










地质灾害是指全球地壳自然地质演化过程中,由于地球内动力、外动力或者人为地质动力作用下导致的自然地质和人类的自然灾害突发事件。由于降水、地震等自然作用下,地质灾害在世界范围内频繁发生。我国除滑坡灾害外,还包括崩塌、泥石流、地面沉降等各种地质灾害,具有类型多样、分布广泛、危害性大的特点。地质灾害危险性评价着重于根据多种影响因素和区域选择来评估在某个区域中某个阶段发生的地质灾害程度。以此预测和分析未来某个地形单位发生地质灾害的可能性。根据地质灾害的孕育和发展机理,现有的数据资料和技术,以及实际应用需要,评价目标和研究经费等因素,采用适当的方法,可通过模型评估并分析研究区域对地质灾害的危险性。那么如何深刻理解地灾危险性评价模型?如何高效处理好致灾因子数据?如何针对具体区域建立切实可行的地质灾害危险性评价与灾后重建方案?本课程将提供一套基于ArcGIS的方法和案例。
GIS(Geographical Information System)——地理信息系统,是集地理、测绘、遥感和信息技术为一体,地理空间数据进行获取、管理、存储、显示、分析和模型化,以解决与空间位置有关的分析与管理问题。ArcGIS软件具有空间数据和属性数据的输入、编辑、查询、简单空间分析统计、输出、报表等功能,这为多源数据的有机整合提供了可能,也为建立灵活的分析模块提供了方便。空间分析功能是GIS得以广泛应用的重要原因之一。运用GIS分析技术,对各因素进行统计分析、信息叠加复合,研究地质灾害类型、分布规律级别和灾害损失度等,运用危险性指数等方法对地质灾害危险性现状评价与制图,将能使地质灾害风险评价更加效率化、科学化,为地质灾害数据库建设提供有力支撑。
随着由遥感、地理信息系统和全球定位系统为代表的新型测绘技术的发展,地质灾害数据的质量和数量大幅提升。地质灾害数据具有多源性、时空性和非线性等特点,如何对这些海量数据进行准确且可靠的分析尤为重要。从当前的发展趋势来看,使用机器学习模型已经成为滑坡易发性区划的主流;深度学习作为当前人工智能领域的研究热点,能够从给定样本空间中学习到各种复杂的拟合函数,在广泛受到关注。
将结合项目实践案例和科研论文成果进行讲解。入门篇,ArcGIS软件的快速入门与GIS数据源的获取与理解;方法篇,致灾因子提取方法、灾害危险性因子分析指标体系的建立方法和灾害危险性评价模型构建方法;拓展篇,GIS在灾害重建中的应用方法;高阶篇:Python环境中利用机器学习进行灾害易发性评价模型的建立与优化方法。
您将进一步理解地质灾害形成机理与成灾模式;从空间数据处理、信息化指标空间数据库构建、致灾因子提取,空间分析、危险性评价与制图分析等方面掌握GIS在灾害危险性评价中的方法;在具体实践案例中,学会运用地质灾害危险性评价原理和技术方法,同时学会GIS在灾后重建规划等领域的应用方法,提升GIS技术的应用能力水平;从科研论文成果复现中学会论文撰写的技巧,学会基于机器学习进行滑坡易发性评价与精度评估;本课程方案将为滑坡的防灾减灾提供重要的理论依据。
