







 本文探讨了汉语自动分词的策略,包括形态分析、分词方法(最大匹配、最少分词、统计模型),以及词性标注的难点、评价指标和常见问题。重点介绍了歧义处理、未登录词识别和词性标注的规则。
本文探讨了汉语自动分词的策略,包括形态分析、分词方法(最大匹配、最少分词、统计模型),以及词性标注的难点、评价指标和常见问题。重点介绍了歧义处理、未登录词识别和词性标注的规则。
三种语系*
- 屈折语:用词的形态变化表示语法关系;
- 黏着语:词内有专门表示语法意义的附加成分,词根或词干与附加成分结合不紧密;
- 孤立语/分析语:形态变化少,语法关系靠词序和虚词表示。
他们的词法分析方式也不同:
- 词的形态还原;
- 分词+形态还原;
- 分词;
英语的形态分析
包含以下五种情况:
- 特殊形式的单词识别,如:let’s,I’ll…
- 有规律变化单词的形态还原,如:ed,ing,s…
- 动词、名词、形容词、副词不规则变化,如:choose、chose、chosen,axis、axes…
- 对于表示年代、时间、百分数、货币、序数词的数字形态还原,如:¥20…;
- 合成词的形态还原,如:Human-computer…;
形态分析的一般方法*
- 查词典,如果词典中有该词,直接确定该词的原型;
- 根据不同情况查找相应规则对单词进行还原处理,如果还原后在词典中找到该词,则得到该词原型;如果找不到相应变换规则或者变换后词典中仍然查不到该词,则作为未登录词处理;
- 进入未登录词处理模块。
汉语自动分词概要
重要性
- 自动分词是汉语句子分析的重要基础;
- 词语的分析具有广泛的应用统计;
- 文献处理以词语为文本特征;
- 以词定字,以字定音。
主要问题*
汉语分词规范问题
“词是什么”、“什么是词”这是两个基本问题。
困难主要来自于两方面:
- 单字词和词素之间的划界;
- 词与短语的划界。
歧义切分字段处理*
交集型切分歧义:汉字串AJB被称为交集型切分歧义,如果满足AJ、BJ同时为词,此时J被称作交集串。
链长:一个交集型切分歧义所拥有的交集串的集合称为交集串链,它的个数称为链长。
题型十四:判断链长*

组合型歧义:汉字串AB称作组合型切分歧义,如果满足A,B,AB同时为词。
比如:将来、现在、才能、学生会等;
未登录词的识别
- 人名、地名、组织机构名;
- 新出现的词汇、术语、个别俗语。
基本原则*
- 语义上无法由组合成分直接相加而得到的字串应该合并为一个分词单位;(比如半斤八两,半斤和八两都是数量,但合在一起表示其他的意思)
- 语类无法由组合成分直接得到的字串应该合并为一个分词单位(好吃(字串的语法功能不符合组合规律)、游水(字串的内部结构不符合语法规律))。
辅助原则:
- 有明显分隔符标记的应该切分(上、下课 —— 上/下课);
- 附着性语素和前后词合并为一个分词单位(员:检查员);
- 使用频率高或共现率高的字串尽量合并为一个分词单位(收放);
- 双音节加单音节的偏正式名词尽量和并为一个分词单位(着眼点);
- 内部结构复杂、合并起来过于冗长的词尽量切分(参加/不/参加);
分词与词性标注结果评价方法
两种测试:
- 封闭测试/开放测试;
- 专项测试/总体测试。
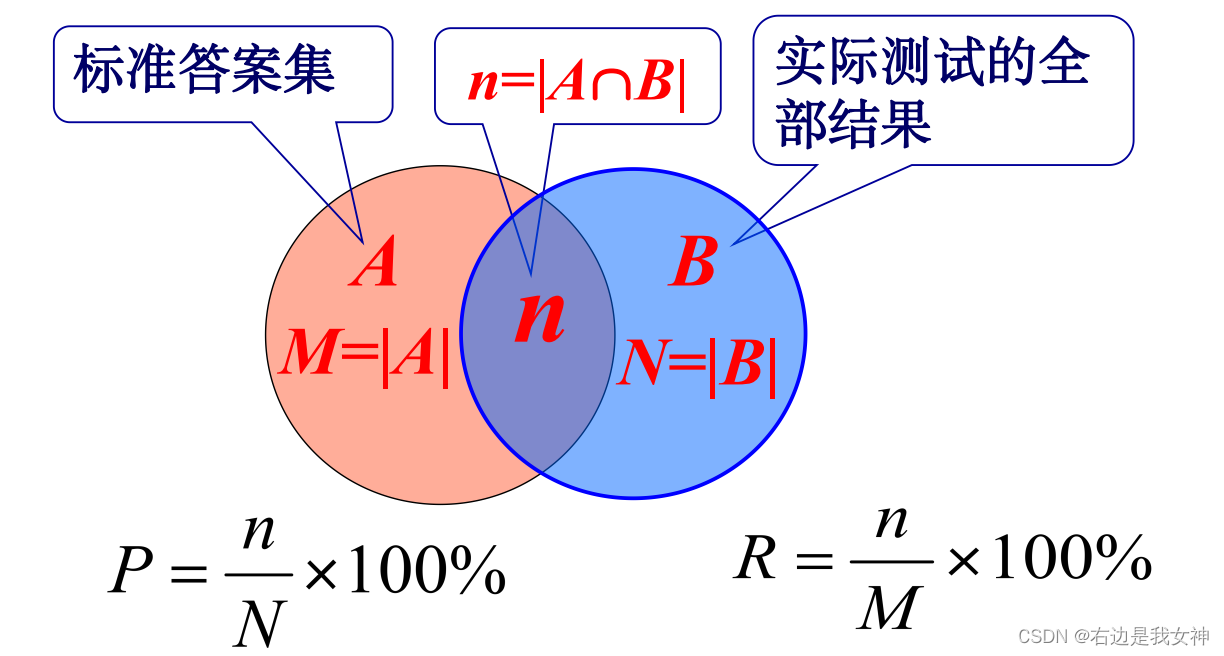
评价指标*
精确度
测试结果中,正确切分或标注的个数占系统所有输出结果的比例。假设系统输出N个,其中,正确的结果为n个,那么 P = n N × 100 % P=\frac{n}{N}\times 100\% P=Nn×100%
全部输出结果就是 T P + N P TP+NP TP+NP,正确结果就是 T P TP TP。
召回率
测试结果中正确结果的个数占标准答案的比例,假设系统输出N个结果,其中,正确的结果为n个,而标准答案的个数为M个,那么 R = n M × 100 % R=\frac{n}{M}\times100\% R=Mn×100%
标准答案就是 T P + T N TP+TN TP+TN。
F-Measure
F = β 2 + 1 β 2 P × R P + R F=\frac{\beta^2+1}{\beta^2}\frac{P\times R}{P+R} F=β2β2+1P+RP×R
题型十五:评价指标计算

