







文章目录
👉👉👉本系列是考研系列👈👈👈
内容为:
1、考研题考研408中的算法和数据结构考点讲解;
2、从2011年开始考研408历年笔试题中数据结构部分的真题。
3、上机题;
笔试跟上机可以分开来准备,因为这两个内容相关度不大。区别就在于上机可以用库函数,笔试则不行,然而复试一般都是机试。
408考试分数分布:
数据结构(45分)
计算机组成(45分)
操作系统(35分)
计算机网络(25分)
一、时间复杂度
统计计算量和n的关系,只考虑次数不考虑常数。 2 n 2 = n 2 2n^2 = n ^ 2 2n2=n2
只考虑次数,不考虑常数。常见复杂度有: O ( 1 ) 、 O ( n ) 、 O ( s q r t ( n ) ) 、 O ( n k ) 、 O ( l o g n ) 、 O ( n l o g n ) O(1)、O(n)、O(sqrt(n))、O(n^k)、O(logn)、O(nlogn) O(1)、O(n)、O(sqrt(n))、O(nk)、O(logn)、O(nlogn)
二、矩阵展开
给我们一个矩阵,告诉我们他的展开方式,展开之后某个元素在展开后的下标是多少。(按行展开和按列展开)展开到C里下表是从0开始。
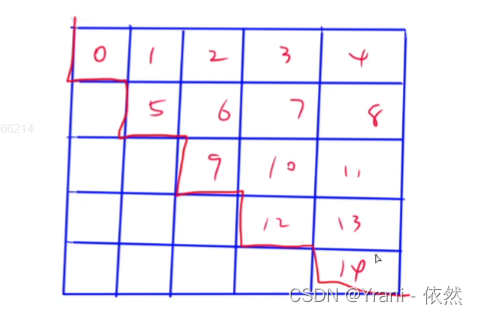
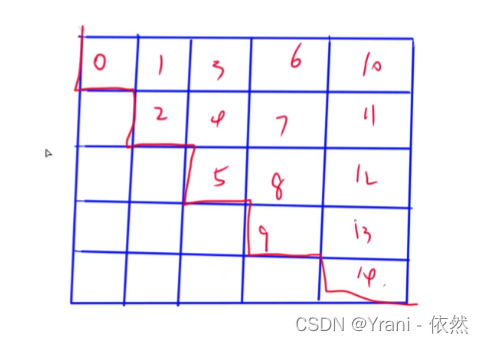

