







支持向量机(Support Vector Machine)
1.SVM概念
逻辑回归:
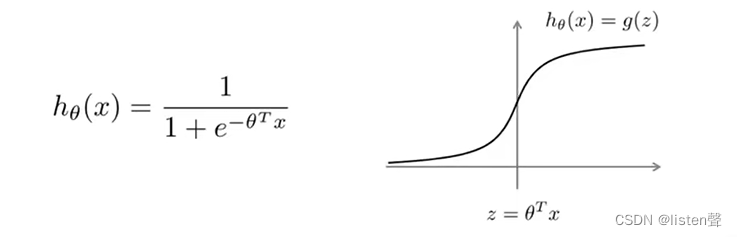
从图上可以看出,当y=1时,如果我们想要
h
θ
(
x
)
=
1
h_\theta(x)=1
hθ(x)=1,需要让z远远大于0;当y=0时,如果我们想要
h
θ
(
x
)
=
0
h_\theta(x)=0
hθ(x)=0,需要让z远远小于0。
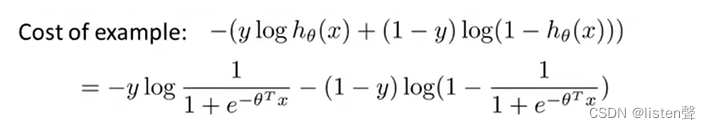
从代价函数上看当y=1时,代价函数为
−
y
l
o
g
1
1
+
e
−
θ
T
x
-ylog\frac{1}{1+e^{-{\theta^Tx}}}
−ylog1+e−θTx1;y=0时,代价函数为
−
(
1
−
y
)
l
o
g
(
1
−
1
1
+
e
−
θ
T
x
)
-(1-y)log(1-\frac{1}{1+e^{-{\theta^Tx}}})
−(1−y)log(1−1+e−θTx1)。
下图中,蓝色图像为逻辑回归的图像,紫色图像为根据逻辑回归构造的SVM的图像,其中 z = θ T x z=\theta^Tx z=θTx。
左图紫色图像为:z>=1时,h(x)=0;z<1时,h(x)为一条和逻辑回归幅度相似的直线。称为
c
o
s
t
1
(
z
)
cost_1(z)
cost1(z),下标1表示这是y=1时的情况。
右图紫色图像为:z<=-1时,h(x)=0;z>-1时,h(x)为一条和逻辑回归幅度相似的直线。称为
c
o
s
t
0
(
z
)
cost_0(z)
cost0(z),下标0表示这时y=0时的情况。
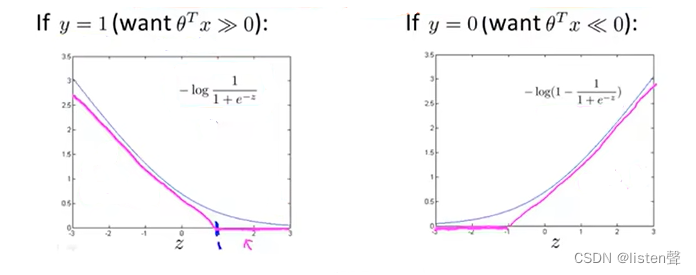
SVM的总体优化目标:
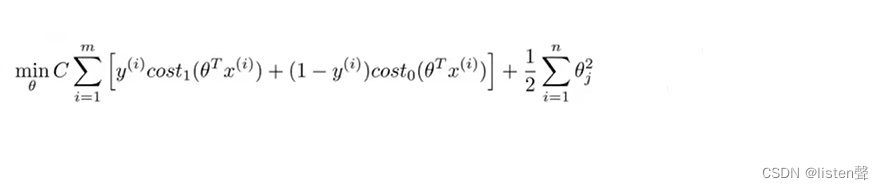
这里C的作用相当于逻辑回归中的
1
λ
\frac{1}{\lambda}
λ1(正则化参数的倒数)。
SVM并不会输出概率,而是通过优化得到一个参数 θ \theta θ,计算 θ T x \theta^Tx θTx, θ T x > 0 \theta^Tx>0 θTx>0则输出1, θ T x < 0 \theta^Tx<0 θTx<0则输出0。
逻辑回归是求概率然后分类,SVM是直接分好类。
2.大间隔分类器
有时会把SVM叫大间距分类器,因为SVM会尽量把正样本和负样本以最大间距分开。
