






 本文介绍了自动编码器在时间序列异常检测中的应用,通过学习正常模式来识别数据中的异常。方法包括构建和训练LSTM自动编码器,以及通过比较原始数据与重建数据的差异来发现异常。这种技术在金融、医疗和工业等领域具有广泛潜力。
本文介绍了自动编码器在时间序列异常检测中的应用,通过学习正常模式来识别数据中的异常。方法包括构建和训练LSTM自动编码器,以及通过比较原始数据与重建数据的差异来发现异常。这种技术在金融、医疗和工业等领域具有广泛潜力。
导 读
当我们分析大型数据集并想要解码数据集中的任何异常值时,自动编码器非常有帮助。
有需要的朋友关注公众号【小Z的科研日常】,获取更多内容。
01、介绍
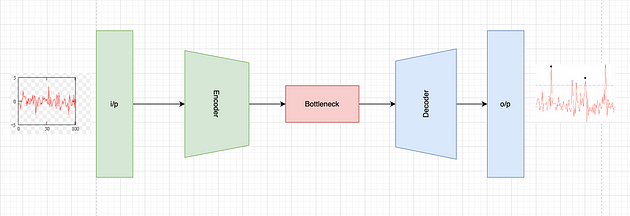
自动编码器是一种神经网络架构,旨在学习输入数据的压缩表示或编码。自动编码器的目标是将输入数据映射到低维潜在空间,然后从编码表示重建输入数据。
自动编码器由两个主要组件组成:编码器和解码器。编码器获取输入数据并将其映射到较低维的潜在空间,而解码器获取编码表示并将其映射回原始输入空间。
编码器和解码器通常被实现为神经网络,编码器网络学习将输入数据编码成紧凑表示,而解码器网络学习从编码表示重建输入数据。
02、主题
使用自动编码器的时间序列异常检测是一种检测序列数据中异常模式的方法。自动编码器是一种神经网络,可以学习将输入数据编码为低维表示,然后将其解码回原始输入。通过在正常时间序列数据的数据集上训练自动编码器,它可以学习重建数据中的正常模式。
为了检测时间序列数据中的异常,经过训练的自动编码器可用于重建新的数据点。如果原始数据点与其重建版本之间的差异高于某个阈值,则该数据点被视为异常。不同类型的自动编码器可用于时间序列异常检测,例如堆叠自动编码器、卷积自动编码器或循环自动编码器。
使用自动编码器的时间序列异常检测已应用于多个领域,例如金融、医疗保健和工业。它可用于检测金融交易中的异常模式、检测传感器数据中的异常行为或检测医疗时间序列数据中的异常。然而,需要注意的是,自动编码器可能并不是所有类型的异常检测任务的最佳选择,并且其他方法(例如支持向量机或聚类算法)在某些情况下可能更合适。
03、代码
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose
from matplotlib import rcParams
from keras.models import Sequential, Model
from keras.layers import LSTM, RepeatVector, TimeDistributed, Dense, Input定义以下代码库中使用的一些全局常量
DATA_FILEPATH = 'power_consumption.txt'
TRAIN_SIZE = 800
EXT_LSTM_UNITS = 64
INT_LSTM_UNITS = 32定义方法并使代码更加模块化
def load_data(filepath):
"""Load time series data from file."""
project_data = pd.read_csv(filepath, delimiter=";")
project_data['timestamp'] = pd.to_datetime(project_data['Date']+' '+project_data['Time'])
project_data['Global_active_power'] = pd.to_numeric(project_data['Global_active_power'], errors='coerce')
project_data = project_data[["timestamp", "Global_active_power"]]
project_data.fillna(value=project_data['Global_active_power'].mean(), inplace=True)
project_data.isna().sum()
project_data.info()
project_data.set_index('timestamp',inplace=True)
return project_data
def compute_seasonal_decomposition(filepath):
project_data = pd.read_csv(filepath, delimiter=";")
project_data['timestamp'] = pd.to_datetime(project_data['Date']+' '+project_data['Time'])
project_data['Global_active_power'] = pd.to_numeric(project_data['Global_active_power'], errors='coerce')
project_data = project_data[["timestamp", "Global_active_power"]]
# Change the default figsize
rcParams['figure.figsize'] = 12, 8
# Decompose and plot
decomposed = seasonal_decompose(project_data, model='additive')
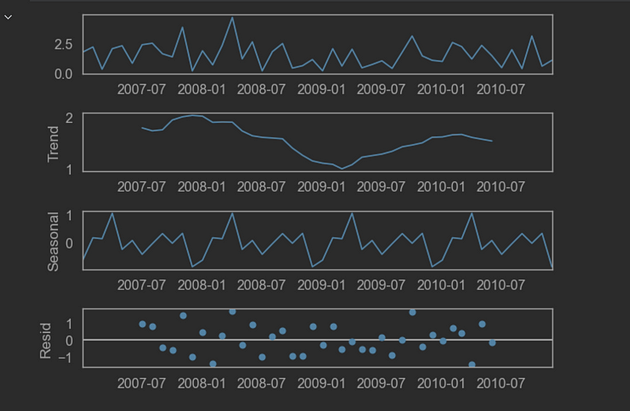
decomposed.plot();季节性分解是时间序列分析中使用的一种常用技术,用于将时间序列分解为其基本组成部分:趋势、季节性和噪声/残差。计算季节性分解的主要目的是更好地理解时间序列数据中的潜在模式,并促进预测和异常检测。
通过将时间序列分解为其趋势、季节性和噪声分量,分析师可以深入了解每个分量如何对时间序列的整体行为做出贡献。趋势成分代表时间序列的长期行为,而季节性成分捕获定期发生的重复模式。噪声/残差分量代表数据中无法用趋势或季节性解释的随机波动。
def split_data(data, train_size):
"""Split time series data into train and test sets."""
