







降维(Dimensionality Reduction)
如果有小伙伴和我一样看的吴恩达老师的机器学习课程的话,这一章节是有点问题的:一个是14-6压缩重现应该方在14-5之前看;再就是我看的那系列的14-5是没有字幕的,如果你看的也没字幕的话可以看看这个。
如果特征高度相关就需要进行降维。
我们的特征向量由n个特征组成,这个n也就是特征向量的维度,降维顾名思义就是将特征向量的维度降下来,减少特征的个数。
475
1.数据压缩
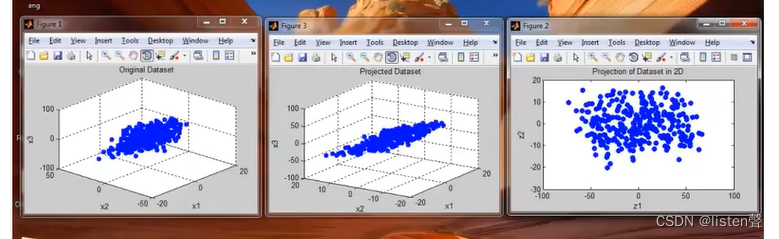
下图中p1中各样本是由
(
x
(
1
)
、
x
(
2
)
、
x
(
3
)
)
(x^{(1)}、x^{(2)}、x^{(3)})
(x(1)、x(2)、x(3))构成,p2表示经过投影将所有样本投到同一个平面中,p3将将p2放到二维条件下显示出来,此时各样本只需用
(
z
(
1
)
、
z
(
2
)
)
(z^{(1)}、z^{(2)})
(z(1)、z(2))两个特征便可以表示出来,这就是降维的过程。
在实际应用中我们可能会使用10000维的特征向量,这个时候降维的作用就显现出来了。
降维不止可以压缩数据节约存储空间,而且可以有效的提高算法执行效率,同时还可以使数据可视化。
数据可视化:将特征向量从好多维降维降到二维,在坐标平面上表示出来即实现数据可视化。
2.主成分分析方法(PCA)
主成分分析(Principal Components Analysis):目前最流行的降维的算法。作用是找到数据投影后能最小化投影误差的方向。

投影误差(projection error):将样本从高维投影到低维的过程中,当原维数>=3时,我们往往先将样本投影到一个平面上将其降成二维,在投影的过程中,样本点与平面的距离就称为投影误差;将二维降到一维时,我们往往将样本点投影到一条直线上,样本点与直线的距离就叫投影误差。
2.1数据预处理
在使用PCA之前先进行数据预处理,均值标准化或特征缩放。

求出所有特征的均值,令特征-=均值,这样特征的均值就等于0了。如果不同的特征有很不同的取值,可以分别进行特征缩放像在监督学习中的特征缩放那样进行特征缩放。
2.2 PCA操作流程
PCA的目的是找到一个平面或是直线使得投影误差最小,操作流程如下:

将数据从n维降维到k维,首先计算协方差矩阵 Σ \Sigma Σ,可以在octave中用[U,S,V]=svd(Sigma)求得。
svd代表singular value decomposition奇异值分解
也可以用eig(Sigma),和svd具有相同的效果,但svd的结果更稳定
Σ \Sigma Σ是一个 n ∗ n n*n n∗n的矩阵,svd输出的是三个矩阵U、S、V,我们真正需要的是U,U也是 n ∗ n n*n n∗n的矩阵。如果我们想将数据从n维降维到k维,只需取U矩阵的前k个向量即前k列,这就是我们的k个方向。
方向找到了后应该寻找特征在方向上的投影 z ( i ) z^{(i)} z(i),原特征向量为 x x x,记U的前k个向量组成的矩阵为 U r e d u c e U_{reduce} Ureduce,则新的特征向量为 z = U r e d u c e T x z=U_{reduce}^Tx z=UreduceTx。
U r e d u c e T U_{reduce}^T UreduceT为 k ∗ n k*n k∗n维, x x x为 n ∗ 1 n * 1 n∗1维, z z z维 k ∗ 1 k * 1 k∗1维为所求。
octave实现:

