







The Treasure beneath Convolutional Layers:Cross-convolutional-layer Pooling for Image Classification
Abstract
深度卷积网络最后采用全连接层激活图像或者区域表示,这样的方式的区分度很差。
本文采用交叉卷积池化的技术实现对卷积层的激活。
Introduction
预训练好的深度卷积网络能得到一个通用的图像表示,但对于特定任务,如何进一步获得对应的图像表示仍然是一个问题。目前常用的手段是采用全连接层的激活来作为新的图像表示。
一些研究也表明用卷积层激活来作为图像特征的话效果不大行。
本文则认为如果使用得当,卷积层激活也是可以形成一种强大的图像表示的。
因此,本文提出了交叉卷积层池化。
这一结构依赖两个关键组件:
- 在局部特征设置中使用卷积层激活,其中卷积层激活的子数组被提取为区域描述符;
- 使用两个连续卷积层的激活来汇集提取的局部特征。
第一个组件的思路来源:一些工作证明了DCNN的激活并不是平移不变的,此外,从DCNN中提取全连接激活来描述局部区域以及池化多个区域DCNN激活来表示图像是有益的。
因此,本文使用卷积激活的部分作为区域描述。
第二个组件是基于部分的池化方法提出的,该方法为每个检测到的部分区域创建一个池化通道。通过连接多个通道的池化结果获得最终的图像表示。
本文将卷积层中的滤波器的特征映射作为部分检测器的检测响应映射。并将该特征映射应用于池化过程中从前一卷积层中提取的区域描述的权重。
将来自多个通道的池化结果串联起来,每个通道对应一个特征映射,从而得到最终的图像表示。
Proposed Method
Convolutional layers vs. fully-connected layers
卷积层激活相比于全连接层激活的一个主要区别是前者嵌入了丰富的空间信息。
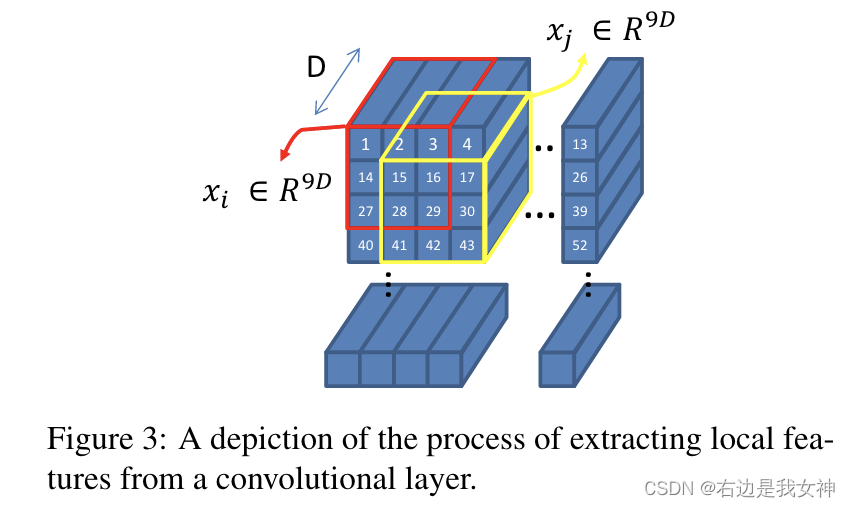
本文将局部的空间单元取出并作纵向的连接。并且,以这样的模式在图上进行平移。
Cross-convolutional-layer Pooling
从卷积层提取局部特征后,可以直接直接行最大池化或者和池化来得到图像级的表示。
本文提出一种其他的池化方法。
首先检测多个ROI,然后将ROI中的局部特征池化。最后将这些向量连接在一起形成图像表示。
我们定义从第k个ROI得到的池化特征为
P
k
t
P_k^t
Pkt,其可以计算为(sum-pooling):
P
k
t
=
∑
i
=
1
x
i
I
i
,
k
P^t_k=\sum_{i=1}x_iI_{i,k}
Pkt=i=1∑xiIi,k
其中
x
i
x_i
xi表示第i个局部特征,
I
i
,
k
I_{i,k}
Ii,k表示
x
i
x_i
xi是否落在第k个ROI。
然而,要想获得这个ROI不是一件简单的事情,但是我们发现卷积层的激活结果是有语义的:

(上图从conv5的256个特征图中随机抽取了一些特征图覆盖在原始图像上,以便更好地可视化)
因此,可以让第 t + 1 t+1 t+1个卷积层的结果作为 D t + 1 D_{t+1} Dt+1个指示映射。
于是,图像可以表示为:

| 变量 | 意义 |
|---|---|
| P t P^t Pt | 第t个卷积层池化后的特征 |
| P k t P_k^t Pkt | 第t个卷积层池化后的第k维度的特征 |
| x i t x_i^t xit | 第t个卷积层的第i个局部特征 |
| a i , k t + 1 a_{i,k}^{t+1} ai,kt+1 | 第t+1个卷积层的第i个空间位置的第k维特征 |
这里在第t个卷积层做了局部特征提取,得到 N t N_t Nt个局部特征,这视为一种卷积,相当于第t+1个卷积层的结果。
之后自然而然做的是特征乘对应的响应,再做一个sum-pooling。
本文也是B-CNN采用外积处理的缘由。两者其实处理的思路在本质上是一样的,不过一个同源,一个是双源。
Bilinear CNN Models for Fine-grained Visual Recognition(by end-to-end feature encoding)
本文是单阶段法的开山之作。
Abstract
本文提出了双线性模型,由两个特征提取器组成。
其输出在图像的每个位置使用外积相乘并合并来获得图像的描述。
这样一种结构可以建模局部的、成对的特征交互(以一种平移不变的方式),这对于细粒度分类尤其有用。
这样一种结构还会产生各种无序纹理描述,比如Fisher向量、VLAD和O2P。
双线性形式简化了梯度计算并允许仅使用图像标签对两个网络进行训练。
说明
后文中对外积的描述可能与一般线代教材的有所区别,涉及到右手定则的外积称为cross product,多出现于解析几何中。而此处指的是outer prduct,是向量之间的相乘。
Introduction
目前的方法主要是检测局部,然后对这些部分进行外观的建模。这样的方法的最大缺陷在于极度依赖于手工标注(成本大且不一定适合识别任务。)。
另一种方法是应用比较鲁棒的图像表征。传统的表征有Fisher vector、VLAD、SIFT等,目前比较好的方法是卷积神经网络。
这一模型以一种平移不变的方式,很适合纹理和细粒度任务。
对比分析:法2解决了法1最大的弊端,但是性能不大行,特别是对于目标比较小或者场景相对杂乱的图像。然后,对法2的端到端的结构的影响没有很好的研究。
本文的输出捕捉了成对的局部特征交互。
本文认为,本文的架构和人脑视觉处理的双流假说有关,ventral stream涉及到目标的检测和识别。dorsal stream涉及到处理目标相对于观察者的空间位置。
Bilinear models for image classification

















 8022
8022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