基本概念
1、基本概念
地质灾害类型
地质灾害发育特征与分布规律
地质灾害危害特征
地质灾害孕灾地质条件分析
地质灾害诱发因素与形成机理
GIS原理与ArcGIS平台介绍
lGIS简介
lArcGIS基础
l空间数据采集与组织
l空间参考
l空间数据的转换与处理
lArcGIS中的数据编辑
l地理数据的可视化表达
l空间分析:
数字地形分析
叠置分析
距离制图
密度制图
统计分析
重分类
三维分析
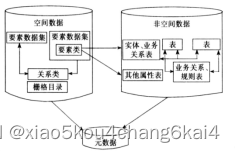
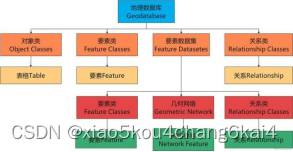
空间信息数据库建设
空间数据库建立及应用
1)地质灾害风险调查评价成果信息化技术相关要求解读
2)数学基础设计
比例尺;坐标系类型:地理坐标系,投影坐标系;椭球参数;投影类型;坐标单位;投影带类型等。
3)数据库内容及要素分层
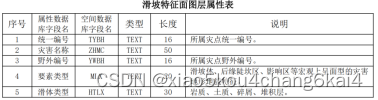
图层划分原则;图层划分及命名;图层内部属性表
4)数据库建立及入库
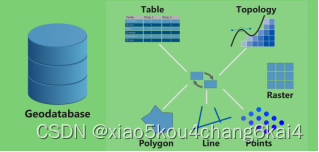
创建数据库、要素集、要素类、栅格数据和关系表等。
矢量数据(shp文件)入库
Table表入库:将崩塌、滑坡、泥石流等表的属性数据与灾害点图层关联。
栅格数据入库
栅格数据集入库:遥感影像数据、DEM、坡度图、坡向图、降雨量等值线图以及其他经过空间分析得到的各种栅格图像入库。
5)数据质量控制
利用Topology工具检查点线面及其之间的拓扑关系并修改;图属一致性检查与修改。

地质灾害风险评价模型与方法
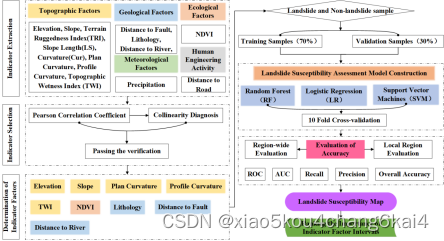
1、地质灾害易发性评价模型与方法
评价单元确定
易发性评价指标体系
易发性评价模型
权重的确定
2、滑坡易发性评价
l 评价指标体系
地形:高程、坡度、沟壑密度、地势起伏度等。
地貌:地貌单元、微地貌形态、总体地势等。
地层岩性:岩性特征、岩层厚度、岩石成因类型等
地质构造:断层、褶皱、节理裂隙等。
地震:烈度、动峰值加速度、历史地震活动情况等
工程地质:区域地壳稳定性,基岩埋深,主要持力层岩性、承载力、岩土体工程地质分区等。
l 常用指标提取
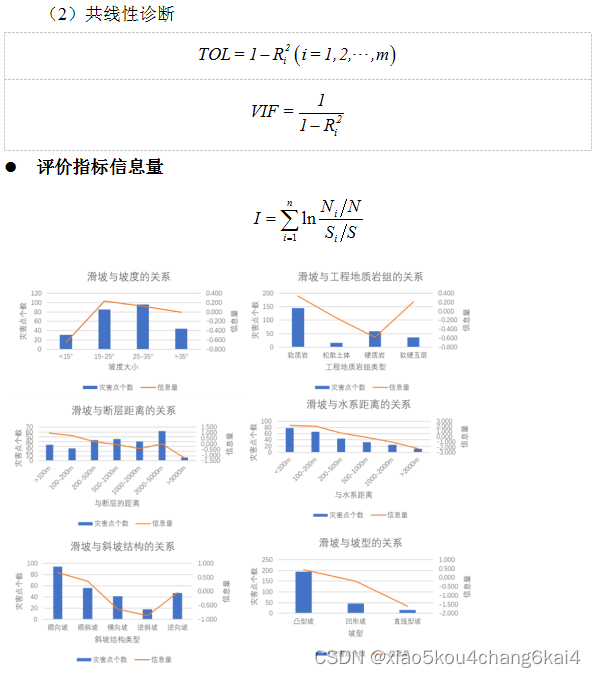
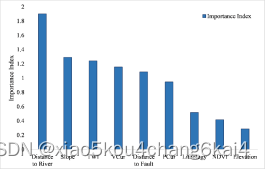
