






大家都是穷鬼,都不喜欢看到

现在csdn上关于vllm流式推理部署的文章全部都收费,这么简单的一个方法至于这样吗?都藏着掖着
安装vllm
我用的vllm版本为0.5.0.post1
pip install vllm
我的torch版本是2.3.0,对应nccl是2.20.5,多卡推理需要用到
pip install nvidia-nccl-cu12==2.20.5
部署
python -m vllm.entrypoints.openai.api_server --host 192.168.10.61 --port 7862 --model /home/hyh/model/Qwen2-7B-Instruct --served-model-name Qwen --tensor-parallel-size 2 --dtype=half
--host 写服务器地址或者默认localhost
--port 同上,我是因为8000端口被占用了所以要改
--model 写本地下载好的模型路径
--served-model-name 给这个模型起名,这样后面请求时不用输入模型完整路径
--tensor-parallel-size 在几张卡上运行,我这里用了2张,如果你的单卡显存在20G以上可以不写
--dtype=half 我的显卡算力是7.5不支持bf16,所以要转换成fp16,如果你的显卡好可以不写
流式推理代码
requests请求
必须传入"model"、“messages”、“stream”
这里的"model"和部署的一样,可以这样查看模型名称
curl http://192.168.10.61:7862/v1/models
得到
{"object":"list","data":[{"id":"/home/hyh/model/Qwen2-7B-Instruct","object":"model","created":1719304526,"owned_by":"vllm","root":"/home/hyh/model/Qwen2-7B-Instruct","parent":null,"max_model_len":32768,"permission":[{"id":"modelperm-e7626cd8a3fb40e08b6e352694485372","object":"model_permission","created":1719304526,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]}]}
"messages"就和正常情况的一样,"stream"必须为True
import requests
url = "http://192.168.10.61:7862/v1/chat/completions"
headers = {
# "Content-Type": "application/json",
"Authorization": "EMPTY"
}
data = {
"model": "Qwen",
"messages": [{"role": "user", "content": "你是谁"}],
"stream": True
}
response = requests.post(url, headers=headers, json=data, stream=True)
for chunk in response:
if chunk:
chunk = chunk.decode('utf-8',errors='ignore').strip()
print(chunk)
requests效果图
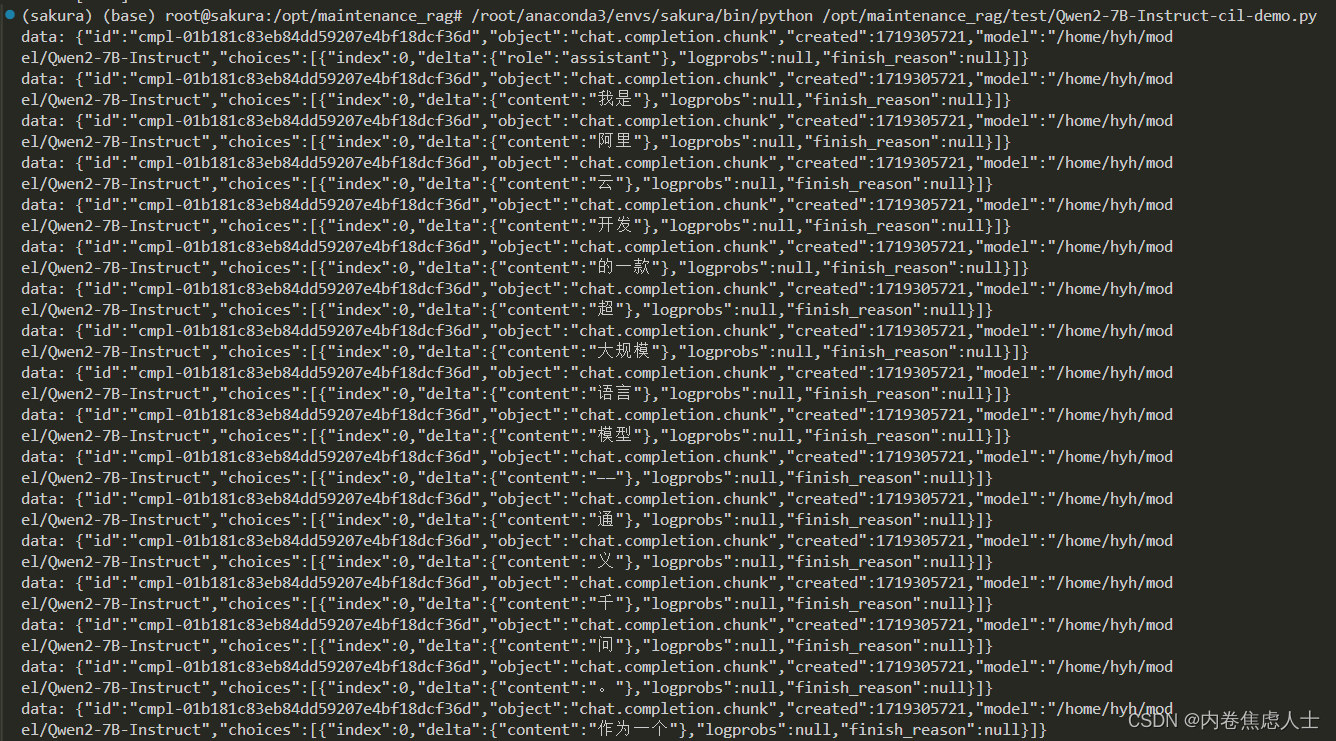
OpenAI请求
from openai import OpenAI
openai_api_base = "http://192.168.10.61:7862/v1"
openai_api_key = "EMPTY"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
response = client.chat.completions.create(
model="Qwen",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "拉矿物油的罐车装植物油,人们食用该食用油后后果是什么?"
"这种“投毒”行为相关责任人却没有被法律审判可见法律法规无用,该企业是政府部门成立的可见加强监管无用,并且该社会问题被隐瞒4年才爆料出来可见社会监督无用,如何有效解决该问题"
},
],
stream=True,
temperature=0,
)
for chunk in response:
content = chunk.choices[0].delta.content
if content:
print(content, end='', flush=True)
print('\n')
OpenAI效果图

