







- ROI区域图像叠加
ROI(region of interest):感兴趣区域:利用感兴趣区域ROI实现图像叠加。
1.1 使用cv::Retc
定义一个矩形区域。指定矩形左上角坐标和矩阵的长宽就可以定义一个矩形区域
//定义一个Mat 类型并给其设定ROI区域
Mat imageROI;
//方法一
imageROI = image(Rect(500, 250, log.cols, log.rows));
1.2 使用cv::Range
另一种定义ROI的方式是指定感兴趣区域的行或列的范围。Range是指从起始索引到终止索引(不包括)的一连串序列。
Mat imageROI;
imageROI = image(Range(250, 250 + log.rows), Range(200, 200 + log.cols));
1.3 实例:如何将一幅图像加到另一幅图的指定位置
函数名:ROI_AddImage()
描述:利用感兴趣区域实现图像的叠加
bool ROI_AddImge()
{
//[1]载入图像
Mat srcImage1 = imread("../1.jpg");
Mat logImage2 = imread("../2.jpg");
if(!srcImage1.data) {
printf("读取srcImage1 false!");
return false;
}
if(!logImage2.data) {
printf("读取logImage2 false!");
return false;
}
//[2]定义一个Mat类型,并设定ROI区域
Mat imageROI = srcImage1(Rect(0, 0, logImage2.cols, logImage2.rows));
//[3]加载掩模(必需是灰度图)
Mat mask = imread("../2.jpg", 0);
//[4]将掩模复制到ROI
logImage2.copyTo(imageROI, mask);
//[5]显示结果
namedWindow("<1>利用ROI实现图像的叠加显示窗口");
imshow("<1>利用ROI实现图像叠加显示窗口", srcImage1);
return true;
}
这个函数首先载入了两张图片到srcImage和logImage中,然后定义也Mat类型的imageROI,并在srcImage中设定一块矩形的感兴趣区域,将imageROI和srcImage关联起来。然后定义了一个Mat类的mask,读入2.jpg,然后把mask中的内容复制到imageROI中,据得到最终的效果。



注意:一定要保证nameWindow()中的窗口字符串要和imshow()中的一致,否则,会多处一个窗口
- 图像混合
2.1 线性混合操作
线性混合操作是一种典型的二元(两个图像)的像素操作,它的理论公式为:
g(x) = (1-a)
f
2
f_2
f2(x) + a
f
1
f_1
f1(x)
我们通过在0~1之间改变alpha的值,来实现两张图片或两段视频产生的时间上的画面的叠加效果,图片间的过渡叠加效果,视频的画面叠加效果——addWeighted
2.2 addWeighted函数
(1), 计算两个数组(图像阵列)的加权和。因为要对两个图像进行加权求和,所以图像尺寸一定要相同。
原型:
void addWeighted(InputArray src1, double alpha, InputArray src2, double beta, double gamma, OutputArray dst, int dtype = -1);
参数:
- 参数一:InputArray src1, 表示加权的第一个数组, InputArray相当于Mat.
- 参数二:alpha,第一个数组的权重。
- 参数三:src2,第二个数组,它需要和第一个数组有相同的尺寸和通道数字(颜色)。
- 参数四:beta,表示第二个数组的权重值。
- 参数五:dst, 输出的数组,和输入的两个数组有相同的尺寸和通道数。
- 参数六:gamma,一个加权到权重总和上的标量值。
- 参数七:dtype, 输出阵列的可选深度,默认-1.当两个输入数组具有相同的深度时,等同于src1.depth()
dst = src1[I] * alpha + src2[I] * beta + gamma;
其中I是多维数组元素的索引值。遇到多通道时,每个通道都需要单独处理。当输出数组的深度为CV_32S时,这个函数就不适用了,内存会益处或值不对。
2.3 代码实例
函数名:LinearBlending()
描述:图像混合加权操作,叠加效果图
bool LinearBlending()
{
//[0]定义一些局部变量
double alphaValue = 0.5;
double betaValue;
Mat srcImage2, srcImage3, dstImage;
//[1]读取图片(两幅图同尺度和类型)
Mat srcImage2 = imread("../3.jpg");
Mat srcImage3 = imread("../4.jpg");
if(!srcImage2.data) {
cout <<"读取srcImage2 错误!" << endl;
return false;
}
if(!srcImage3.data) {
cout << "读取srcImage3 错误!" << endl;
return false;
}
//[3]作图像混合加权操作
betaValue = (1.0 - alphaValue);
addWeighted(srcImage2, alphaValue, srcImage3, betaValue, 0.0, dstImage);
//[3]创建并显示原窗口
namedWindow("<2>线性混合窗口原图>", 1);
imshow("<2>线性混合窗口原图【窗口】", srcImage2);
namedWindow("<2>线性混合窗口【效果图】");
imshow("<2>线性混合窗口【效果图】", dstImage);
return true;
}