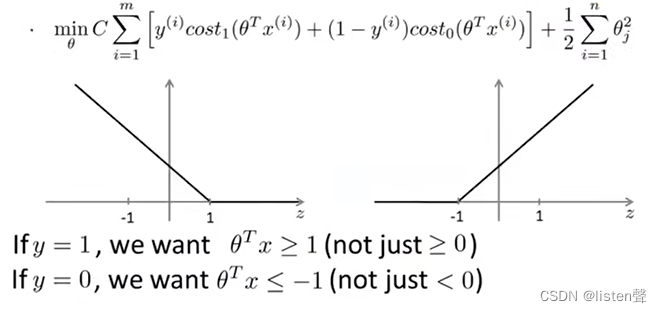
为什么SVM被叫做大间隔分类器
3.用SVM构造复杂的非线性分类器
核函数(Kernel Function):也叫相似度函数,记作 k ( x , l ( i ) ) k(x,l^{(i)}) k(x,l(i))
注: e x p ( − x ) = e − x exp(-x)=e^{-x} exp(−x)=e−x
l ( i ) l^{(i)} l(i)是标记点
f i f_i fi是新的特征
我们通过使用标记点和核函数定义新的特征变量,训练出复杂的非线性边界。
3.1选取标记点
l
(
i
)
l^{(i)}
l(i)
可以直接选取训练样本的值当作标记点。
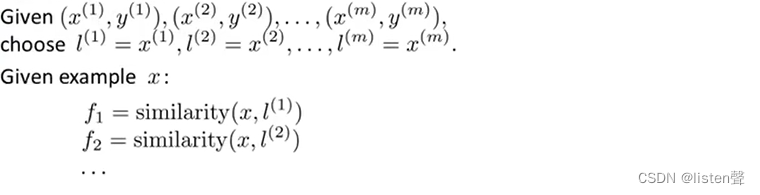
f
i
f_i
fi是新的特征值,
s
i
m
i
l
a
r
i
t
y
(
x
,
l
(
i
)
)
similarity(x,l^{(i)})
similarity(x,l(i))就是核函数。
可以加一个
f
0
=
1
f_0=1
f0=1。将
f
1
.
.
.
f
i
f_1...f_i
f1...fi组成特征向量
f
f
f,
f
∈
R
m
+
1
f∈R^{m+1}
f∈Rm+1,m为样本个数也就是标记点个数,加1是加上了
f
0
f_0
f0。
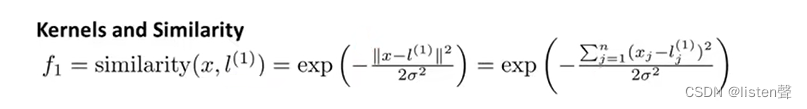
上图就是高斯核函数
当 x x x和 l ( 1 ) l^{(1)} l(1)之间距离很大时, ∣ ∣ x − l ( 1 ) ∣ ∣ → − ∞ , e − ∞ ≈ 0 , f 1 ≈ 0 ||x-l^{(1)}||→-\infty ,e^{-\infty}≈0 ,f_1≈0 ∣∣x−l(1)∣∣→−∞,e−∞≈0,f1≈0;当 x x x和 l ( 1 ) l^{(1)} l(1)之间距离很小时, ∣ ∣ x − l ( 1 ) ∣ ∣ → 0 , e 0 ≈ 1 , f 1 ≈ 1 ||x-l^{(1)}||→0,e^0≈1,f_1≈1 ∣∣x−l(1)∣∣→0,e0≈1,f1≈1;
故而 x x x和 l ( i ) l^{(i)} l(i)经过相似度函数处理后形成的 f i f_i fi要么是0要么是1,由 f 0 . . . f m f_0...f_m f0...fm形成的新的特征向量也就是由0和1组成的列向量。
3.2 SVM中参数的选择