坡度、坡型、高程、地形起伏度、断裂带距离、工程地质岩组、斜坡结构、植被覆盖度、与水系距离等因子提取
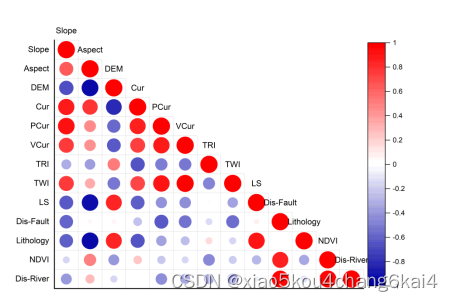
指标因子相关性分析
(1)相关性系数计算与分析
评价指标权重确定
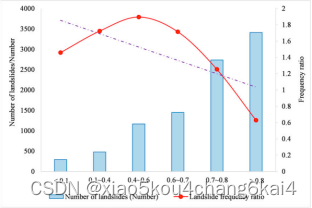
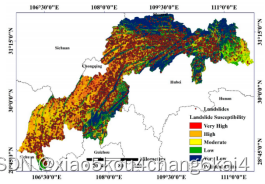
滑坡易发性评价结果分析与制图
滑坡易发性综合指数
易发性等级划分
易发性评价结果制图分析
2、崩塌易发性评价
3、泥石流易发性评价
l泥石流评价单元提取 l水文分析,沟域提取 ü无洼地DEM生成 ü水流方向提取 ü汇流累积量 ü水流长度 ü河网提取 ü流域分割 ü沟壑密度计算 ü模型构建器 ü水文分析工具箱制作
l泥石流评价指标
崩滑严重性、泥沙沿程补给长度比、沟口泥石流堆积活动、沟谷纵坡降、区域构造影响程度、流域植被覆盖度、工程地质岩组、沿沟松散堆积物储量、流域面积、流域相对高差、河沟堵塞程度等
l典型泥石流评价指标选取
评价因子权重确定
泥石流易发性评价结果分析与制图
泥石流易发性综合指数计算
泥石流的易发性分级确定
泥石流易发性评价结果
4、地质灾害易发性综合评价
综合地质灾害易发值=MAX [泥石流灾害易发值,崩塌灾害易发值,滑坡灾害易发值]
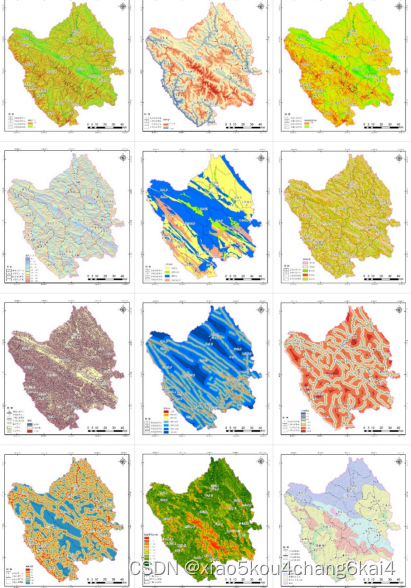
 空间信息数据库
空间信息数据库
 建设
建设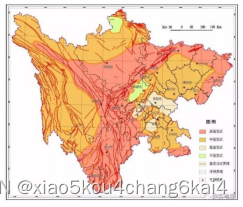
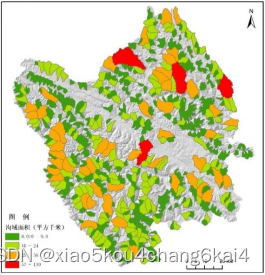
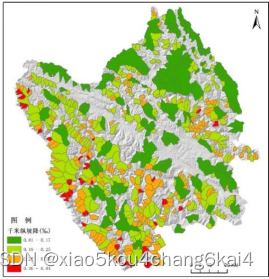
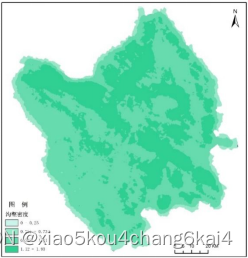
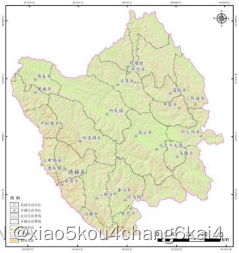
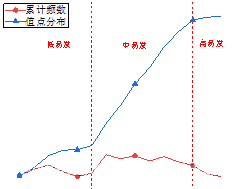
常用数据来源及预处理
1、数据类型介绍
2、点数据获取与处理
l 灾害点统计数据获取与处理 气象站点数据获取与处理
ü 气象站点点位数据处理
ü 气象数据获取
ü 数据整理
ü 探索性分析
ü 数据插值分析
3、矢量数据的获取与处理
l道路、断层、水系等矢量数据的获取
l欧氏距离
l核密度分析
l河网密度分析
4、栅格数据获取与处理
lDEM,遥感影像等栅格数据获取
l影像拼接、裁剪、掩膜等处理
lNoData值处理
l如何统一行列号
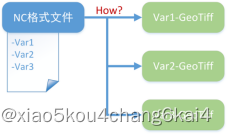
5、NC数据获取与处理
lNC数据简介
lNC数据获取
l模型构建器
lNC数据如何转TIF?