3.初级图像混合
3.1 将感兴趣区域和addWeightd进行结合。
先指定ROI区域,然后用addWeighted函数对指定的ROI区域的图像进行混合操作。
函数名:ROI_LinearBlending()
描述:线性混合实现函数,指定区域线性图像混合;
bool ROI_LiearBlending()
{
//[1]读取图像
Mat srcImage4 = imread("../1.jpg", 1);
Mat logsrcImage = imread("../2.jpg");
if(!srcImage4.data) {
cout <<"读取srcImage2 错误!" << endl;
return false;
}
if(!logsrcImage.data) {
cout << "读取srcImage3 错误!" << endl;
return false;
}
//[2]定义一个Mat类的ROI,并设定区域
Mat imageROI;
//方法一
imageROI = srcImage4(Rect(0, 0 , logsrcImage.cols, logsrcImage.rows));
//方法二
imageROI = srcImage4(Range(250, 250 + logsrcImage.rows), Range(200, 200 + logsrcImage.cols));
//[3]将logo加到原图上
addWeighted(imageROI, 0.5, logsrcImage, 0.3, 0.0, imageROI);
//[4]显示结果
namedWindow("<4>区域线性混合图实例");
imshow("<4>区域线性混合实例图", srcImage4);
return 0;
}

4 综合实例
#include "opencv2/opencv.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/highgui/highgui.hpp"
#include <iostream>
using namespace std;
using namespace cv;
bool ROI_AddImage();
bool LinearBlending();
bool ROI_LiearBlending();
int main()
{
system("color SE");
if(ROI_AddImage() && LinearBlending() && ROI_LiearBlending()) {
cout << "运行成功!" << endl;
}
waitKey(0);
return 0;
}
bool ROI_AddImge()
{
//[1]载入图像
Mat srcImage1 = imread("../1.jpg");
Mat logImage2 = imread("../2.jpg");
if(!srcImage1.data) {
printf("读取srcImage1 false!");
return false;
}
if(!logImage2.data) {
printf("读取logImage2 false!");
return false;
}
//[2]定义一个Mat类型,并设定ROI区域
Mat imageROI = srcImage1(Rect(0, 0, logImage2.cols, logImage2.rows));
//[3]加载掩模(必需是灰度图)
Mat mask = imread("../2.jpg", 0);
//[4]将掩模复制到ROI
logImage2.copyTo(imageROI, mask);
//[5]显示结果
namedWindow("<1>利用ROI实现图像的叠加显示窗口");
imshow("<1> 利用ROI实现图像叠加显示窗口", srcImage1);
return true;
}
bool LinearBlending()
{
//[0]定义一些局部变量
double alphaValue = 0.5;
double betaValue;
Mat srcImage2, srcImage3, dstImage;
//[1]读取图片(两幅图同尺度和类型)
Mat srcImage2 = imread("../3.jpg");
Mat srcImage3 = imread("../4.jpg");
if(!srcImage2.data) {
cout <<"读取srcImage2 错误!" << endl;
return false;
}
if(!srcImage3.data) {
cout << "读取srcImage3 错误!" << endl;
return false;
}
//[3]作图像混合加权操作
betaValue = (1.0 - alphaValue);
addWeighted(srcImage2, alphaValue, srcImage3, betaValue, 0.0, dstImage);
//[3]创建并显示原窗口
namedWindow("<2>线性混合窗口原图>", 1);
imshow("<2>线性混合窗口原图【窗口】", srcImage2);
namedWindow("<2>线性混合窗口【效果图】");
imshow("<2>线性混合窗口【效果图】", dstImage);
return true;
}
bool ROI_LiearBlending()
{
//[1]读取图像
Mat srcImage4 = imread("../1.jpg", 1);
Mat logsrcImage = imread("../2.jpg");
if(!srcImage4.data) {
cout <<"读取srcImage2 错误!" << endl;
return false;
}
if(!logsrcImage.data) {
cout << "读取srcImage3 错误!" << endl;
return false;
}
//[2]定义一个Mat类的ROI,并设定区域
Mat imageROI;
//方法一
imageROI = srcImage4(Rect(0, 0 , logsrcImage.cols, logsrcImage.rows));
//方法二
imageROI = srcImage4(Range(250, 250 + logsrcImage.rows), Range(200, 200 + logsrcImage.cols));
//[3]将logo加到原图上
addWeighted(imageROI, 0.5, logsrcImage, 0.3, 0.0, imageROI);
//[4]显示结果
namedWindow("<4>区域线性混合图实例");
imshow("<4>区域线性混合实例图", srcImage4);
return 0;