压缩重现:我们一直将PCA看作是一个压缩算法(降维类似于将数据压缩),压缩重现就是将降维后的这组数据还原成原来的高维数据表示,压缩重现后的特征向量记作
x
a
p
p
r
o
x
x_{approx}
xapprox。
x a p p r o x = U r e d u c e z x_{approx}=U_{reduce}z xapprox=Ureducez
2.3 维度k的选择
法一:
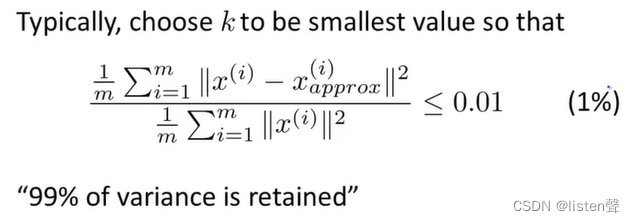

从1开始尝试,计算
U
r
e
d
u
c
e
、
z
(
i
)
、
x
a
p
p
r
o
x
(
i
)
U_{reduce}、z^{(i)}、x_{approx}^{(i)}
Ureduce、z(i)、xapprox(i),直到满足
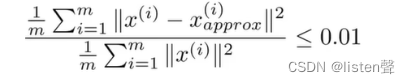
选取满足上式的k值即可。这个方法虽然可以选择到最小的k但是效率很低。
法二:
使用SVM得到S矩阵后,从k=1开始计算
∑
i
=
1
k
S
i
i
∑
i
=
1
m
S
i
i
≥
0.99
\frac{\sum_{i=1}^{k}S_{ii} }{\sum_{i=1}^{m}S_{ii}}\ge0.99
∑i=1mSii∑i=1kSii≥0.99是否成立,如果不成立就
k
+
+
k++
k++直到成立。
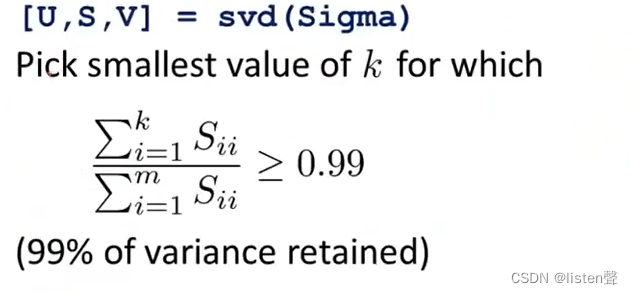
S矩阵是一个 n ∗ n n*n n∗n的矩阵,只有主对角线有值其余值都是0。
虽然法二也需要迭代但是不需要一直反复进行PCA算法,只需要运行一次PCA算法得到S矩阵就可以,接下来算数就行;法一需要一直从头到尾的用PCA算法,效率低很多。
3. PCA与监督学习算法
PCA可以加速监督学习算法,具体如下:
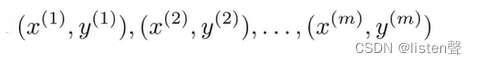
一组监督学习样本⬆
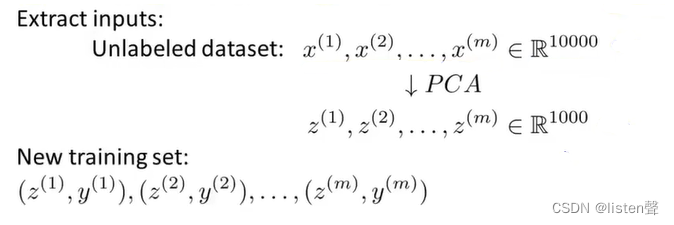
将这组样本去掉标签用PCA降维形成新样本后将标签一一对应回去⬆
此时的监督学习的特征向量的维度已经下来了,再选取一个监督学习的算法(线性回归、逻辑回归等)进行学习即可,效率比使用PCA之前会高很多。

最好是只有当 x ( i ) x^{(i)} x(i)不生效(磁盘空间占据过大、算法速度太慢等)时才将PCA用在监督算法上。
4.对PCA算法的误用
有时人们会使用PCA去防止过拟合,但这是不对的!
在非必要的时候对监督算法使用PCA也并不推荐!














 5572
5572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









