatch这个图像块中所有的点的坐标乘上这个点对应的匹配概率,然后把所有的乘积相加这样就得到了最终匹配点
![]()
。
3.损失函数
因为只有相机位姿作为标签, 所以利用和CAPS中提出的点到极线的距离作为目标函数。
![]()
Lxi就是xi再I2中对应的极线,
![]()
就是计算出的匹配点。distance就是计算距离。
下面将各个查询点的损失加权求和得到最终的损失函数
![]()
。

其中Mi是一个二值Mask,当xi的极线在图像I2的可见范围内时这个值就是1,否则这个值为0.
关键点检测部分



随后,我们计算两个集合的点对之间的几何得分,同样是按照点到对极线之间的距离来进行评价;

其中λp=1,λn=-0.25,λreg=-0.001,,其中Lrew(xi,yi)是奖励损失,λreg是正则化惩罚项。
λp=1,λn=-0.25的设定说明了对于训练中的关键点匹配对,当关键点yj与对极线接近时,我们希望给予一个较高的奖励(λp),以鼓励模型将这样的匹配对视为更重要的训练样本。而当关键点yj远离对极线时,我们希望给予一个较小的惩罚(λn),以降低这样的匹配对的训练权重,因为它们可能是无关紧要的样本或者是噪声。其中Pm也是如果概率较高则就是鼓励学习这个特征点对,如果低则无关紧要。最主要的就是学习
![]()
鼓励学习选出的点是高概率的。
其实对于任意一对训练图像,我们首先进行网格划分,在每个网格内进行随机选点;对于每一个点,我们都将其与另一幅图中的所有候选点进行相似度计算(匹配),根据匹配概率和对极几何约束,我们给出一个正/负奖励,而网络的优化目标是最大化奖励,因此就要调高正奖励的位置的关键点得分,降低负奖励的位置的关键点得分。因此,我们的关键点检测网络的任务可以看成是,找出图中最容易进行正确匹配的像素作为关键点。
输入图像也是480*640*3,经过和CAPS一样的ResUnet,返回三个特征图,
global_map就是CAPS中的粗级别图经过ResNet50再加上一个卷积为30*40*128:,local_map就是CAPS中的细级别图经过Resnet50和一些上采样加拼接为120*160*128:,和local_map_small只经过resnet50第一个卷积层7*7的再加上最大池化变为120*160*64:
将local_map和local_map_small沿着通道维度拼接变为local_input:2*192*120*160
将local_map和原图像一起输入到局部头部网络。
首先将local_map输入Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))和归一化和激活还是(x)2*192*120*160,然后使用双线性插值将高宽恢复成和图像一样2*192*480*640。
然后将原图像2*3*480*640输入Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))再经过通道维度归一化变为(img_tensor)2*64*480*640,接着将x和img_tensor在通道维度进行拼接变为x=(2,256,480,640),然后把x输入Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),再经过通道维度归一化和relu,变为x=(2,128,480,640),再经过Conv2d(128, 1, kernel_size=(1, 1), stride=(1, 1))和通道维度归一化再经过一个softplus得到一个得分图socre,2*1*480*640,然后把x_pi和x_pf(在这里是全一向量代表是一个权重,在这里是identity全为1)(全是2*1*480*640)和score相乘得到最终的得分矩阵。
inputs如下
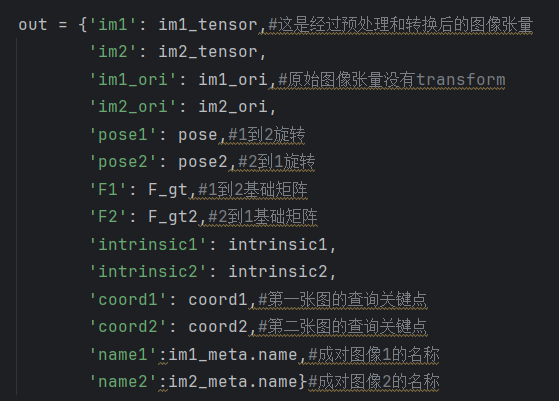
outputs如下