B
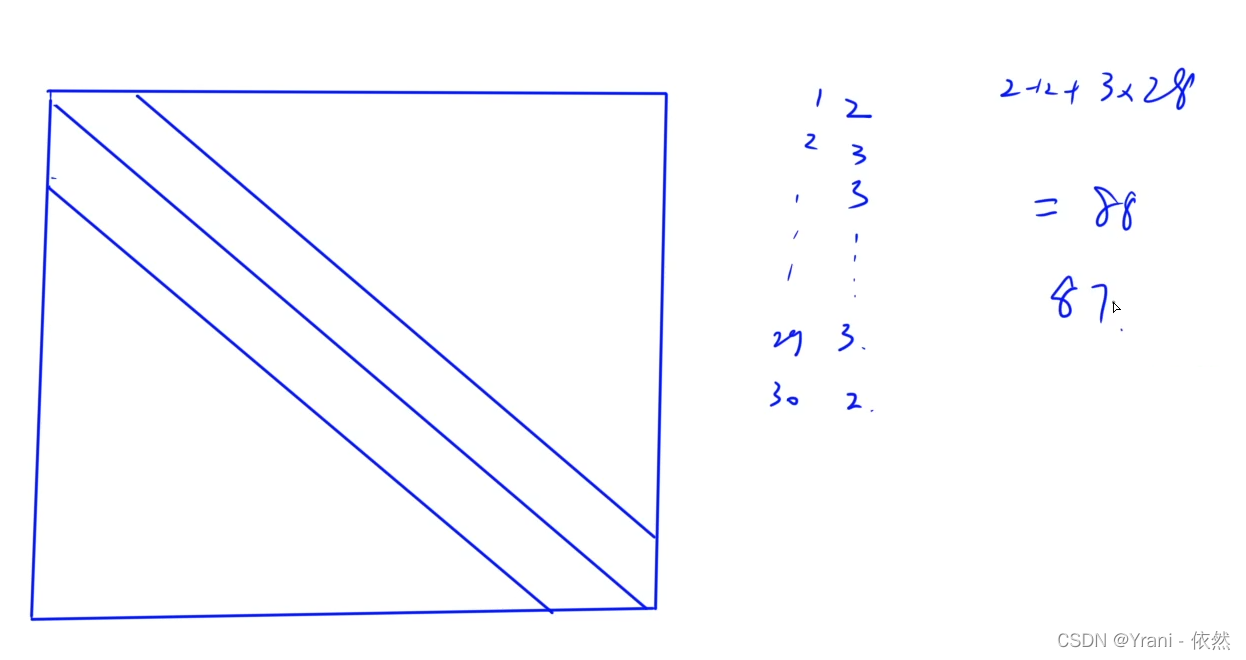
三对角矩阵如上。

A
c语言的1维数组意思就是告诉我们下标是从0开始的。
12 + 11 + 10 + 9 + 8 + 1 = 51 - 1 = 50

C
矩阵的按行展开、按列展开,展开后下标从0开始。
考题:2016-4、2018-3、2020-1
三、排序
不需要知道原理 只需要知道库函数,会自定义比较规则,执行多关联排序,如何得到一个稳定排序,以及时间复杂度即可。仅用于上机。上机不会用到原理,而笔试就跟背八股文一样,纸上谈兵,不让用库函数。需要知道原理才可以,分开复习即可。
稳定排序:相同元素相对位置不发生变化。
快排不稳定排序
堆排不稳定排序
归并是稳定排序
sort是不稳定的排序方式
如果想达到稳定排序 可以用多关联字排序 下标当作一维关键字,值相同的时候比较下标,这样就可以将sort变成稳定排序了。
stable-sort c++内部实现的稳定排序,原理好像是归并排序。
stable_sort
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1010;
int n, m; //n为人数 m是排序的类型 0表示从高到低,1表示从低到高。
struct Person
{
string name;
int score;
bool operator< (const Person &t) const //重载小于号 从低到高排
{
return score < t.score;
}
bool operator> (const Person &t) const //重载大于号 从高到底
{
return score > t.score;
}
}q[N];
int main()
{
cin >> n >> m;
for (int i = 0; i < n; i ++ ) cin >> q[i].name >> q[i].score;
if (!m) //如果m是0 取非就是1
{
stable_sort(q, q + n, greater<Person>()); // 逆序来排 从大到小
}
else
{
stable_sort(q, q + n); // 从小到大 默认传参less<Person>
}
for (int i = 0; i < n; i ++ )
cout << q[i].name << ' ' << q[i].score << endl;
return 0;
}
sort
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1010;
int n, m; //n为人数 m是排序的类型 0表示从高到低,1表示从低到高。
struct Person
{
string name;
int score;
int id; //存储编号
//operator 运算符重载 可以重载< > () ==等等 一般都是重载< > 一般只有在定义结构体的比较方式的时候
//需要用到运算符重载。
bool operator< (const Person &t) const //重载小于号 从低到高排
{
if (score != t.score) return score < t.score;
return id < t.id; //如果相等根据编号小的在前 就是不改变相对的位置
}
bool operator> (const Person &t) const //重载大于号 从高到底
{
if (score != t.score) return score > t.score;
return id < t.id; //如果相等根据编号小的在前 就是不改变相对的位置
}
}q[N];
int main()
{
cin >> n >> m;
for (int i = 0; i < n; i ++ )
{
cin >> q[i].name >> q[i].score;
q[i].id = i;
}
if (!m) //如果m是0 取非就是1
{
sort(q, q + n, greater<Person>()); // 逆序来排 从大到小
}
else
{
sort(q, q + n); // 从小到大 默认传参less<Person>
}
for (int i = 0; i < n; i ++ )
cout << q[i].name << ' ' << q[i].score << endl;
return 0;
}
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 110;
int n;
struct Person
{
int id;
int score;
//双关键字排序 比较的时候有两个关键字参与排序
bool operator< (const Person &t) const //重载<号 因为题目要求是从小到大排序
{
//加&的目的是少复制
//第一个const是说t在后面是不会改变的
//第二个const是说在函数里面是不会改变person中的其他变量的
//返回值是a 是否小于 b
if (score != t.score) return score < t.score; //关键字1是成绩
return id < t.id; //关键字2是学号 第一个id是自己的id 第二个是t的id
//可以理解为我是不是一定要排到t的前面,如果是返回true否则返回false
//举例子 比如说 现在有两个person类型的变量a 和 b 此时调用一下a < b那么a < b用的是哪个对象里的
//重载运算符呢?用的是a里的重载运算符,当调用a < b的时候,相当于可以看成是a. < (b) <可以看成a这个
//对象的函数 a.调用这个函数,函数的参数是b带入就ok了
// a < b如果a应该排到b的前面则返回true,如果a不一定要排到b的前面那么返回false
}
}q[N];
int main()
{
cin >> n;
for (int i = 0; i < n; i ++ ) cin >> q[i].id >> q[i].score;
sort(q, q + n);
for (int i = 0; i < n; i ++ ) cout << q[i].id << ' ' << q[i].score << endl;
return 0;
}
笔试就如同文科,比如散列表,要想提高散列表的执行效率的话,尽量避免发生冲突。是错误的
应该是尽量减少发生冲突,因为不可能避免。
四、进位制
其他进制转10进制。一般思路:
(123)4 = (27)10
秦九韶算法


