






1、引言
本文涵盖主题:XGBoost 实现回归分析,包括数据准备、模型训练和结果分析三个方面。
本期内容『数据+代码』已上传百度网盘。有需要的朋友可以关注公众号【小Z的科研日常】,后台回复关键词[xgboost]获取。
2、数据准备
本例中,我们使用的是1973年至2016年间美国燃烧煤炭发电产生的二氧化碳排放量数据集。
数据帧包含需要分隔为年和月列的列“YYYYMM”。在此步骤中,我们还将删除数据帧中可能存在的任何空值。将特征工程中新增的年、月列替换“YYYYMM”,同时查询数据中是否含有重复值,如有需另作处理,本数据集不涵盖。
data = pd.read_csv('co2.csv')
data['Month'] = data.YYYYMM.astype(str).str[4:6].astype(float)
data['Year'] = data.YYYYMM.astype(str).str[0:4].astype(float)
data.drop(['YYYYMM'], axis=1, inplace=True)
data.replace([np.inf, -np.inf], np.nan, inplace=True)
data.isnull().sum()将月份和年份作为特征,CO2 排放量作为标签。
X = data.loc[:,['Month', 'Year']].values
y = data.loc[:,'Value'].values使用 train_test_split 函数来划分出训练集和测试集:
from sklearn.model_selection import train_test_split
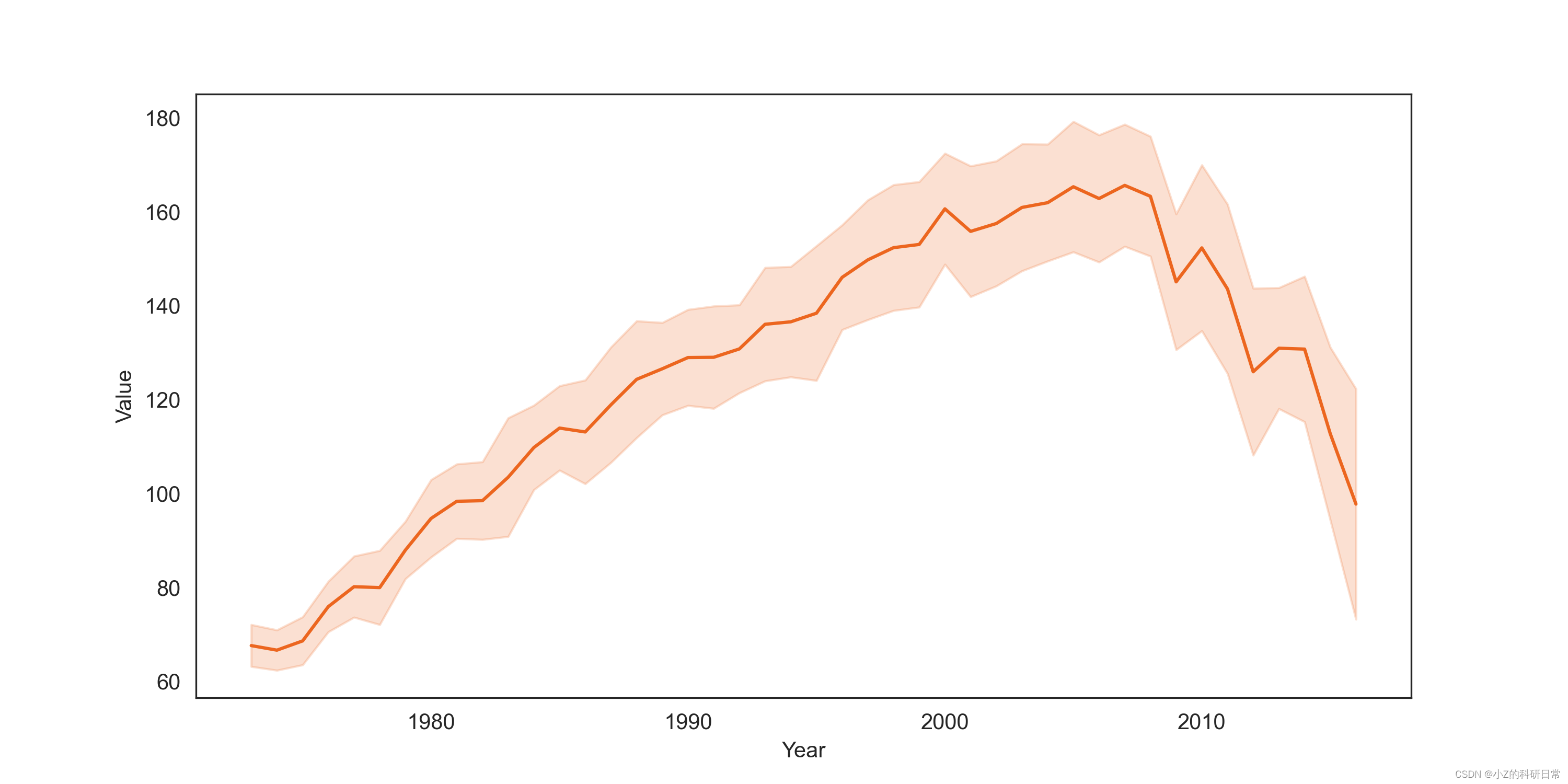
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)可视化X、y,观察随时间变化,co2含量变化:
plt.figure(figsize=(10, 5), dpi=300)
sns.lineplot(x='Year', y='Value', data=data,errorbar='sd', err_style='band',color="#ec661f")如图:
3、模型训练
使用 XGBoost 建立回归模型并进行训练。这里需要设置一系列参数,例如 n_estimators(基分类器数量)、learning_rate(学习率)、subsample(子采样比例)、colsample_bytree(列采样比例)、max_depth(树的最大深度)和 gamma(用于控制树的复杂度)等参数。
reg_mod = xgb.XGBRegressor(
n_estimators=1000,
learning_rate=0.08,
subsample=0.75,
colsample_bytree=1,
max_depth=7,
