







 C++排序算法整理~
C++排序算法整理~
排序算法
-
- `桶排序`
- 冒泡排序
- `快速排序`
- `归并排序`
-
- 1. 算法步骤
- 2. 动图演示
- 3. 代码 (二叉树的后序遍历)
- [剑指 Offer II 077. 链表排序](https://leetcode-cn.com/problems/7WHec2/)
- [剑指 Offer II 078. 合并排序链表](https://leetcode-cn.com/problems/vvXgSW/)
- [剑指 Offer 51. 数组中的逆序对](https://leetcode.cn/problems/shu-zu-zhong-de-ni-xu-dui-lcof/)
- [327. 区间和的个数](https://leetcode.cn/problems/count-of-range-sum/)
- `堆排序`
- 选择排序
- 插入排序
- 计数排序
- STL里sort算法用的是什么排序算法?
- 稳定排序和不稳定排序
| 排序方法 | 平均时间 | 最好时间 | 最坏时间 |
|---|---|---|---|
| 桶排序(不稳定) | O(n) | O(n) | O(n) |
| 基数排序(稳定) | O(n) | O(n) | O(n) |
| 归并排序(稳定) | O(nlogn) |
O(nlogn) |
O(nlogn) |
| 快速排序(不稳定) | O(nlogn) |
O(nlogn) |
O(n^2^) |
| 堆排序(不稳定) | O(nlogn) | O(nlogn) | O(nlogn) |
| 希尔排序(不稳定) | O(n1.25) | ||
| 冒泡排序(稳定) | O(n2) | O(n) | O(n2) |
| 选择排序(不稳定) | O(n2) | O(n2) | O(n2) |
| 直接插入排序(稳定) | O(n2) | O(n) | O(n2) |
桶排序
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。为了使桶排序更加高效,我们需要做到这两点:
- 在额外空间充足的情况下,尽量增大桶的数量
- 使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中
同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。
1. 什么时候最快
当输入的数据可以均匀的分配到每一个桶中。
2. 什么时候最慢
当输入的数据被分配到了同一个桶中。
3. 示意图
元素分布在桶中:
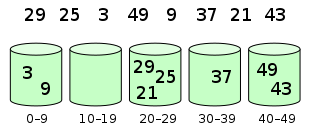
然后,元素在每个桶中排序:

代码:
#include <iostream>
#include <iterator>
#include <vector>
using namespace std;
const int BUCKET_NUM = 10;
struct ListNode {
explicit ListNode(int i = 0) : mData(i), mNext(NULL) {}
ListNode *mNext;
int mData;
};
//有序链表插入val
ListNode *insert(ListNode *head, int val) {
ListNode dummyNode;
ListNode *newNode = new ListNode(val);
ListNode *pre, *curr;
dummyNode.mNext = head;
pre = &dummyNode;
curr = head;
while (NULL != curr && curr->mData <= val) {
pre = curr;
curr = curr->mNext;
} // 找到第一个大于val的node curr
newNode->mNext = curr; //插入val
pre->mNext = newNode; //拼接
return dummyNode.mNext;
}
//合并两个有序链表
ListNode *Merge(ListNode *head1, ListNode *head2) {
ListNode dummyNode;
ListNode *dummy = &dummyNode;
while (NULL != head1 && NULL != head2) {
if (head1->mData <= head2->mData) {
dummy->mNext = head1;
head1 = head1->mNext;
}
else {
dummy->mNext = head2;
head2 = head2->mNext;
}
dummy = dummy->mNext;
}
if (NULL != head1)
dummy->mNext = head1;
if (NULL != head2)
dummy->mNext = head2;
return dummyNode.mNext;
}
void BucketSort(int n, int arr[]) {
vector<ListNode *> buckets(BUCKET_NUM, (ListNode *)(0));
for (int i = 0; i < n; ++i) {
int index = arr[i] / BUCKET_NUM;
ListNode *head = buckets.at(index);
buckets.at(index) = insert(head, arr[i]);
}
ListNode *head = buckets.at(0);
for (int i = 1; i < BUCKET_NUM; ++i) {
head = Merge(head, buckets.at(i));
}
for (int i = 0; i < n; ++i) {
arr[i] = head->mData;
head = head->mNext;
}
}
//桶排序
void bucketsort(int* A, int n) {
vector<vector<int>> bucket(10); //分配10个桶(0~9、10~19...)