10进制转其他进制。一般思路:

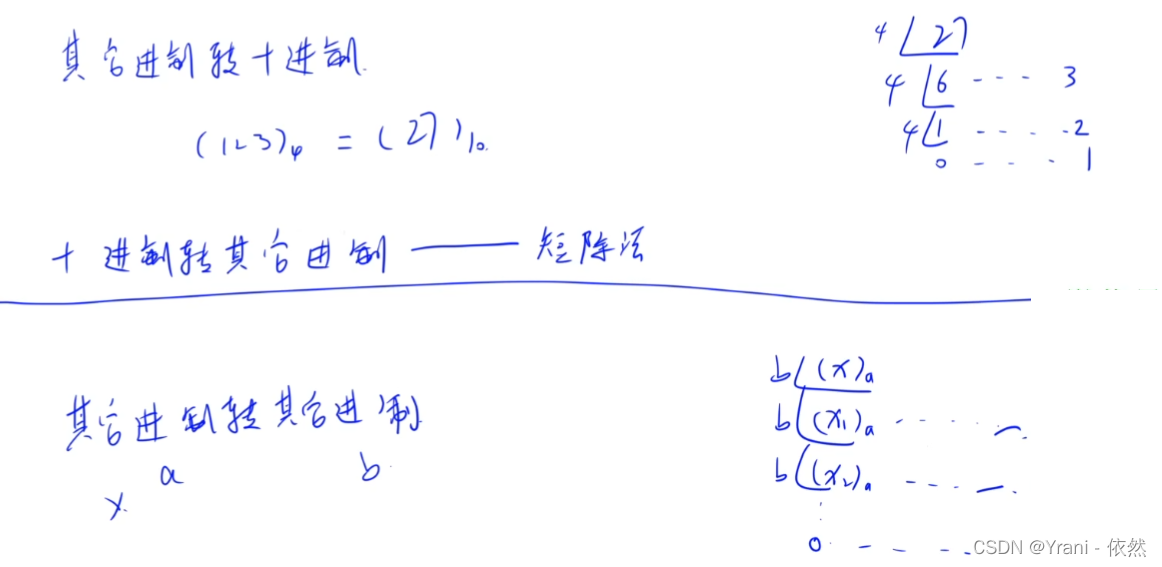
为什么要倒着存储?
倒着存的原因是:除了除法之外,加减乘都是需要倒着存的,比如891 + 917 加完之后可能会多了一位,如果正着存的话,在数组前面多一位,相当于你在数组0的位置上多了一位,那么数组0后面的所有元素都需要往后面移动一位才可以,会有大量元素的移动会很麻烦。如果倒着存就相当于在数组的最后面加油一个数字,那么很容易加。
高精度:用一个数组:把这个数的每一位存下来,表示一个数字不是用int或者longlong了。第一位是个位第二位是十位以此类推。>
练习语法题
#include <iostream>
#include <algorithm>
#include <cstring>
#include <vector>
using namespace std;
vector<int> div(vector<int> A, int b)
{
vector<int> C;
for (int i = A.size() - 1, r = 0; i >= 0; i -- )
{
r = r * 10 + A[i]; //余数 * 10 加上当前这一位
C.push_back(r / b); //商
r %= b; //余数
}
reverse(C.begin(), C.end()); // C先插入的是高位所以要reverse一遍
while (C.size() && C.back() == 0) //删除前导0 当C >= 0时候
{
C.pop_back();
}
return C;
}
int main()
{
// A.size() // A不是0
// C先插入的是高位
string s;