关闭日志
如果不关闭,会一直输出一些无关紧要的信息,影响正常查看日志
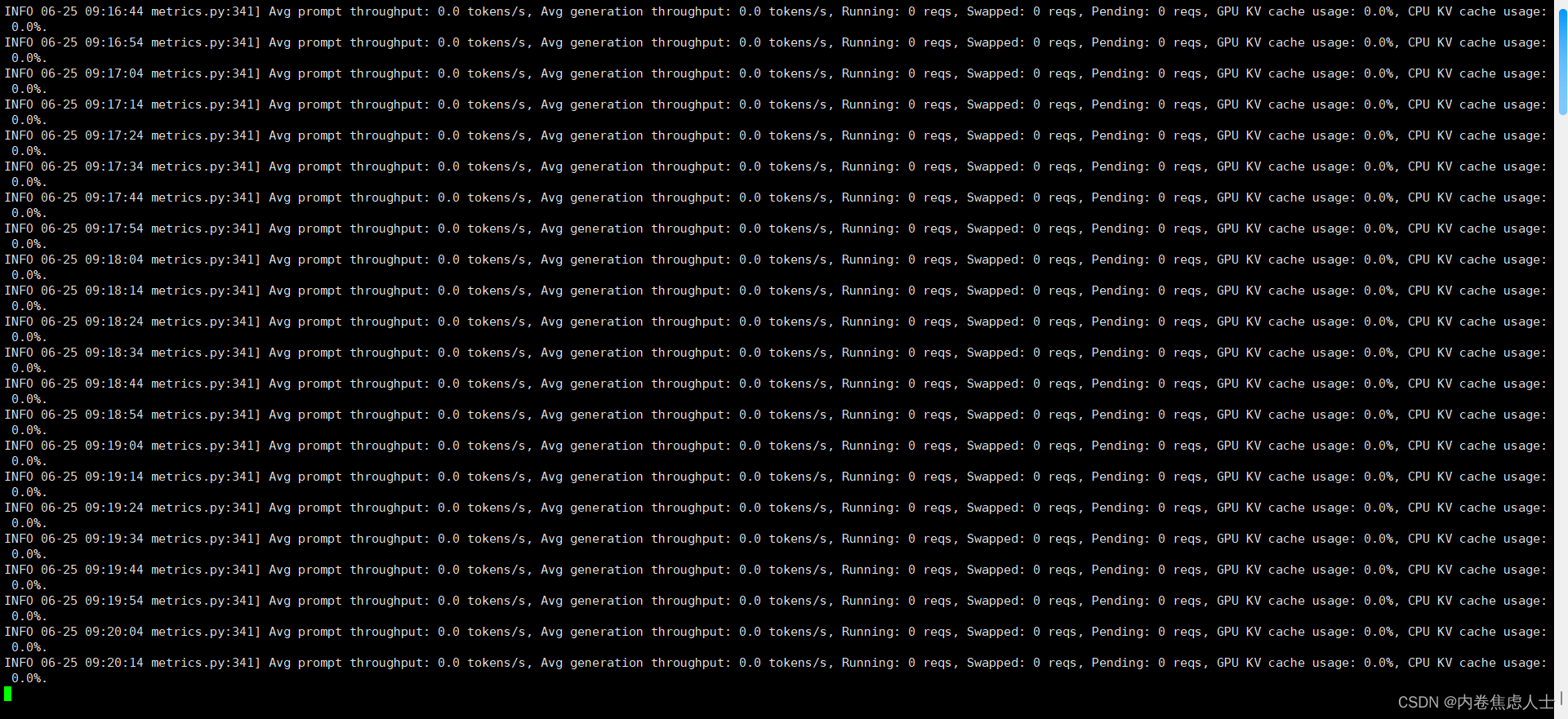
我的虚拟环境名称为sakura
查找你虚拟环境vllm包中一个名为metrics.py的文件
/root/anaconda3/envs/sakura/lib/python3.10/site-packages/vllm/engine/metrics.py
注释掉第341~354行注释
















 931
931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