for (int i = 0; i < 10; i++) { //每个桶初始化
vector<int> x = { 0 };
bucket.push_back(x);
}
//把待排序列放入桶中
for (int i = 0; i < n; i++) {
bucket[A[i] / 10].push_back(A[i]); //10 桶大小
}
//把每个桶内的数据填充回到原序列中
int k = 0;
for (int i = 0; i < 10; i++) {
sort(bucket[i].begin(), bucket[i].end()); //桶内排序
for (vector<int>::iterator it = bucket[i].begin(); it != bucket[i].end(); it++)
A[k++] = *it;
}
}
冒泡排序
冒泡排序(Bubble Sort)也是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端。
作为最简单的排序算法之一,冒泡排序给我的感觉就像 Abandon 在单词书里出现的感觉一样,每次都在第一页第一位,所以最熟悉。冒泡排序还有一种优化算法,就是立一个 flag,当在一趟序列遍历中元素没有发生交换,则证明该序列已经有序。但这种改进对于提升性能来
说并没有什么太大作用。
1. 算法步骤
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
2. 动图演示
每次遍历都会把极大值固定在最右侧,所以不需要完整的两个for
3. 什么时候最快
当输入的数据已经是正序时(都已经是正序了,我还要你冒泡排序有何用啊)。
4. 什么时候最慢
当输入的数据是反序时(写一个 for 循环反序输出数据不就行了,干嘛要用你冒泡排序呢,我是闲的吗)。
5. 代码
#include <iostream>
using namespace std;
template<typename T> //整数或浮点数皆可使用,若要使用类(class)或结构体(struct)时必须重载大于(>)运算符
void bubble_sort(T arr[], int len) {
int i, j;
for (i = 0; i < len - 1; i++)
for (j = 0; j < len - 1 - i; j++)
if (arr[j] > arr[j + 1])
swap(arr[j], arr[j + 1]);
}
int main() {
int arr[] = { 61, 17, 29, 22, 34, 60, 72, 21, 50, 1, 62 };
int len = (int) sizeof(arr) / sizeof(*arr);
bubble_sort(arr, len);
for (int i = 0; i < len; i++)
cout << arr[i] << ' ';
cout << endl;
float arrf[] = { 17.5, 19.1, 0.6, 1.9, 10.5, 12.4, 3.8, 19.7, 1.5, 25.4, 28.6, 4.4, 23.8, 5.4 };
len = (float) sizeof(arrf) / sizeof(*arrf);
bubble_sort(arrf, len);
for (int i = 0; i < len; i++)
cout << arrf[i] << ' '<<endl;
return 0;
}
可视化
void bubbleSort(vector<int> &nums) {
int n = nums.size();
bool swapped;
do {
swapped = 0;
for (int i = 0; i < n - 1; i++) {
if (nums[i] > nums[i + 1]) {
swap(nums[i], nums[i + 1]);
swapped = 1;
}
}
} while (swapped);
}
快速排序
1. 算法步骤
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
2. 动图演示
3. 代码 (二叉树的前序遍历)
//分割函数
int paritition(vector<int>& A, int low, int high){
int pivotValue = A[low];
while(low<high){
while(low<high && A[high] >= pivotValue)
--high; //从右向左查找到第一个小于pivot的坐标
A[low] = A[high];
while(low<high && A[low] <= pivotValue)
++low; //从左向右查找到第一个大于pivot的坐标
A[high] = A[low];
}
A[low] = pivotValue; //拿走的值返还 放到排序的位置
return low; //返回的是一个位置
}
// 洗牌算法,将输入的数组随机打乱 避免极端情况
void shuffle(vector<int>& nums){
srand(time(0)); //随机数种子是必须有的? 因为一次shuffle函数调用 多次rand
for(int i = 0; i<nums.size(); i++){
int r = i + rand()%(nums.size() - i)
swap(nums[i], nums[r]);
}
}
//快排母函数
void quickSort(vector<int>& A, int low, int high){
if(low<high){
int pivotIndex = paritition(A, low, high);
quickSort(A, low, pivotIndex-1);
quickSort(A, pivotIndex+1, high);
}
}
从大到小排序修改
//分割函数
int Paritition(vector<int>& A, int low, int high){
int pivot = A[low];
while(low<high){
while(low<high && A[high] <= pivot) //<=
--high;
A[low] = A[high];
while(low<high && A[low] >= pivot) //>=
++low;
A[high] = A[low];
}
A[low] = pivot; //拿走的值返还 放到排序的位置
return low; //返回的是一个位置
}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 431
431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