自动分词基本算法
- 有词典切分/无词典切分;
- 基于规则的方法/基于统计的方法。
最大匹配法(Maximum Matching)*
有词典切分。
- 正向最大匹配算法(FMM);
- 逆向最大匹配算法(BMM);
- 双向最大匹配算法(MM)。
假设句子: S = c 1 c 2 . . . c n S=c_1c_2...c_n S=c1c2...cn,某一词: w i = c 1 c 2 . . . c m w_i=c_1c_2...c_m wi=c1c2...cm,m为词典中最长词的字数。
FMM算法描述
- 令 i = 0 i=0 i=0,当前指针 p i p_i pi指向输入字串的初始位置,执行下面操作:
- 计算当前指针 p i p_i pi到字串末端的字数(即未被切分字串的长度)n,如果 n = 1 n=1 n=1,转4,结束算法。否则,令m=词典中最长单词的字数,如果 n < m n\lt m n<m,令 m = n m=n m=n;
- 从当前
p
i
p_i
pi起取m个汉字作为词
w
i
w_i
wi,判断:
a. 如果 w i w_i wi确实是词典中的词,则在 w i w_i wi后面添加一个切分标志,转c;
b. 如果 w i w_i wi不是词典中的词且 w i w_i wi的长度大于1,将 w i w_i wi从右端去掉一个字,转a;否则( w i w_i wi的长度等于1),则在 w i w_i wi后面添加一个切分标志,将 w i w_i wi作为单字词添加到词典中,执行c;
c. 根据 w i w_i wi的长度修改指针 p i p_i pi的位置,如果 p i p_i pi指向字串末端,转4,否则 i = i + 1 i=i+1 i=i+1,返回2; - 输出切分结果,结束分词程序。
首先,进行初始化;接着判断是否结束,若未结束设置字长;取汉字进行分词(3步走,在不在词典中)。
优点:
- 程序简单易行,开发周期短;
- 仅需要很少的语言资源,不需要任何词法、句法、语义资源;
缺点: - 歧义消解能力差;
- 切分正确率不高,一般在95%。
最少分词法(最短路径法)*
根据字典。
基本思想:
算法描述:
- 相邻节点 v k − 1 , v k v_{k-1},v_k vk−1,vk之间建立有向边 < v k − 1 , v k > <v_{k-1},v_k> <vk−1,vk>,边对应的词默认为 c k ( k = 1 , 2 , . . . , n ) c_k(k=1,2,...,n) ck(k=1,2,...,n)。
- 如果 w = c i c i + 1 . . . c j ( 0 < i < j ≤ n ) w=c_ic_{i+1}...c_j(0\lt i\lt j\le n) w=cici+1...cj(0<i<j≤n)是一个词,则节点 v i − 1 , v j v_{i-1},v_j vi−1,vj之间建立有向边<v_{i-1},v_j>,边对应的词为 w w w。
- 重复步骤2,直到没有新路径产生。
- 从产生的所有路径中,选择路径最短作为最终分词结果。
词是节点的间隔,如果几个间隔是一个词,那么两个节点可以直接相连接。
首先,相邻节点之间建立边;然后如果连续边是一个词,那么两端的节点直接相连;重复直到没有新路径产生;选择最短路径作为最终分词结果。
优点:
- 切分原则符合汉语自身规律;
- 需要的语言资源不是很多;
缺点:
- 对歧义字段难以区分;
- 字串长度较大和选取的最短路径数增大时,长度相同的路径数急剧增加,难以选择最终结果。
基于语言模型的分词方式(统计方法)*
优点:
- 减少了很多手工标注的工作;
- 在训练语料规模足够大和覆盖的领域足够多时,可以获得较高的准确率。
缺点:
- 训练语料的规模和覆盖领域不好把握;
- 计算量较大。
由字构成词的分词方法
基本思想:将分词的过程看作是字的分类。该方法认为,每个字在构成一个特定的词语时,都占据着一个确定的构词位置,即词位。比如说每个字可以有四个词位:词首(B)、词中(M)、词尾(E)和单独成词(S)。
依据分类结果划分就行。
优点:
- 平衡看待词表词和未登录词的识别问题,文本中的词表词和未登录词都是用统一的字标注过程来实现;
- 在学习架构上,也不必强调词表词信息,也不用专门设计特定的未登录词识别模块,因此,大大简化了分词系统的设计。
基于字的生成式模型和区分式模型相结合的汉语分词方法
生成式模型:n元语法模型;
区分式模型:由字构成词的分词方法。
生成式模型对于集内词(词典词)的处理可能获得较好的效果,但对于集外词(未登录词)的分词效果欠佳。基于字的区分式模型则相反。
生成式模型
假设o是观察值,q是模型。如果对 p ( o ∣ q ) p(o|q) p(o∣q)建模,就是生成式模型。其基本思想是:首先建立样本的概率密度模型,再利用模型进行推理预测。要求已知样本无穷多或者尽可能地多。该方法一般建立在统计学和Bayes的基础上。
主要特点是:从统计的角度表示数据的分布情况,能够反映同类数据本身的相似度;
主要优点是:所带的信息比判别式模型丰富;
主要缺点是:学习和计算过程比较复杂。
判别式模型
对条件概率建模。在有限样本条件下建立判别函数,不考虑样本的产生模型,直接研究预测模型。
主要特点是:寻找不同类别之间的最优分类面,反映异类数据之间的差异;
主要优点是:容易学习;
主要缺点是:黑盒操作,变量关系不清楚。
其他方法介绍
全切分方法:首先切分处与词表匹配的所有可能词,然后用统计语言模型和决策算法决定最优切分结果。优点是可以发现所有的切分歧义,但取决于统计语言模型和决策算法;缺点是需要大量的标注语料,分词速度慢。
未登录词识别
中文姓名识别方法*
- 姓名库匹配,以姓氏作为触发信息,寻找潜在名字;
- 计算潜在姓名的概率估值及相应姓氏的姓名阈值,根据姓名概率评价函数和**
**对潜在的姓名进行筛选。





