







Attention Is All You Need【解读笔记】
工作内容简介
递归神经网络,特别是长短期记忆和门控递归神经网络,已经作为序列建模和转导问题(如语言建模和机器翻译)中的最新方法得到了牢固的确立。自那以后,无数的努力继续推进递归语言模型和编码器-解码器架构的边界。
而在这项工作中,主要提出了 Transformer:
- 这是一种
避免递归的模型架构,它完全依赖于一 种注意机制来绘制输入和输出之间的全局依赖关系。 - Transformer 支持
更高的并行度,在八 个 P100 GPU 上训练了短短 12 个小时后,翻译质量就达到了新的水平。
由于之前构建的那些模型关联两个任意输入或输出位置的信号所需的运算次数随着位置之间的距离增加而增加,ConvS2S 为线性,ByteNet 为对数。这使得学习遥远位置之间的依赖性变得更加困难。
在 Transformer 中,这被减少到恒定数量的操作,尽管代价是由于平均注意力加权位置而降低了有效分辨率,但也提出了多头注意力(Multi-Head Attention)抵消了这种效应。
Transformer 是第一个完全依赖自我关注来计算其输入和输出表示而不 使用序列比对 RNNs 或卷积的转导模型。
模型结构简要解析
简要说明LSTM结构


对于我们可以先把中间那一坨遮起来,看一下LSTM在t时刻的输入与输出,首先,输入有三个: 细胞状态 C t − 1 C_{t-1} Ct−1,隐层状态 h t − 1 h_{t-1} ht−1 , $t 时 刻 输 入 向 量 时刻输入向量 时刻输入向量X_t , 而 输 出 有 两 个 : 细 胞 状 态 ,而输出有两个:细胞状态 ,而输出有两个:细胞状态C_t , 隐 层 状 态 , 隐层状态 ,隐层状态h_t$ 。其中 h t h_t ht还作为 t t t时刻的输出。
至于绿色框内部的结构与逻辑,我会在下面详细的讲,不过当前,我们从这个图里,只需要看出个大概就行了:
- 细胞状态$C_{t-1} 的 信 息 , 一 直 在 上 面 那 条 线 上 传 递 , 的信息,一直在上面那条线上传递, 的信息,一直在上面那条线上传递,t 时 刻 的 隐 层 状 态 时刻的隐层状态 时刻的隐层状态h_t 与 输 入 与输入 与输入x_t 会 对 会对 会对C_t$进行适当修改,然后传到下一时刻去。
- C t − 1 C_{t-1} Ct−1会参与 t t t时刻输出 h t h_t ht的计算。
- 隐层状态 h t − 1 h_{t-1} ht−1的信息,通过LSTM的“门”结构,对细胞状态进行修改,并且参与输出的计算。
总的来说呢,细胞状态的信息一直在上面那条线上传递,隐层状态一直在下面那条线上传递,不过它们会有一些交互,在LSTM中,通常被叫做“门”结构。
上面这几个黄色的图案,这东西代表一个“神经元”,也就是 w T x + b w^T x + b wTx+b的操作。区别在于使用的激活函数不同, σ \sigma σ表示sigmoid函数,它的输出是在0到1之间的, t a n h tanh tanh是双曲正切函数,它的输出在-1到1之间。
这个粉色的操作,根据图里画的内容,操作略有不同,不过整体的意思就是向量的按元素操作。可以认为是,两个相同维度的向量,对应的元素进行圆圈内部的操作,比如✖️就是两个相同维度对应元素的乘积组成新的向量。
编码器-解码器结构
大多数竞争性神经序列转导模型都有一个编码器-解码器结构。这里,编码器将 符号表示的输入序列 ( x 1 , . . . , x n ) (x_1,...,x_n) (x1,...,xn)转换为连续表示序列$ z = (z_1,…,z_n) 。 给 定 。给定 。给定 z , 解 码 器 然 后 生 成 输 出 序 列 ,解 码器然后生成输出序列 ,解码器然后生成输出序列(y_1,…y_m)$,一次一个元素。在每一步,模型都是自回归的, 在生成下一步时,消耗先前生成的符号作为附加输入。
Transformer遵循这种整体架构,对编码器和解码器使用堆叠自关注和逐点全连接层,分别如图 1 的左半部分和右半部分所示。

编码器:编码器由 N = 6 N = 6 N=6个相同层的堆叠组成。每层有两个子层。第一种是多头自关注机制,第二种是简单的、按位置完全连接的前馈网络。我们在每个周围使用剩余连接这两个子层,接着是层归一化。也就是说,每个子层的输出是 L a y e r N o r m ( x + S u b l a y e r ( x ) ) LayerNorm(x + Sublayer(x)) LayerNorm(x+Sublayer(x)),其中 S u b l a y e r ( x ) Sublayer(x) Sublayer(x)是子层实现的功能 本身。为了促进这些剩余连接,模型中的所有子层以及嵌入层产生维度 d m o d e l d_{model} dmodel = 512的输出。
解码器:解码器也由 N = 6 N = 6 N=6个相同层的堆叠组成。除了这两个子层在每个编码器层中,解码器插入第三个子层,执行多头注意编码器堆栈的输出。类似于编码器,我们使用剩余连接 围绕每个子层,然后进行层归一化。我们也改变了自我关注 解码器堆栈中的子层,用于防止位置关注后续位置。这 屏蔽,结合输出嵌入偏移一个位置的事实,确保 位置I的预测只能依赖于小于I的位置处的已知输出。
注意力机制
在解释下列问题之前,需要了解以下几篇博客。
注意机制可以描述为将查询和一组键-值对映射到输出,其中查询、键、值和输出都是向 量。输出被计算为值的加权和,其中分配给每个值的权重由查询与相应键的兼容性函数来计算。