}
CMakeLists.txt:
cmake_minimum_required(VERSION 3.6)
project(ROI)
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
add_executable(ROI ROI.cpp)
target_link_libraries(ROI ${OpenCV_LIBS})
实现效果是上述分装好的三个函数运行后的结果。
- 访问图像中的像素
5.1 图像在内存中的存储方式
图像矩阵的大小取决于所用的颜色模型,即所用的通道数。
如果是灰度图,则列数就是通道数,一一对应。
如果是彩色图,那就是多通道的,矩阵中的列会包含多个子列,子列个数与通道数相同。
opencv中列的通道数是反过来的,不是RGB而是BGR,很多情况下,由于内存空间足够大,可以实现连续存储,因此,图像个行能连续存储,形成一个长行。连续存储能提升图像扫描的速度,可以通过使用isContinuous()来判断矩阵是否连续存储的。
5.2 颜色空间缩减
矩阵的单通道像素值由无符号字符类表示,就是256个不同的值,多通道的更多,如此多的颜色处理起来,会影响算法的性能。
使用这些颜色中有代表性的就可以达到同样的效果。
颜色空间缩减:将现有的颜色值除以某个值,以获得较少的颜色数。如0-9可以取为0, 10-19可以取为10;
这样的缩减操作将三通道的颜色降低到26 x 26 x26种。
在C++中int类型除法会自动截余。
I
n
e
w
I_{new}
Inew=
I
o
l
d
10
∗
10
\frac {I_{old}}{10}*10
10Iold∗10
在处理图像的过程中,对每个像素进行上述操作,也需要花时间。只有0~255中情况。进一步把256种计算好的结果存到table中,这样每种情况不用计算,直接取值。
int divideWith = 10;
uchar table[256];
for(int i = 0; i < 256; i++) {
table[i] = divideWith * (i/divideWith);
}
于是,table中存放的是值为i的像素减小颜色空间的结果。
颜色空间缩减有两部分组成:
(1)遍历图像矩阵的每个像素;
(2)对像素应用上述公式;
5.3 LUT函数:Look up table操作
通过operationsOnArrays::LUT()的函数来进行。它用于批量进行图像元素的查找,扫描于操作图像。使用方法如下:
首先建立一个Mat 型用于查表
Mat loolUpTable(1, 256, CV_8U);
uchar *p = LookUpTable.data;
for(int i = 0; i < 256; i++)
{
p[i] = table[i];
}
//然后调用函数(I是输入,J是输出)
for(int i = 0; i<times; i++) {
LUT(I, lookUpTable, J);
5.4 记时函数
getTickCount() , getTickFrequency()
- getTickCount()返回CPU自某个事件以来时钟周期数;
- getTickFrequency()函数返回CPU一秒走的时钟周期数。
使用方法:
double time0 = static_cast<double>(getTickCount));
//进行一些列图像操作
time 1 = ((double)getTickCount() - time0)/getFrequency();
cout << "操作运行的时间为:" << time0 << "秒“ << endl;
5.5 访问图像中像素的三种方法
OpenCV提供了三种访问每个像素的方法;
- 方法一:指针访问:c擦作符[];
- 方法二:迭代器iterator;
- 方法三:动态地址计算;
这三种访问的方式在bebug模式下访问速度略有差别,release下差不多。
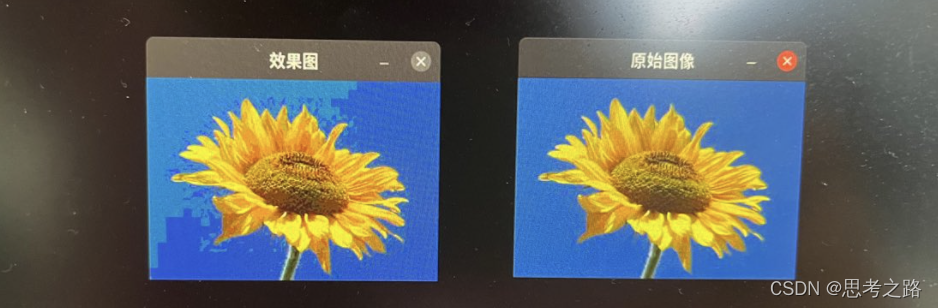
程序的目的是减少图像中颜色的数量。
主程序:
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <iostream>
using namespace std;
using namespace cv;
void colorReduce(Mat& inputImage, Mat& outputImage, int div);
int main()
{
//[1]创建原始图像并显示
Mat srcImage = imread("../1.jpg");
imshow("原始图像", srcImage);
//[2]按原始图像的参数规格来创建效果图
Mat dstImage;
dstImage.create(srcImage.rows, srcImage.cols, srcImage.type());
//[3]记录时间
double time0 = static_cast<double>(getTickCount());
//[4]调用颜色空间缩减函数
colorReduce(srcImage, dstImage, 32);
//[5]计算运行时间并输出
time0 = ((double)getTickCount() - time0)/getTickFrequency();
cout << "此方法运行时间:" << time0 << "秒" << endl;
//[6]显示效果图
imshow("效果图", dstImage);
waitKey(0);
return 0;
}
从上述代码可以看出,主程序中调用了colorReduce()函数来完成减少颜色的的工作,而我们访问像素有三种方法,所以有三个版本的colorReduce()
- 方法一:用指针访问像素
void colorReduce(Mat& inputImage, Mat& outputImage, int div)
{
outputImage = inputImage.clone(); // 复制实参到临时变量
int rowNumber = outputImage.rows;
int colorNumber = outputImage.cols * outputImage.channels(); //列x的通道数等于每一行元素的个数
for(int i = 0; i < rowNumber; i++) {
uchar* data = outputImage.ptr<uchar>(i); //获取第i行的首地址
for(int j = 0; j<colNumber; j++) {
//开始处理每个像素
data[j] = data[j]/div * div +div/2;
//*data ++= *data/div * div + div/2; //使用指针运算从一列移动到下一列
//处理结束
}
}
}