词性标注概述
面临的问题*
词性标注的主要任务是消除词性兼类歧义。这在任何一种语言中都普遍存在。
如英语而言:
Time flies like an arrow,不同的词性会带来不同的解释。
在汉语中:
- 形同音不同(他这个人什么都好,就是好酗酒);
- 同形、同音,但意义不相干(每次他都会在会上制造点新闻);
- 具有典型意义的兼类词(教育孩子、教育事业);
- 上述情况的组合(银行,行注目礼,彼此之间同形不同音,单独的话同音同形)。
标注集的确定原则*
标注的符号规则意义表,辅助词性标注。
一般原则:
- 标准性:普遍使用和认可的分类标准和符号集;
- 兼容性:与已有资源标记尽量一致,或可转换;
- 可扩展性:扩充或修改。
Upenn Treebank的词性标注集确定原则:
- 可恢复性:从标注语料能恢复原词汇或借助于句法信息能区分不同词类;
- 一致性:功能相同的词应该属于同一类;
- 不明确性:为了避免标注着在不明确的条件下任意决定标注类型,允许标注者给出多个标记(仅限于一些特殊情况)。
词性标注方法
手工编写消歧规则*
建立非兼类词典;
建立兼类词典;
构造兼类词识别规则;
规则(为兼类词明确词性)有:
- 并列鉴别规则;词成并列结构(人民的要求和愿望,并列结构,词性统一)
- 同境鉴别规则;词在同一个语境下(优秀的企业必须具备一流的产品、管理、服务,同一语境下,词性统一)
- 区别词鉴别规则(区别词只能直接修饰名词,大型调查,大型是鉴别词,后接名词);
- 唯名形容词鉴别规则(有些形容词只能直接修饰名词,重大损失,重大是唯名形容词,后接名词)。


















 133
133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