SVM中的C相当于逻辑回归中的
1
λ
\frac{1}{\lambda}
λ1,因此相当于是C越大正则化系数越小→相当于没有正则化→容易产生过拟合问题→低偏差高方差;C越小正则化系数越大→相当于代价函数约等于
θ
0
+
0
\theta_0+0
θ0+0→容易产生欠拟合问题→低方差高偏差。


σ
\sigma
σ越大相似度函数越平滑→高偏差低方差。
σ
\sigma
σ越小相似度函数越陡→高方差低偏差。
4.SVM实践
对于SVM参数优化目标已经有很多比较好的软件库(比如liblinear和libsvm)可以很好的实现了,不推荐大家自己设计算法实现,相当于说编程语言利用库函数一样,有更好更标准代价更低的方法可以使用,还省头发。
但是即使我们不自己设计算法进行优化也需要做几件事:
- 选择参数C
- 选择K函数(线性核函数、高斯核函数或其他核函数)
线性核的SVM:没有选择内核参数、不带有核函数的SVM,没有f还是用的x。这种情况一般是x(特征)数量比较大,但是没有足够的样本,所以设不出来相应的f。
liblinear可以用来训练不带内核参数的SVM。
当特征x数量很小样本数量很大时,一般选择高斯核函数。
选用了高斯函数后需要妥善选择
σ
2
\sigma^2
σ2。
用octave实现高斯核函数:
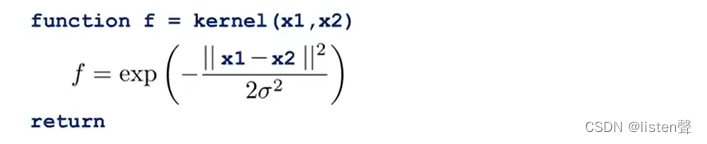
x 1 x_1 x1是 x ( i ) x^{(i)} x(i), x 2 x_2 x2是 l ( i ) l^{(i)} l(i), f f f是 f i f_i fi。
上述函数可以自动生成所有的特征向量。
如果特征变量大小相差很多,需要在使用高斯函数之前进行均值归一化防止过度受某个特征变量的影响
均值归一化忘了的小伙伴点这里。
不是所有的核函数都是有效的核函数,可以用作SVM中的核函数必须满足默塞尔定理,这个定理是确保所有的SVM包能够用大类的优化方法从而快速得到参数 θ \theta θ。
默塞尔(Mercer)定理:任何半正定的函数都可以作为核函数。所谓半正定的函数 f ( x i , x j ) f(x_i,x_j) f(xi,xj),是指拥有训练数据集合 ( x 1 , x 2 , . . . x n ) (x_1,x_2,...x_n) (x1,x2,...xn),我们定义一个矩阵的元素 a i j = f ( x i , x j ) a_{ij} = f(x_i,x_j) aij=f(xi,xj),这个矩阵是 n ∗ n n*n n∗n的,如果这个矩阵是半正定的,那么 f ( x i , x j ) f(x_i,x_j) f(xi,xj)就称为半正定的函数。Mercer定理是核函数的充分条件,只要函数满足Mercer定理的条件,那么这个函数就是核函数。
没有了解过或者忘记怎么判定半正定的点这里。
5.其他核函数
多项式核函数(polynomial kernel):一般形式为 ( x T l + c o n s t a n t ) d e g r e e (x^Tl+constant)^{degree} (xTl+constant)degree。其中constant指常数,degree指多项式次数。 用的不多。
字符串核函数(string kernel):输入数据是文本字符串或其他类型的字符串时可能会用到。
还有卡方核函数(chi-square kernel)、直方相交核函数(histogram intersection kernel)等等,这些难懂的核函数可以用来测量不同目标之间的相似度。
6.用SVM在多元分类中输出判定边界
很多SVM包中内置了多分类的函数,可以直接使用;
也可以使用一对多算法,忘记了的点这里。

7.逻辑回归与支持向量机的选择


对于以上几种情况,使用神经网络也是个不错的选择,不过可能会比SVM慢一些。














 5505
5505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