- 方法二:迭代器操作像素
在迭代法中,我们需要做的就是获取图像矩阵的begin和end,然后增加迭代直至从begin到end。将*操作符加到指针的前面,可以访问当前指针所指的内容。
void colorReduce(Mat& inputImage, Mat& outputImage, int div)
{
outputImage = inputImage.clone();
//获取迭代器
Mat_<Vec3b>::iterator it = outputImage.begin<Vec3b>(); //初始位置的迭代器
Mat_<Vec3b>::iterator itend = outputImage.end<Vec3b>(); //终止
//存取彩色图像 像素
for(; it!= itend; ++it) {
(*it)[0] = (*it)[0]/div * div + div/2;
(*it)[1] = (*it)[1]/div * div + div/2;
(*it)[2] = (*it)[2]/div * div + div/2;
}
}

- 方法三:动态地址计算
用动态地址计算来操作像素,配合at方法。
void colorReduce(Mat& inputImage, Mat& outputImage, int div)
{
outputImage = inputImage.clone();
int rowNumber = outputImage.rows;
int colNumber = outputImage.cols;
//存取彩色图像像素
for(int i = 0; i < rowNumber; i++) {
for(int j = 0; j < colNumber; j++) {
//开始处理每个像素
outputImage.at<Vec3b>(i, j)[0] = outputImage.at<Vec3b>(i, j)[0] /div * div + div/2; // 蓝色通道
outputImage.at<Vec3b>(i,j)[1] = outputImage.at<Vec3b>(i, j)[1] / div * div + div/2; //绿色
outputImage.at<Vec3b>(i,j)[2] = outputImage.at<Vec3b>(i, j)[2] / div * div + div/2; //红色
//处理结束
}
}
}

讲解上述代码:
成员函数at(int y, int x)可以用来存取图像元素,但必须在编译时知道图像的数据类型。我们一定要确保指定的数据类型和矩阵中的数据类型符合。因为at方法本身不会对任何数据类型进行转换。
对彩色图像,像素由三个部分组成:蓝通道,绿通道,红通道(BGR)。因此对于一个包含彩色图像的Mat,会返回一个由三个8位数组成的向量。 类型为Vec3b,即由三个unsigned char 组成的向量。
形式:image.at(j, i)[channel] = value; channel表明了颜色通道号;














 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









