






安装程序
Tesseract有如下安装网址
https://tesseract-ocr.github.io/tessdoc/Installation.html
进入download网站
Downloads | tessdoc (tesseract-ocr.github.io)
对于windows操作系统,登录进入如下网站下载
https://digi.bib.uni-mannheim.de/tesseract/
然后将下载后的软件安装到电脑。选择需要的语言的组件(components)。比如,此处选择了汉
语的简体和繁体,以及其它学习的语言。
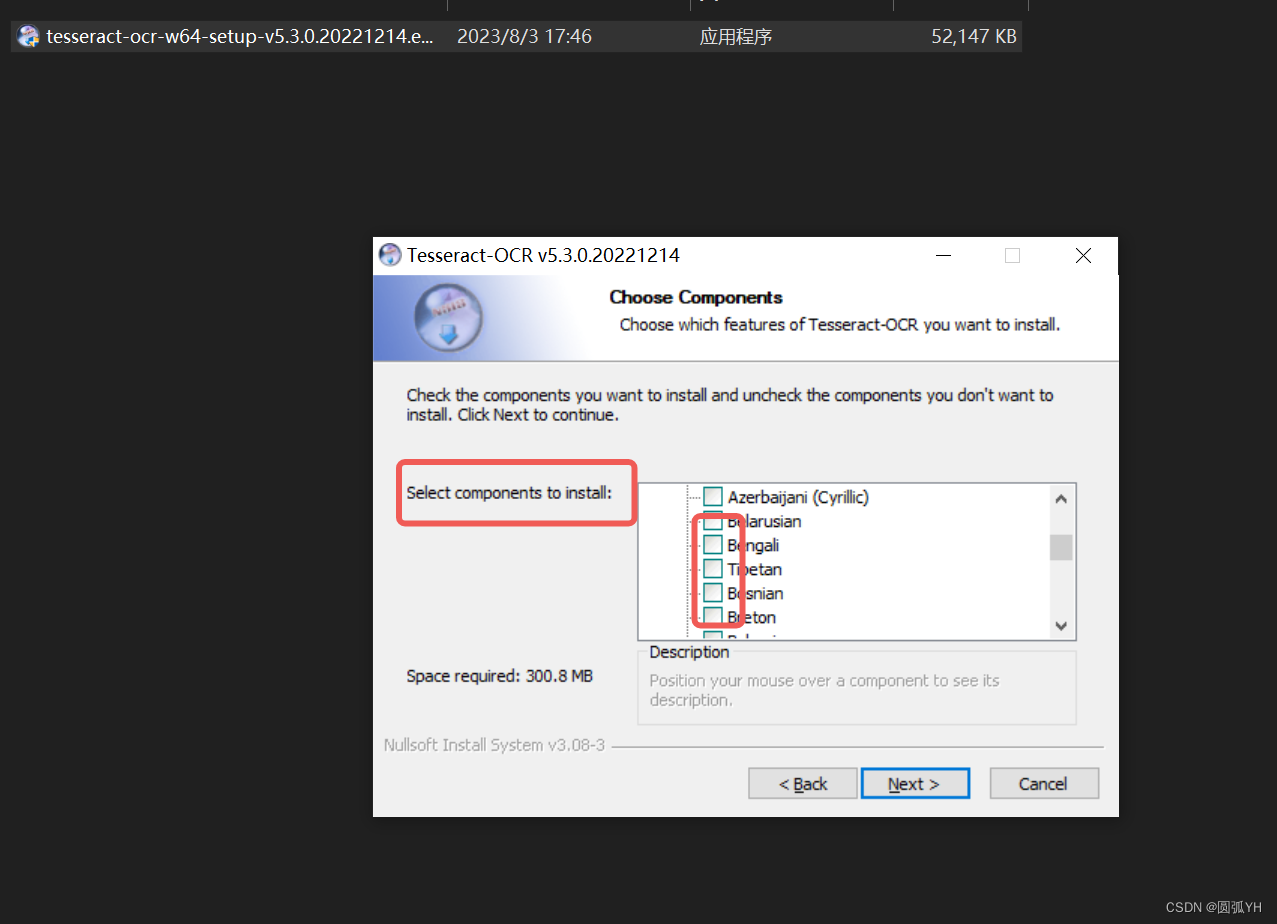
最后显示安装成功。
在电脑环境变量中安装Tesseract,
这个时候,就会在电脑
解决问题 将png图片数据转化为xlsx文件数据
当我们在pyhton中使用 pytesseract库的时候, pip install pytesseract安装完。
但是,它并不能识别出图片内容,并且会抛出异常: pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it’s not in your PATH. See README file for more information.