极线到窗口:首先根据选出的特征点和传入的基础矩阵计算每个点在另一张图像上对应的极线,然后计算这个极线与第二张图像四个边的交点,判断这四个交点是否都在图像范围内,然后判断是否有两个交点在图像内,如果没有的就把这个点的valid设置为False,因为只有有两个交点的才能证明极线在图像内,接着返回这些特征点对应的极线与图像的交点坐标,没有的就直接返回左右两个交点坐标。
然后根据返回的交点坐标为第一个交点endpoints_1_n(2,1200,2)和第二个交点坐标,endpoints_2_n也是(2,1200,2),他们相减计算极线的方向line_len,然后设置一个从0到1取均匀取100个数,2维的(100,2),与line_len相乘,换一下格式line_len是(2,1200,1,2),网格为(1,1,100,2),得到了(2,1200,100,2),在把这个值加上endpoints_1_n起始点转换一下形式为(2,1200,1,2)这样就得到了在每个点对应的极线上均匀的取100个点,sample_grids(2,1200,100,2)。
总结一下:首先计算每个点对应的极线,然后计算一下极线与图片的交点,如果少于两个则抛弃,然后把交点返回,根据两个交点相减计算出方向,然后把方向乘上一个递进的0到1的均匀采样的数100个,再加上初始点,就得到了每个极线上采样100个点。
接着对提取到每个特征点对应的100个点进行在细级别图上提取描述子,使用双线性插值(2,1200,100,128)。然后把这些提取的描述子与对第一张图对应的特征点描述子进行求相似度,使用余弦距离。得到prob(2,1200,100),其中最后一个维度被softmax。然后设置一个mask掩码,大小为(2,1200,100)其中最后一个维度最大的为True其他全为False,添加一个维度变成(2,1200,100,1),使用这个与sample_grids相乘,然后在第三个维度加和,因为True是1,False是0,所以相加之后是得到了极线中100个点匹配概率最大的那一个点坐标(这里用的是最近邻),expected_coord为(2,1200,2)。
接着使用下面这行代码把每个点进行一点偏移。(2,1200,2)
![]()
然后计算一个border_mask判断是否这些点都在图像范围内,是的设置成True,不是的设置成False,为(2,1200),然后将border_mask与valid进行与运算,只有极线与图像相交并且得出的点在图像范围内才是True(2,1200)valid
然后计算标准差,首先计算方差,将那提取的100个点的坐标的平方乘上他们经过softmax后对应的概率然后减去最终期望坐标(这里是上面规定的最近邻最大概率)的平方得到方差,然后将这个方差进行开根号并将x和y的方差加在一起就得到了标准差std(2,1200),最后返回(偏移后的点,没偏移的点,valid和方差)。
然后将第一张图提取的特征点的描述子feat1(2,1200,128),第二张图的细级别图featmap2(2,128,120,160),经过极线窗口提取的对应点(经过偏移)coord2_n(2,1200,2),窗口大小window_size=0.1传入计算对应点,在coord2_n周围开辟一个窗口,把这些坐标从featmap2中提取描述子(双线性插值),然后计算相似度prob(1,1200,192),因为窗口是0.1所以是12*16=192.接着把最后一个维度的匹配概率和对应的归一化坐标值进行相乘相加得到最后的匹配点(2,1200,2)。将匹配概率图prob,匹配点,每个窗口的坐标和方差返回。然后将匹配点重新从归一化坐标映射到图像坐标系坐标。
processed如下(计算损失需要的参数)只是在描述子网络训练中
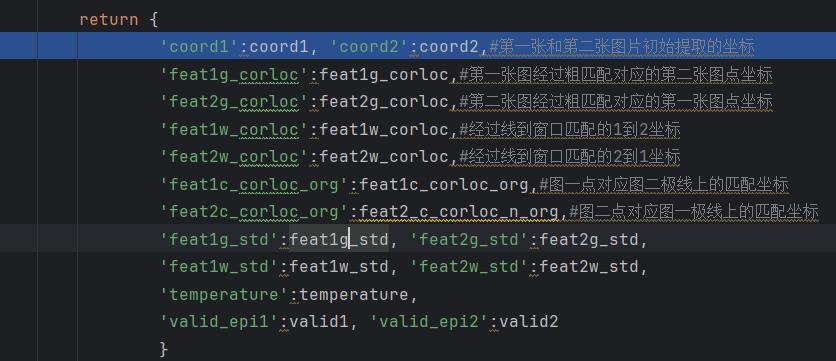
将inputs,outputs和processed传入计算损失
计算点到极线的距离,根据Fx计算出极线,然后将极线(a,b,c)前两个维度归一化因为计算点到线距离的公式是
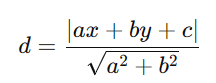
所以这样就不用再除以
![]()
,直接用齐次坐标和归一化后的极线(a,b,c)相乘就可以得出距离。
得到cost_g1,cost_w1,cost_g2,cost_w2,都是(2,1200)分别是第一张图粗匹配和线到窗口匹配的点到极线距离和第二张图粗匹配和线到窗口匹配的点到极线距离。
然后计算每个点损失的权重,

将粗匹配点和线到窗口匹配点分别计算一个mask,然后与上面的valid进行与操作。
然后计算每个点的方差倒数除以方差倒数的平均,再乘上对应的mask,得到每一个点的权重矩阵。
接下来把对应的损失都计算,第一张图和第二张图粗匹配和线到窗口的损失。

对应权重相乘损失
把计算出的每个损失乘上对应权重计算总损失,
![]()
最后返回总损失和一些参数

然后进行一些操作,这里只使用了线到窗口的损失,所以粗匹配权重为0,把总损失进行反向传播计算梯度,然后进行梯度裁剪,更新参数,看看是否更新学习率,至此一轮前向传播结束。
特征点网络
将local_map和local_map_small沿着通道维度拼接变为local_input:2*192*120*160
将local_map和原图像一起输入到局部头部网络。
首先将local_map输入Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))和归一化和激活还是(x)2*192*120*160,然后使用双线性插值将高宽恢复成和图像一样2*192*480*640。
然后将原图像2*3*480*640输入Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))再经过通道维度归一化变为(img_tensor)2*64*480*640,接着将x和img_tensor在通道维度进行拼接变为x=(2,256,480,640),然后把x输入Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),再经过通道维度归一化和relu,变为x=(2,128,480,640),再经过Conv2d(128, 1, kernel_size=(1, 1), stride=(1, 1))和通道维度归一化再经过一个softplus得到一个得分图socre,2*1*480*640,然后把x_pi和x_pf(在这里是全一向量代表是一个权重,在这里是identity全为1)(全是2*1*480*640)和score相乘得到最终的得分矩阵。

本文提出了
1.把极线应用于匹配特征描述子,而不是仅仅用于损失函数约束
2.把描述子和特征点训练分开,这样可以使损失明确到底是描述子还是特征点检测.
3.先训练描述子,然后把描述子和图片一起传入训练提取特征点,而不是仅仅使用图片特征,这样可以有更深层的语义特征.
4.相对于CAPS,本文在输入训练的两张对应图都使用了极线约束,CAPS只是用了1到2的极线约束.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