while (cin >> s)
{
vector<int> A;
for (int i = 0; i < s.size(); i ++ )
{
A.push_back(s[s.size() - i - 1] - '0');
}
string res;
if (s == "0") res = "0";
else
{
while(A.size())
{
res += to_string(A[0] % 2);
A = div(A, 2);
}
}
//输出 所有余数要倒着来输出 从下往上才是我们要的结果 但是我们存的时候是从上往下存的
reverse(res.begin(), res.end());
cout << res << endl;
}
return 0;
}
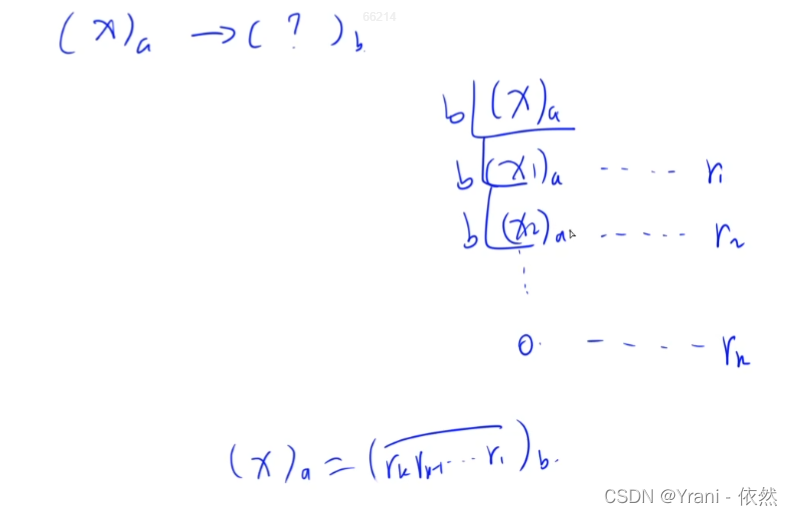
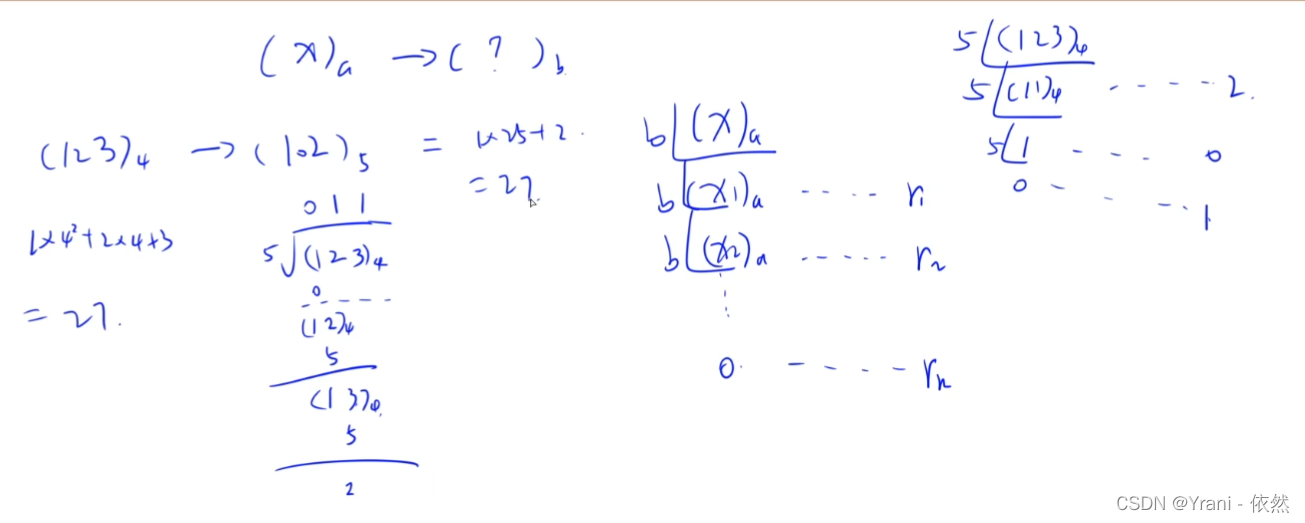
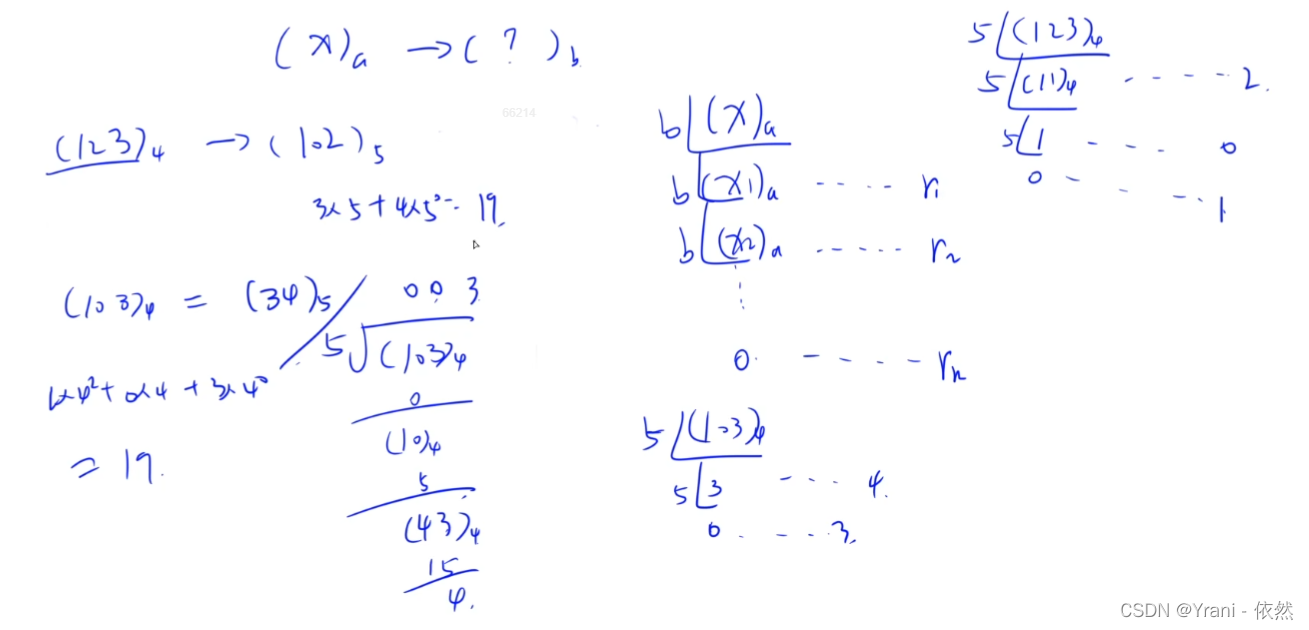
如果是4进制转成10进制 如果4进制有100位那么 需要将这100位都转成10进制,在将这100位10进制转成其他进制,由此可见复杂度是非常高的。而4进制直接转成5进制则只需要转换部分位,10进制作为踏板,中间某一步是需要转换成10进制的。
用到10进制的就是前面的余数跟当前这一位上的数结合起来只有这一步用到了10进制,如果4 * 4 + 3 = 19 来除以5 这样做的好处是只需要做高精度除法即可。时间复杂度O(n^2)
如果说每次都需要除以2那么需要log2^n次才可以除完,而n位与k的关系是
log10^n,也就说位数也是logn级别的,除的次数也是logn级别的,位数和除的次数的同一级别,如果有k位,算除法的时候,每做一次除法,是O(k)级别的,所以整个算法复杂度是 O ( k 2 ) O (k^2) O(k2)
#include <iostream>
#include <algorithm>
#include <cstring>
#include <vector>
using namespace std;
int main()
{
int a, b;
string s;
cin >> a >> b >> s;
vector<int> A; //A来存高精度的数
for (int i = 0; i < s.size(); i ++ )
{
char c = s[s.size() - 1 - i];
if (c >= 'A') // 表示从11开始的数字
{
A.push_back(c - 'A' + 10);
}
else
{
A.push_back(c - '0');
}
}
string res;
if (s == "0") res = "0";
else
{
while (A.size()) // 当A不是0的时候
{
int r = 0;
for (int i = A.size() - 1; i >= 0; i -- )
{
A[i] += r * a;
r = A[i] % b;
A[i] /= b;
}
while (A.size() && A.back() == 0) A.pop_back();
if (r < 10) res += to_string(r);
else
{
res += r - 10 + 'a';
}
}
reverse(res.begin(), res.end());
}
cout << res << endl;
return 0;
}

