







过拟合问题及其解决方法
在使用逻辑回归和线性回归算法过程中可能会出现过拟合问题。
1.过拟合问题
如果一个算法没有很好的拟合数据,偏差较大,那么称这个问题为欠拟合问题(underfitting)。如果一个算法能够拟合所有的数据但是具有高方差,变量过多而缺少足够的数据去约束,模型过度依赖数据而不能很好的应用于新的样本中,就会出现过拟合问题(overfitting)。
如下图分别是线性回归和逻辑回归的三种情况:第一列是欠拟合问题,第二列正好,第三列则是过拟合问题。


过拟合问题本质上就类似根据数据设计了一个算法,对于这些数据是拟合的但是其余的数据不能拟合,泛化的不好。
2.解决方法
当我们面对一维或二维数据时,我们一般通过绘制出假设模型的图像研究问题并选择合适的多项式阶数。
当过拟合问题发生时,有两个解决办法。
1.减少变量的个数
可以人工减少变量个数选取也可以使用模型选择算法(后续会讲)进行筛选。
但这种方法可能会舍去我们不想舍弃的条件。
2.正则化
不舍弃变量但是减少量级或者是参数的大小。这个方法在有很多特征量的时候会很有效,其中每个变量都会对预测值产生或大或小的影响。
3.正则化

如上图,第二个图出现过拟合问题,但是我们同时又不想减少参数的个数想要看到每一个参数对于预测值的影响从而得到更加精准的预测值该怎么办呢?这个时候就可以加入一个惩罚项。
正常的代价函数: J ( θ ) = m i n 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta)=min\frac{1}{2m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2 J(θ)=min2m1∑i=1m(hθ(x(i))−y(i))2
产生过拟合问题的假设函数是 θ 0 + θ 1 x + θ 2 x 2 + θ 3 x 3 + θ 4 x 4 \theta_0+\theta_1x+\theta_2x^2+\theta_3x^3+\theta_4x^4 θ0+θ1x+θ2x2+θ3x3+θ4x4,但是我们又不想舍弃 x 3 x_3 x3和 x 4 x_4 x4这两个特征值,因此对这两个特征值的参数 θ 3 、 θ 4 \theta_3、\theta_4 θ3、θ4增加惩罚项。
此时的代价函数: J ( θ ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 + 1000 θ 3 2 + 1000 θ 4 2 J(\theta)=\frac{1}{2m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2+1000\theta_3^2+1000\theta_4^2 J(θ)=2m1∑i=1m(hθ(x(i))−y(i))2+1000θ32+1000θ42
1000取几都行,也就是后面说到的 λ \lambda λ,会讲到怎么取值。
我理解的 θ 3 \theta_3 θ3和 θ 4 \theta_4 θ4取平方的原因是为了防止求最小值让他俩是负无穷代价函数就是负的了。
此时想求得最小的代价
m
i
n
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
1000
θ
3
2
+
1000
θ
4
2
min\frac{1}{2m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2+1000\theta_3^2+1000\theta_4^2
min2m1∑i=1m(hθ(x(i))−y(i))2+1000θ32+1000θ42
就需要让
θ
3
2
\theta_3^2
θ32和
θ
4
2
\theta_4^2
θ42最小,也就是接近于0。当
θ
3
2
\theta_3^2
θ32和
θ
4
2
\theta_4^2
θ42接近于0时
θ
3
\theta_3
θ3和
θ
4
\theta_4
θ4也就接近于0,假设函数
θ
0
+
θ
1
x
+
θ
2
x
2
+
θ
3
x
3
+
θ
4
x
4
\theta_0+\theta_1x+\theta_2x^2+\theta_3x^3+\theta_4x^4
θ0+θ1x+θ2x2+θ3x3+θ4x4就相当于
θ
0
+
θ
1
x
+
θ
2
x
2
+
\theta_0+\theta_1x+\theta_2x^2+
θ0+θ1x+θ2x2+一个很小的数,做到了没有缩减特征值的数量又减小了出现过拟合问题的概率。这就是正则化。
正则化的代价函数:
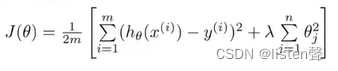
其中的
λ
\lambda
λ就是正则化参数,作用是控制两个不同目标之间的取舍。第一个目标是我们想要更好的拟合数据,第二个目标是将参数控制的更小。
λ
\lambda
λ的作用就是在平衡这两个目标从而保持假设函数模型的相对简单,避免出现过拟合问题。
如果 λ \lambda λ太大可能会导致对参数的惩罚程度太大,最后让他们都接近于0,这样就相当于把假设函数的所有项都忽略了,最后假设模型只剩一个 θ 0 \theta_0 θ0,会出现欠拟合问题。所以如何选择正则化参数是很重要的,后面会详细讲解。
4.正则化线性回归的梯度下降算法
未进行正则化的梯度下降算法更新规则:

正则化线性回归的梯度下降算法:
由于我们正则项那里是将
θ
1
.
.
.
θ
n
\theta_1...\theta_n
θ1...θn加一起,所以要将
θ
0
\theta_0
θ0单独拿出来。
变成了Repeat{
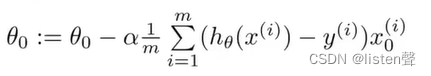
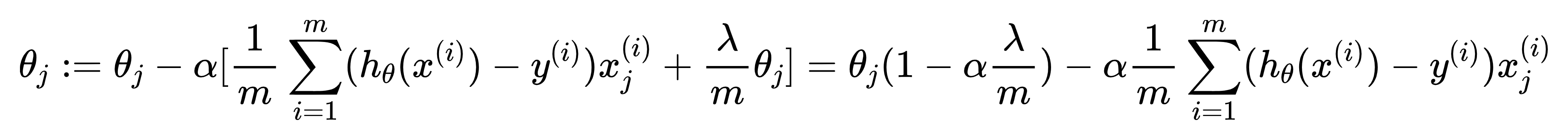
(j=1,2,…n)
}
5.正则化线性回归的正规方程算法
正规方程忘了的可以去看看正则化之前的正规方程
正则化的正规方程算法求代价函数时:
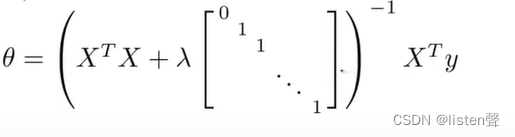
不可逆问题:

只要 λ \lambda λ>0, X T X + λ [ 0 1 1 . . . 1 ] X^TX+\lambda\begin{bmatrix} 0 & & &&&\\ &1 & \\ & &1 \\ & & &... \\ & &&&1 \\ \end{bmatrix} XTX+λ 011...1 就一定可逆。
其中矩阵是n+1维的
6.正则化逻辑回归的梯度下降算法
之前的梯度下降算法更新规则:
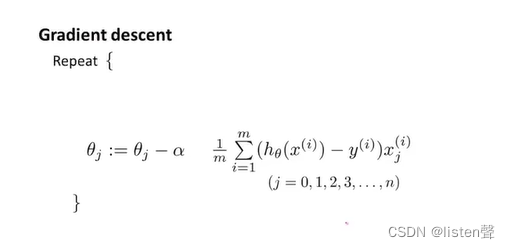
正则化之后:
同样要先把
θ
0
\theta_0
θ0拿出来单独更新
Repeat{
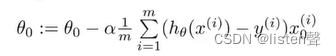

(j=1,2,…n)
}
虽然看上去和线性回归一样,但是两种算法的假设函数 h θ ( x ( i ) ) h_\theta(x^{(i)}) hθ(x(i))的定义是不同的。
7.正则化逻辑回归的更高级算法

自己定义一个costFunction,以参数向量
θ
\theta
θ作为输入,
θ
\theta
θ下标从0开始。
有时间有精力的小伙伴可以去看看。















 807
807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