gamma=0,
)
# 训练模型并指定评估数据集
eval_set = [(X_train, y_train), (X_test, y_test)]
reg_mod.fit(X_train, y_train, eval_set=eval_set, eval_metric='rmse', verbose=False)
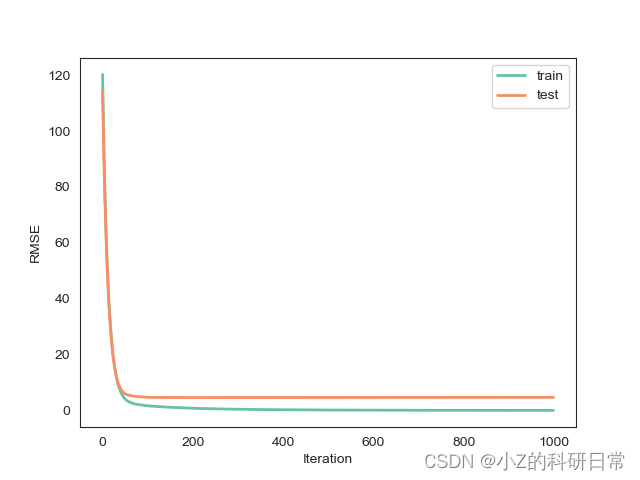
# 绘制损失曲线
sns.set_style("white")
palette = sns.color_palette("Set2", n_colors=2)
plt.plot(reg_mod.evals_result()['validation_0']['rmse'], label='train', color=palette[0], linewidth=2)
plt.plot(reg_mod.evals_result()['validation_1']['rmse'], label='test', color=palette[1], linewidth=2)
plt.xlabel('Iteration')
plt.ylabel('RMSE')
plt.legend()
plt.savefig('Loss.png')
plt.show()模型损失曲线如图:
同时,模型还需要进行交叉验证和评估指标选择,例如 RMSE 和 R_Squared Score 等。以下是对模型进行训练和评估的代码:
from sklearn.metrics import r2_score
reg_mod.fit(X_train, y_train)
scores = cross_val_score(reg_mod, X_train, y_train,cv=10)
print("Mean cross-validation score: %.2f" % scores.mean())
rmse = np.sqrt(mean_squared_error(y_test, predictions))
print("RMSE: %f" % (rmse))
r2 = np.sqrt(r2_score(y_test, predictions))
print("R_Squared Score : %f" % (r2))模型评估结果如下:
-
Mean cross-validation score: 0.97
-
RMSE: 4.683184
-
R_Squared Score : 0.989909
通过上述模型评估结果可知,该模型针对此数据能够较好的拟合,通过下述代码,观察测试集拟合效果:
sns.set_style("white")
palette = sns.color_palette("husl", n_colors=2)
# 设置画布大小和分辨率
plt.figure(figsize=(10, 5), dpi=300)