五、笔试题
5.1 2011-1

答案:A
5.2 2012-1

答案:B
5.3 2013-1


答案:D
5.4 2014-1

答案:C
5.5 2017-1

答案:B

5.6 2019-1

答案:B
5.7 2016-4

答案:A
5.8 2018-3

答案:A
5.9 2020-1

答案:A

六、上机题
| 类型 | 题目 |
|---|---|
| 排序 | AcWing 3375. 成绩排序 |
| AcWing 3376. 成绩排序2 | |
| 进位制 | AcWing 3373. 进制转换 |
| AcWing 3374. 进制转换2 |
七、由数据范围反推算法复杂度以及算法内容
由于C++ 1s大概算
1
0
7
10^7
107 ~
1
0
8
10^8
108 都可以出解 1千万次到1亿次即可。
一般ACM或者笔试题的时间限制是1秒或2秒。
在这种情况下,C++代码中的操作次数控制在
1
0
7
∼
1
0
8
10^7∼10^8
107∼108为最佳。
下面给出在不同数据范围下,代码的时间复杂度和算法该如何选择:
-
n ≤ 30 n≤30 n≤30, 指数级别, dfs+剪枝,状态压缩dp
-
n ≤ 100 = > O ( n 3 ) n≤100 => O(n3) n≤100=>O(n3),floyd,dp,高斯消元
-
n ≤ 1000 = > O ( n 2 ) n≤1000 =>O(n2) n≤1000=>O(n2), O ( n 2 l o g n ) O(n2logn) O(n2logn),dp,二分,朴素版Dijkstra、朴素版Prim、Bellman-Ford
-
n ≤ 10000 = > O ( n ∗ n √ ) n≤10000 => O(n∗n√) n≤10000=>O(n∗n√),块状链表、分块、莫队
-
n ≤ 100000 = > O ( n l o g n ) = > n≤100000 => O(nlogn) => n≤100000=>O(nlogn)=>各种sort,线段树、树状数组、set/map、heap、拓扑排序、dijkstra+heap、prim+heap、spfa、求凸包、求半平面交、二分、CDQ分治、整体二分
-
n ≤ 1000000 = > O ( n ) n≤1000000 => O(n) n≤1000000=>O(n), 以及常数较小的 O(nlogn)O(nlogn) 算法 => 单调队列、 hash、双指针扫描、并查集,kmp、AC自动机,常数比较小的 O(nlogn)O(nlogn) 的做法:sort、树状数组、heap、dijkstra、spfa
-
n ≤ 10000000 = > O ( n ) n≤10000000 => O(n) n≤10000000=>O(n),双指针扫描、kmp、AC自动机、线性筛素数
-
n ≤ 109 = > O ( n √ ) n≤109 => O(n√) n≤109=>O(n√),判断质数
-
n ≤ 1 0 18 n≤10^{18} n≤1018 = > O ( l o g n ) =>O(logn) =>O(logn),最大公约数,快速幂
-
n ≤ 1 0 1000 = > O ( ( l o g n ) 2 ) n≤10^{1000}=> O((logn)2) n≤101000=>O((logn)2),高精度加减乘除
-
n ≤ 1 0 100000 n≤10^{100000} n≤10100000=> O ( l o g k × l o g l o g k ) O(logk×loglogk) O(logk×loglogk),k表示位数 O ( l o g k × l o g l o g k ) O(logk×loglogk) O(logk×loglogk),k表示位数,高精度加减、FFT/NTT
1、看循环
2、递归,主定理















 2633
2633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