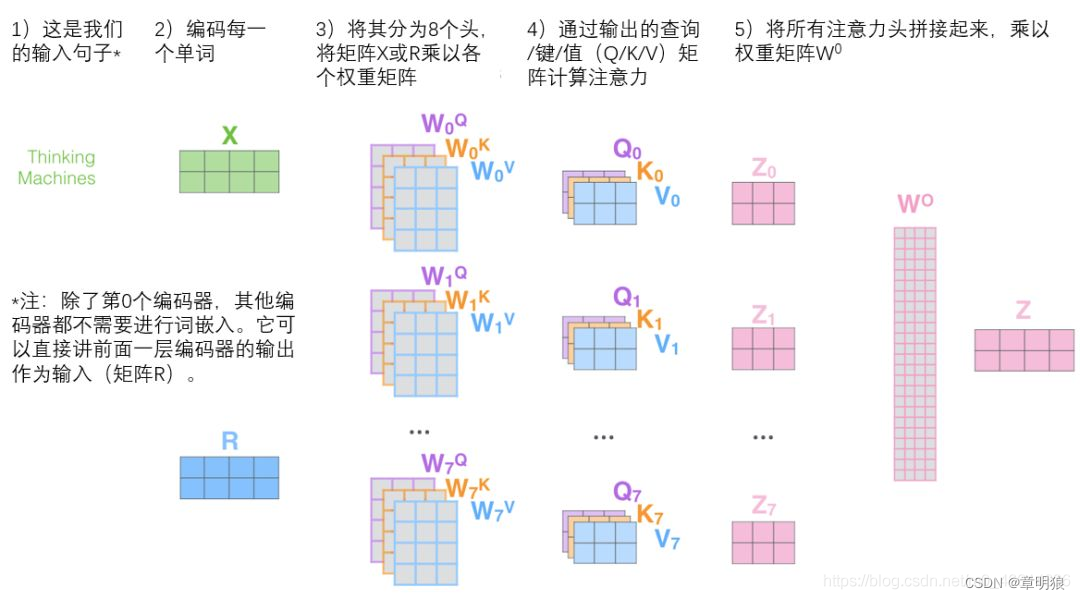
多头注意力:在实践中,当给定相同的查询、键和值的集合时,我们希望模型可以基于相同的注意力机制学习到不同的行为,然后将不同的行为作为知识组合起来,例如捕获序列内各种范围的依赖关系(例如,短距离依赖和长距离依赖)。因此,允许注意力机制组合使用查询、键和值的不同的 子空间表示(representation subspaces)可能是有益的。
为此,与使用单独的一个注意力池化不同,我们可以独立学习得到
h
h
h 组不同的 线性投影(linear projections)来变换查询、键和值。然后,这
h
h
h组变换后的查询、键和值将并行地进行注意力池化。最后,将这
h
h
h个注意力池化的输出拼接在一起,并且通过另一个可以学习的线性投影进行变换,以产生最终输出。这种设计被称为 多头注意力,其中
h
h
h个注意力池化输出中的每一个输出都被称作一个 头 Vaswani.Shazeer.Parmar.ea.2017。下图展示了使用全连接层来实现可以学习的线性变换的多头注意力。(可学习什么是多头注意力机制)

Transformer以三种不同的方式使用多头注意力:
- 在“编码器-解码器注意”层中,查询来自前一个解码器层,存储器键和值来自编码器的输出。这允许解码器中的每一个位置关注输入序列中的所有位置。这模仿了序列到序列模型中典型的编码器-解码器注意机制。
- 编码器包含自我关注层。在自关注层中,所有的键、值和查询都来自同一个地方, 在这种情况下,是编码器中前一层的输出。编码器中的每个位置可以关注编码器的前一层中的所有位置。
- 类似地,解码器中的自关注层允许解码器中的每个位置关注解码器中的所有位置, 直到并包括该位置。我们需要防止解码器中的向左信息流,以保持自回归特性。我 们通过屏蔽(设置为 − ∞ -\infty −∞)softmax的输入中与非法连接相对应的所有值,在比例点积注意中实现这一点。参见图 2。
结论
在这项工作中,我们提出了 Transformer,这是第一个完全基于注意力的序列转导模型, 用多头自我注意力取代了编码器-解码器架构中最常用的递归层。
用于训练和评估模型的代码可从以下网址获得 https://github.com/tensorflow/tensor2tensor
加深理解可阅读一下博客
参考学习网址:















 942
942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