# 绘制测试集数据的真实值和模型预测值的折线图
x_ax = range(len(y_test))
plt.plot(x_ax, y_test, label="True Values", color=palette[0], linewidth=1)
plt.plot(x_ax, predictions, label="Predicted Values", color=palette[1], linewidth=1)
# 添加标题和标签
plt.title("Carbon Dioxide Emissions - True vs Predicted Values")
plt.xlabel("Sample Number")
plt.ylabel("CO2 Emissions")
# 显示图例
plt.legend()
plt.savefig('True vs Predicted Values.png')
# 显示图形
plt.show()拟合曲线如图:
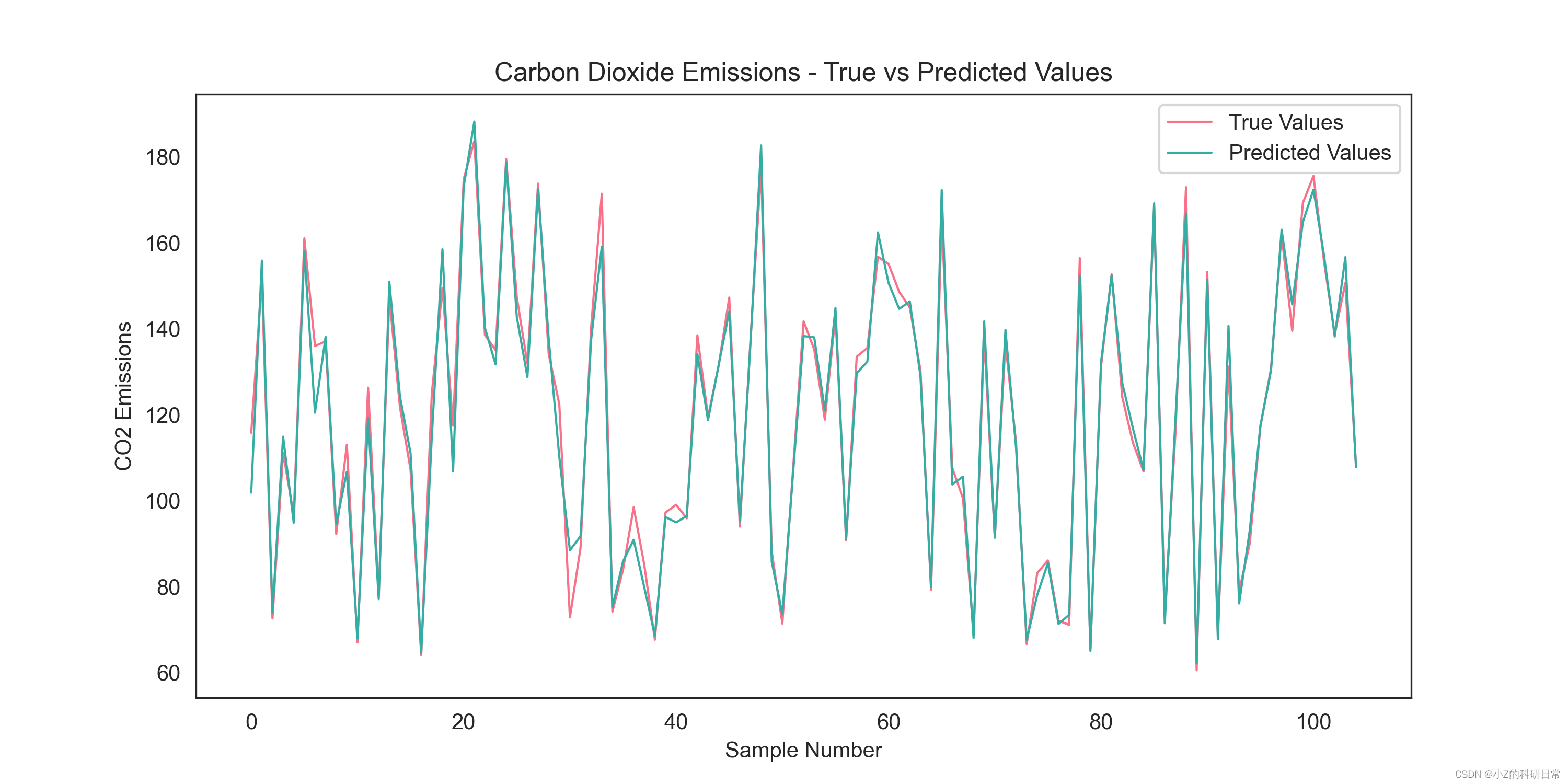
通过上图可知,模型拟合效果较好,能够有效预测数据中峰值等信息。
上述各数据及图标表明,该模型具有较高准确率,通过下述代码,观察未来日期内co2含量:
sns.set_style("white")
palette = sns.color_palette("husl", n_colors=1)
# 设置画布大小和分辨率
plt.figure(figsize=(10, 5), dpi=300)
# 将预测值转换为DataFrame格式,并添加日期列
df_pred = pd.DataFrame(predictions, columns=['Predicted Values'])
df_pred['Date'] = pd.date_range(start='8/1/2016', periods=len(df_pred), freq='M')
# 绘制预测值的折线图
sns.lineplot(x='Date', y='Predicted Values', data=df_pred, color=palette[0], linewidth=1)
# 添加标题和标签
plt.title("Carbon Dioxide Emissions - Forecast")
plt.xlabel("Date")
plt.ylabel("CO2 Emissions")
plt.savefig('Emissions - Forecast.png')
# 显示图形
plt.show()预测曲线如图:
感谢您阅读本篇文章!如果您对神经网络与深度学习等方面感兴趣,欢迎关注我们的微信公众号(小Z的科研日常)。


















 1694
1694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











