






小米-暑期实习-面经(非本人)
1.JVM的架构,具体阐述一下各个部分的功能?
可分为:
JVM类加载器,
JVM运行时数据区(内存结构),
执行引擎
其中:
JVM类加载器,的作用是将class文件加载到虚拟机内存中去
JVM内存结构:
分为:
方法区:是线程共享的,存放类的信息,常量,静态变量以及JIT编译后的代码
java栈:为java方法服务,是线程私有的,在执行时为每个方法创建一个栈帧,用于存放局部变量表,操作数栈,动态链接和方法出口等信息,可以理解为方法的数据结构
本地方法栈:同java栈类似,为native方法服务
堆区:对象的实例和数组
程序技术器:通过改变计数值选取下一条需要执行的字节码指令
2.Zset的底层如何实现

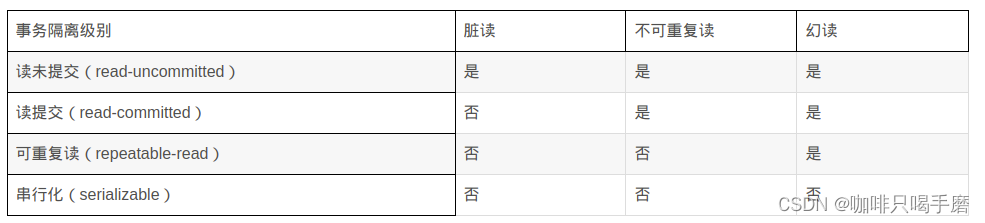
3.Mysql隔离机制有哪些?怎么实现的?可串行化是怎么避免的三个事务问题?
4.Spring源码看过吗?Spring的三级缓存知道吗?
Spring三级缓存就是用来存放不同类型的Bean
第一级缓存:存放完全初始化好的Bean,可以直接使用
第二级缓存:存放原始的Bean对象,还没有进行赋值或者没有被依赖注入
第三级缓存:存放Bean工厂对象,用来生成原始的Bean对象放入二级缓存
5.抛开Spring,讲讲反射和动态代理?那三种代理模式怎么实现的?
反射机制:
java语言在运行时拥有的一项自观的能力,
可以在运行时:
判断任意一个对象所属类,所具有的成员变量和方法
构造任意一个类的对象
调用任意一个对象的方法
动态代理:
在运行时,创建目标对象的代理对象,并对目标对象中的方法进行功能性增强的一种技术,AOP就是基于这种思想
三种代理模式:
1、基于接口,和继承实现(静态代理),
2、基于接口的jdk动态代理(通过反射实现)
3、不基于接口的cglib代理
6.讲讲线程池?为什么用线程池?
线程池,对线程资源的一种池化技术
java提供threadPoolExecutor来创建线程池对象
有7个参数:
核心线程数
最大线程数
非核心线程空闲时间
、、、时间单位
任务队列
线程工厂
拒绝策略
为什么用线程池:
1、降低资源消耗
2、提高响应速度,无需创建直接执行
3、提高线程的可管理性
7.集合里面的arraylist和linkedlist的区别是什么?有何优缺点
arraylist是基于动态数组实现的数据结构,linkedlist是基于链表的数据结构
对于随机访问get和set,arraylist效率优于linkedlist
对于增删操作,linkedlist比较优势
8.介绍一下计网里面的tcp和udp协议
TCP:
有连接
可靠
面向字节流
UDP:
不可靠,无连接的传输层协议
面向数据报
9.介绍一下http和https的区别?为什么https安全?
http:
超文本传输协议
计算机与计算机之间进行网络传输和文件传输的一种协议
https:
超文本传输安全协议
在http基础上,新增传输加密,身份验证
区别:
1、http采用明文传输,安全性较低,而https使用ssl加密传输,安全性高
2、http和https采用不同的链接方式,使用端口也有所区别,http采用80端口,https采用443端口
3、理论上http响应速度更快,只需进行三次握手就可进行数据传输,而https除三次握手外,还要进行SSL握手,才能进行数据传输
为什么https安全:
SSL:一种安全传输协议,
HTTP直接和TCP通信。当使用SSL时,则演变成先和SSL通信,再由SSL和TCP通信了。简言之,所谓HTTPS,其实就是身披SSL协议这层外壳的HTTP
TLS/SSL 的功能实现主要依赖于三类基本算法:散列函数 、对称加密和非对称加密,其利用非对称加密实现身份认证和密钥协商,对称加密算法采用协商的密钥对数据加密,基于散列函数验证信息的完整性
10.Mysql有很大的数据量怎么办?怎么分表分库?
垂直拆分与水平拆分
如何分库分表看这篇很清晰
方案:
hash取模
range范围方案
11.Redis的基本数据类型?Redis的持久化呢?有何优缺点?
基本数据类型:
字符串(k-v)
字典(hset ):类似于java map (数组加链表)
列表(数据结构是链表)
集合(set):存储非重复元素
有序集合(zset):排序属性 score(分值),每个存储元素有两个值组成,一个是元素值,一个是排序值。有序集合的元素值也是不能重复,但分值可以重复
Redis的持久化:
RDB:
在指定的时间间隔内,将内存中的数据集快照写入磁盘。
Redis会单独创建(fork)一个子进程进行持久化,会将数据写入到一个临时文件中,待持久化过程结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的。
优点:
适合大规模的数据恢复
对数据的完整性要求不高
缺点:
1、需要一定的时间间隔进行操作,如果redis意外宕机,这个最后一次的修改数据就没有了
2、fork进程时,会占用一定的内存空间
AOF:
以日志的形式来记录每一个写操作,将redis执行过的所有指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之redis重启的话就是根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
优点:
1、每一次修改都同步,文件的完整性更好
缺点:
1、相对于数据文件来说,aof远远大于rdb,修复的速度也比rdb慢!
2、aof运行效率也要比rdb慢,所以我们redis默认的配置就是redis持久化!
12.B+树了解吗?底层呢?为什么这么用?
B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,只有叶子节点存储data,叶子节点包含了这棵树的所有键值,叶子节点不存储指针。后来,在B+树上增加了顺序访问指针,也就是每个叶子节点增加一个指向相邻叶子节点的指针,这样一棵树成了数据库系统实现索引的首选数据结构。那为什么是B+树而不是B树呢,因为它内节点不存储data,这样一个节点就可以存储更多的key。
MySQL 默认的存储引擎 InnoDB 采用的是 B+ 作为索引的数据结构,原因有:
1、B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比存储即存索引又存记录的 B 树,B+树的非叶子节点可以存放更多的索引,因此 B+ 树可以比 B 树更「矮胖」,查询底层节点的磁盘 I/O次数会更少。
2、B+ 树有大量的冗余节点(所有非叶子节点都是冗余索引),这些冗余索引让 B+ 树在插入、删除的效率都更高,比如删除根节点的时候,不会像 B 树那样会发生复杂的树的变化;
算法
折叠链表
思路
1、从中间先分割链表
2、翻转第二链表
3、合并两个链表

















 1692
1692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