train_data = data.iloc[:train_size, :]
test_data = data.iloc[train_size:, :]
return train_data, test_data
def normalize_data(train_data, test_data):
"""Normalize time series data to have zero mean and unit variance."""
mean = train_data.mean(axis=0)
std = train_data.std(axis=0)
train_data = (train_data - mean) / std
test_data = (test_data - mean) / std
return mean, std, train_data, test_data
def build_model_v2(input_shape, ext_lstm_units, int_lstm_units):
"""Build LSTM Autoencoder model."""
input_layer = Input(shape=input_shape)
encoder = LSTM(ext_lstm_units, activation='relu', return_sequences=True)(input_layer)
encoder_1 = LSTM(int_lstm_units, activation='relu')(encoder)
repeat = RepeatVector(input_shape[0])(encoder_1)
decoder = LSTM(int_lstm_units, activation='relu', return_sequences=True)(repeat)
decoder_1 = LSTM(ext_lstm_units, activation='relu', return_sequences=True)(decoder)
output_layer = TimeDistributed(Dense(input_shape[1]))(decoder_1)
model = Model(inputs=input_layer, outputs=output_layer)
model.compile(optimizer='adam', loss='mse')
return model
def train_model(model, train_data):
"""Train LSTM Autoencoder model on train data. For more better results please experiment with epochs"""
history = model.fit(train_data, train_data, epochs=2, batch_size=100, validation_split=0.2)
return history
def predict(model, test_data):
"""Use LSTM Autoencoder model to predict on test data."""
predictions = model.predict(test_data)
return predictions
def calculate_error(test_data, predictions):
"""Calculate mean squared error between test data and predictions."""
print("test_data shape", test_data.shape)
print("predictions shape", predictions.shape)
mse = np.mean(np.power(test_data - predictions, 2), axis=1)
return mse
def detect_anomalies(mse):
"""Detect anomalies in test data using thresholding."""
threshold = np.mean(mse) + 3*np.std(mse)
print("Threshold = ", np.round(threshold, 2))
anomalies = np.where(mse > np.round(threshold, 2))[0]
return anomalies
def plot_results(test_data, anomalies):
"""Plot test data with detected anomalies."""
plt.subplots(figsize=(14, 10))
plt.plot(test_data)
plt.plot(anomalies, test_data['Global_active_power'][anomalies], 'ro')
plt.figure(figsize=(12,4))
plt.title('Power consumption Anomaly Detection')
plt.xlabel('Date')
plt.ylabel('Consumption ')
plt.grid()
plt.show()下面是上述方法的执行流程
#从文件加载数据
df = load_data(DATA_FILEPATH)
df.head() #
在训练集和测试集之间分割数据
train_data, test_data = split_data(df, TRAIN_SIZE)
# 标准化数据
mean, std, train_data, test_data = normalize_data( train_data, test_data)
print ( "Mean: " , Mean)
print ( "标准差: " , std)
# 构建模型
INPUT_SHAPE = (train_data.shape[ 1 ], 1 )
# model = build_model(INPUT_SHAPE, LSTM_UNITS)
model = build_model_v2 (INPUT_SHAPE, EXT_LSTM_UNITS, INT_LSTM_UNITS)
# 训练模型
历史记录 = train_model(model, train_data)
# 对测试数据进行
预测 test_predictions = Predict(model, test_data)
# 计算每个时间步的重建误差
mse =calculate_error(test_data, test_predictions.reshape( 2074459) , 1 ))
print ( "Mean Square Error = " , mse)
# 检测测试数据中的异常 anomalies
= detector_anomalies(mse)
# 绘制带有异常的测试数据
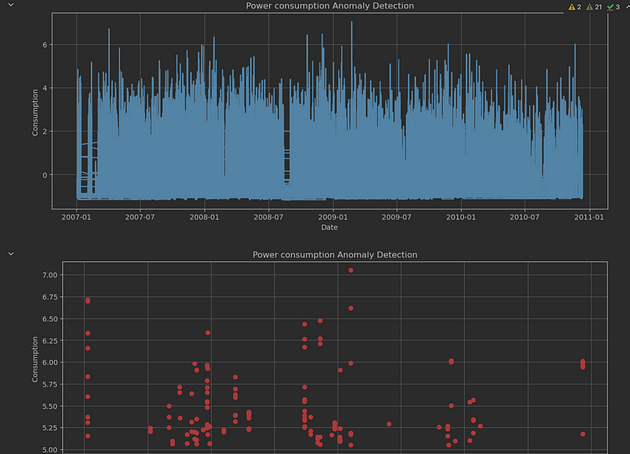
plot_results(test_data, anomalies)计算得出的阈值为 0.04,异常情况如下所示
04、总结
近年来,使用自动编码器进行时间序列异常检测已成为越来越流行的方法。自动编码器可以接受时间序列数据的训练,以学习数据点之间的正常模式和关系。经过训练后,自动编码器可用于通过测量输入数据和重建数据之间的差异来检测异常。
使用自动编码器进行时间序列异常检测的主要优点之一是可以对大量数据进行训练,而无需手动进行特征工程。这使得它们对于分析具有多个变量或高维的复杂时间序列数据特别有用。
总体而言,使用自动编码器进行时间序列异常检测代表了一个有前途的研究领域,有可能为包括金融、医疗保健和工业在内的广泛应用提供显着的好处。然而,应仔细考虑时间序列数据和异常检测任务的具体特征,以确定自动编码器是否是最适合该工作的方法。
















 759
759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