这是因为缺少了一个重要的程序:tesseract。
为了解决这个问题,安装了tesseract程序并配置环境变量。
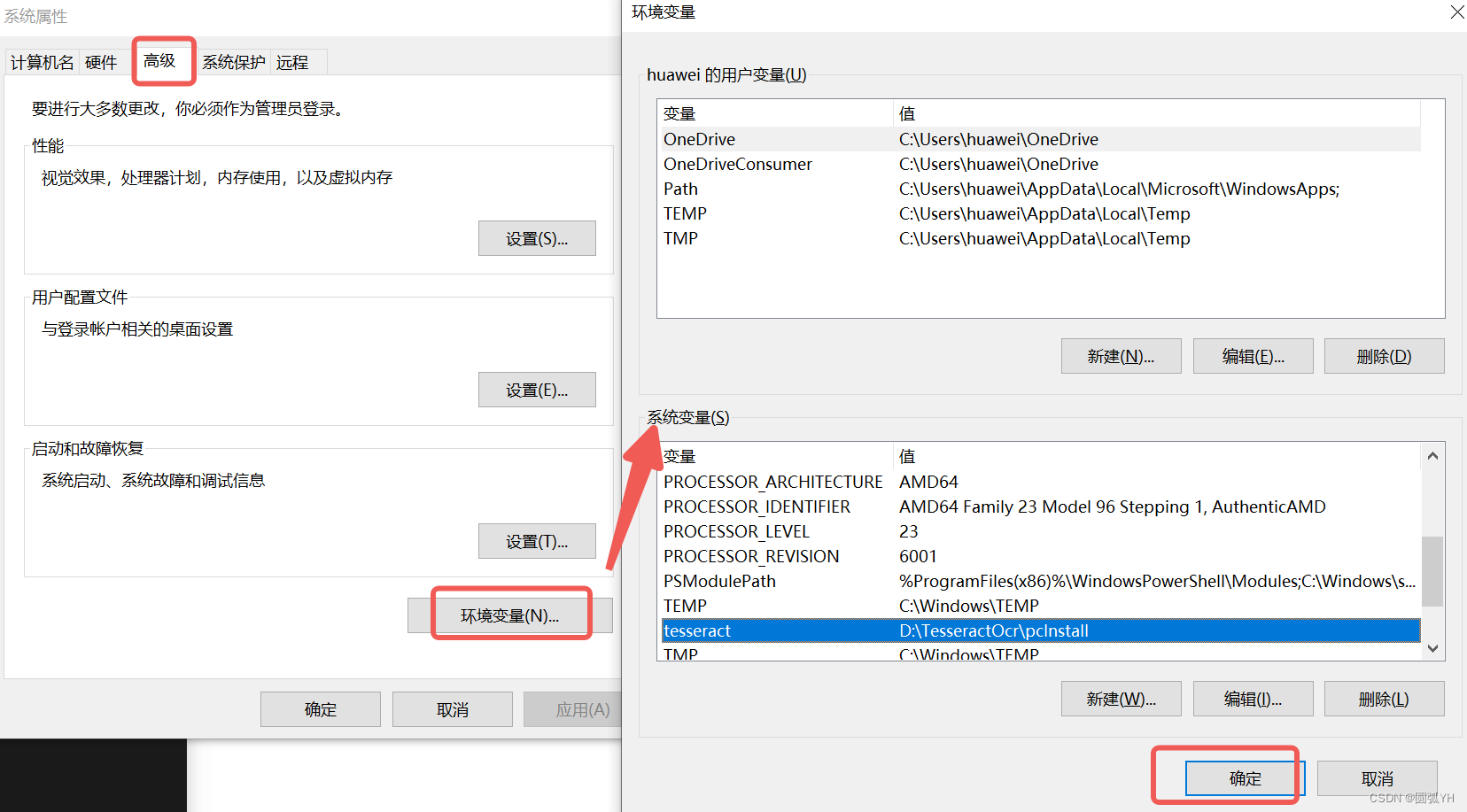
安装并配置完毕后,电脑程序上会出现 Console平台,这个和CMD类似。在Console平台上也可以运用python程序。
![]()
下面是一段由"BingChat Gptplus"( https://gptplus.io/cn )生成的一段代码。
"""
这段代码由chatGPT生成。PNG图片是一个表格的截图,现在将表格截图重新生成xlsx文件,以便利用其数据。
"""
import pandas as pd
import cv2
import pytesseract
# 读取PNG图片
image = cv2.imread('table.png')
# 使用Tesseract OCR库识别图片中的文字
text = pytesseract.image_to_string(image, lang='chi_sim')
# 将识别的文字转换为DataFrame
rows = text.split('\n')
data = []
for row in rows:
if row.strip() == '':
continue
data.append(row.split('\t'))
df = pd.DataFrame(data)
# 将DataFrame保存为Excel
df.to_excel('table.xlsx', index=False)
因为选择将这段代码放在E盘,所以打开Console后,进入E盘,并执行test.py程序。
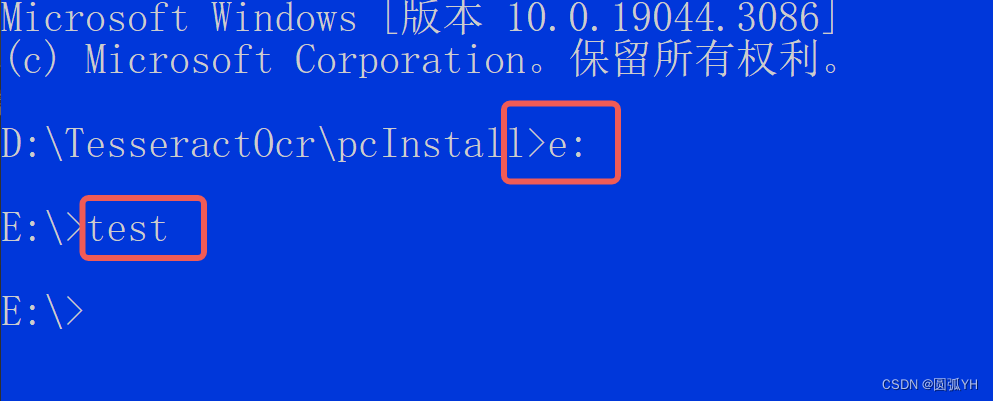
于是运行程序。成功地将png图片数据转化为xlsx文件数据。















 3481
3481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