1、遥感云计算平台数据获取与处理
l 遥感云平台数据简介
l如何从云平台获取数据?
l 数据上传与下载
l 基本函数简介
l 植被指数提取
土地利用数据获取
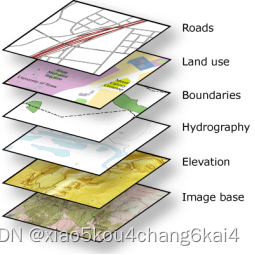
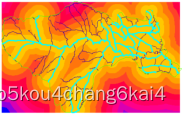
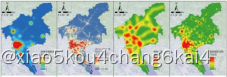
GIS在灾后重建中的应用实践
1、土方纵坡分析
- 由等高线产生不规则三角网
- 计算工程填挖方
- 利用二维线要素纵剖面
- 临时生成剖纵面线
2、应急救援路径规划分析
- 表面分析、成本权重距离、栅格数据距离制图等空间分析;
- 利用专题地图制图基本方法,制作四川省茂县地质灾害应急救援路线图,
- 最佳路径的提取与分析
3、灾害恢复重建选址分析
- 确定选址的影响因子
- 确定每种影响因子的权重
- 收集并处理每种影响因子的数据:地形分析、距离制图分析,重分类
- 恢复重建选址分析
4、震后生态环境变化分析
使用该类软件强大的数据采集、数据处理、数据存储与管理、空间查询与空间分析、可视化等功能进行生态环境变化评价。
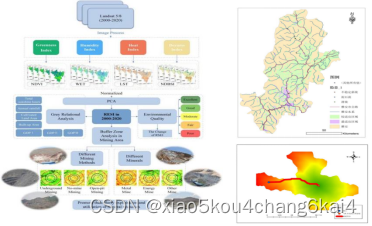
基于机器学习的滑坡易发性分析
1、Python编译环境配置
l Python自带编辑器IDLE使用
l Anaconda集成环境安装及使用
l PyCharm环境安装及使用

2、Python数据清洗
l Python库简介与安装
l 读取数据
l 统一行列数
l 缺失值处理
l 相关性分析/共线性分析
l 主成分分析法(PCA)降维
l 数据标准化
l 生成特征集

相关概念:
- 训练前是否有必要对特征归一化
- 为什么要处理缺失值(Nan值)
- 输入的特征间相关性过高会有什么影响
- 什么是训练集、测试集和验证集;为什么要如此划分
- 超参数是什么
- 什么是过拟合,如何避免这种现象
模型介绍:
- 逻辑回归模型
- 随机森林模型
- 支持向量机模型
实现方案:
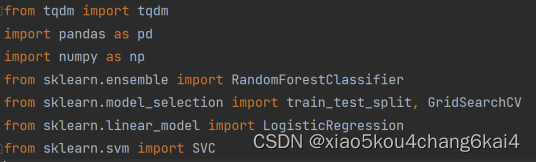
一、线性概率模型——逻辑回归
- 介绍
- 连接函数的选取:Sigmoid函数
- 致灾因子数据集:数据介绍;相关性分析;逻辑回归模型预测;样本精度分析;分类混淆矩阵
- 注意事项
二、SVM支持向量机
- 线性分类器
- SVM-核方法:核方法介绍;sklearn的SVM核方法
- 参量优化与调整
- SVM数据集:支持向量机模型预测;样本精度分析;分类混淆矩阵
三、Random Forest的Python实现
- 数据集
- 数据的随机选取
- 待选特征的随机选取
- 相关概念解释
- 参量优化与调整:随机森林决策树深度调参;CV交叉验证定义;混淆矩阵;样本精度分析
- 基于pandas和scikit-learn实现Random Forest:数据介绍;随机森林模型预测;样本精度分析;分类混淆矩阵
四、XGBoost(Extreme Gradient Boosting)
XGBoost 是一种基于决策树的梯度提升算法。它通过连续地训练决策树模型来最小化损失函数,从而逐步提升模型性能
- 数据划分:
将数据集划分为训练集和测试集,采用随机划分或按时间序列划分的方法。
- 特征工程
对数据进行特征工程,包括特征缩放、特征变换、特征组合等。
- 构建模型
选择合适的模型参数,如树的数量、树的深度、学习率等。
- 模型优化:
通过交叉验证来调整模型参数,以提高模型的泛化能力。
- 模型训练
使用训练集对 XGBoost 模型进行训练。
通过迭代优化损失函数来提高模型性能。
- 模型评估
使用测试集对训练好的模型进行评估。
使用一些常见的评估指标,如准确率、召回率、F1 分数等。
绘制 ROC 曲线或者计算 AUC 值来评估模型的性能。
- 结果解释与应用:
对模型的预测结果进行解释,分析模型的重要特征和决策规则。
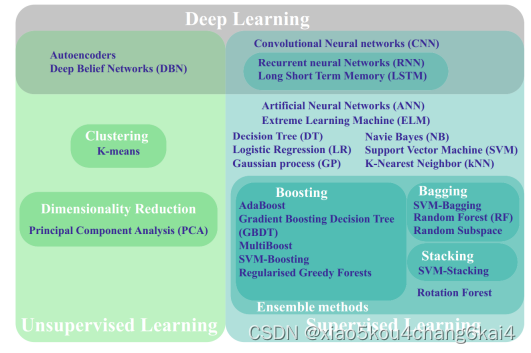
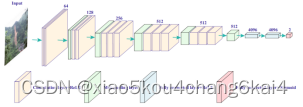
五、神经网络模型
- TensorFlow主要架构
- 神经网络:ANN\CNN\RNN
- 导入数据集
- 分割数据集
- 定义网络架构
- 调用tf.keras.models.Sequential()或tf.keras.layers.Layer()创建模型
- Sequential: 将多个网络层封装,按顺序堆叠神经网络层
- Dense: 全连接层
- activation: 激活函数决定神经元是否应该被激活
- 编译模型
- 通过compile 函数指定网络使用的优化器对象、 损失函数类型, 评价指标等设定
- 优化器(optimizer):运行梯度下降的组件
- 损失(loss):优化的指标
- 评估指标(metrics):在训练过程进行评估的附加评估函数,以进一步查看有关模型性能
- 训练模型
- 通过 fit()函数送入待训练的数据集和验证用的数据集,返回训练过程中的损失值和指定的度量指标的变化情况,用于后续的可视化和模型性能评估。
- 循环迭代数据集多个 Epoch,每次按批产生训练数据、 前向计算,然后通过损失函数计算误差值,并反向传播自动计算梯度、 更新网络参数
- 评估模型
- Model.evaluate()测试模型的性能指标
- 模型预测
- Model.predict(x)方法即可完成模型的预测
- 参数优化
六、集成学习方法
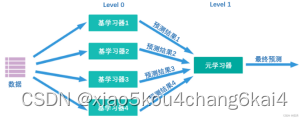
stacking集成算法
ü 准备数据集:
² 将数据集分为训练集和测试集。
ü 创建基本模型:
² 选择多个不同类型的基本模型,如决策树、随机森林、支持向量机、神经网络等。
ü 使用训练集对每个基本模型进行训练
ü 生成基本模型的预测结果
ü 使用训练集对每个基本模型进行预测
² 对于分类问题,每个模型都会生成一个概率矩阵,每一列代表一个类别的预测概率;对于回归问题,每个模型会生成一个预测值向量。
ü 构建元模型:
² 将基本模型的预测结果作为新的特征,构建一个元模型。
² 元模型可以是任何机器学习模型,通常选择简单的模型如逻辑回归、线性回归或者简单的决策树。
ü 使用元模型进行预测
² 将测试集输入到每个基本模型中,得到预测结果。
² 将基本模型的预测结果输入到元模型中进行最终的预测。
Blending融合
ü 准备数据集:
训练集
验证集
测试集
ü 创建基本模型:
选择多个不同类型的基本模型,如决策树、随机森林、支持向量机、神经网络等。
使用训练集对每个基本模型进行训练。
ü 生成基本模型的预测结果:
使用训练集对每个基本模型进行预测。
对于分类问题,每个模型会生成一个概率矩阵,每一列代表一个类别的预测概率;
对于回归问题,每个模型会生成一个预测值向量。
ü 创建元模型:
将基本模型的预测结果作为输入特征,结合验证集的真实标签,训练一个元模型。
元模型可以是任何机器学习模型
ü 使用元模型进行预测:
将测试集输入到每个基本模型中,得到它们的预测结果。
将这些基本模型的预测结果作为输入,输入到元模型中进行最终的预测。
四、方法比较分析
ü 模型性能评估:K 折交叉验证的方法
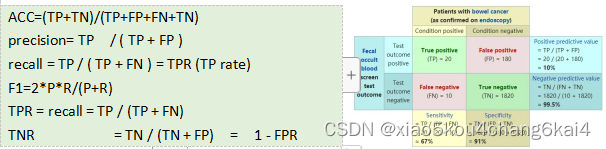
ü 精度分析:accuracy;precision;recall;F1-score,AUC
ü 结果对比分析



论文写作分析
1、论文写作要点分析
2、论文投稿技巧分析
3、论文案例分析


















 1861
1861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









