






第四课:无监督学习
在这一课中,我们将探讨无监督学习,这是机器学习的另一大类别,涉及的算法能够从未标记的数据中学习模式和结构。与监督学习不同,无监督学习不依赖于预先标记的输出,而是试图直接从数据的特征中发现信息。这一课将涵盖聚类、维度缩减等常见的无监督学习任务,以及它们的应用。
4.1 聚类
聚类是无监督学习中最常见的任务之一,旨在将数据集分成由相似对象组成的多个组或“簇”。
-
K-均值(K-Means):这是最著名的聚类算法,通过迭代寻找聚类中心,以最小化每个点到其聚类中心的距离平方和。
-
层次聚类(Hierarchical Clustering):通过创建聚类的层次化树形结构来组织数据,可以是自顶向下或自底向上的方法。
-
DBSCAN(Density-Based Spatial Clustering of Applications with Noise):基于密度的聚类方法,能够识别任意形状的簇,并且对噪声点具有良好的鲁棒性。
4.2 维度缩减
维度缩减是另一个重要的无监督学习任务,目的是减少数据集中的特征数量,同时尽可能保留重要的信息。
-
主成分分析(PCA):通过找到数据中的主要成分并减少维度来简化数据,常用于数据可视化、噪声过滤、特征提取和特征工程。
-
t-分布随机邻域嵌入(t-SNE):一种用于高维数据可视化的技术,通过将高维空间中的数据点转换到低维空间,同时尽可能保持原始数据点之间的相对距离。
-
自组织映射(SOM):一种人工神经网络,用于将高维数据映射到低维(通常是二维)空间,同时保持数据的拓扑结构。
4.3 关联规则学习
关联规则学习是一种用于发现大数据集中变量间有趣关系的方法,常用于市场篮分析、库存管理等领域。
-
Apriori:通过连接步骤和剪枝步骤来发现频繁项集,然后从这些项集中生成关联规则。
-
FP-Growth:比Apriori更高效的算法,使用FP树结构来压缩数据集,并从中发现频繁项集,不需要产生候选项集。
实战示例:使用 K-均值聚类
让我们通过一个简单的示例,使用 K-均值算法对数据进行聚类:
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
# 生成一些随机数据
X = np.random.rand(100, 2)
# 创建 KMeans 实例,设置聚类数为 3
kmeans = KMeans(n_clusters=3, random_state=42)
# 拟合模型
kmeans.fit(X)
# 预测聚类标签
labels = kmeans.predict(X)
# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.show()
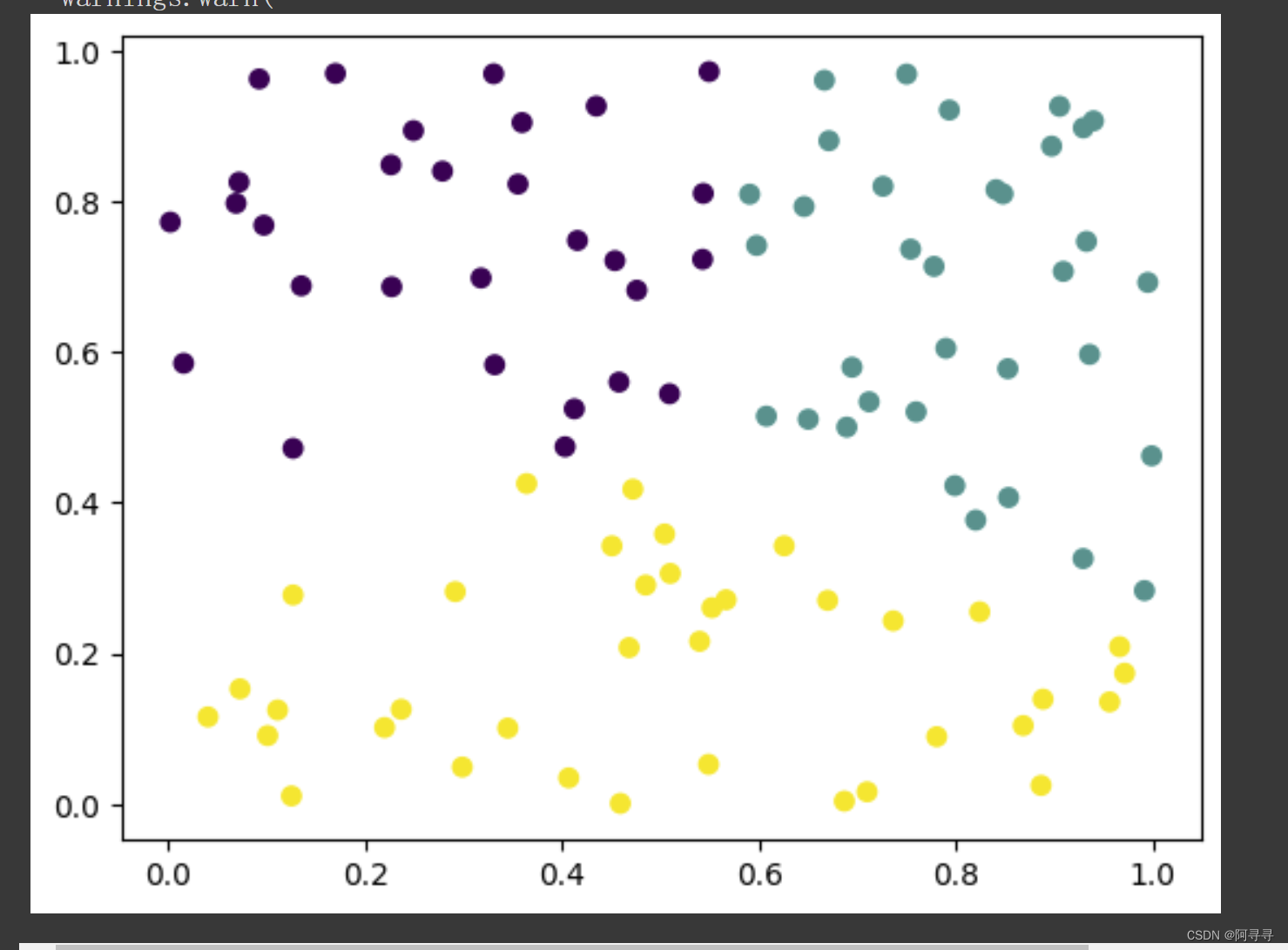
在这个示例中,我们使用了 K-均值算法对一组随机生成的二维数据进行聚类。K-均值是一种非常流行的聚类算法,用于将数据分成预定数量的簇。下面继续第四课的内容。
实战示例:使用 K-均值聚类(续)
在上述代码示例中,我们首先生成了一个包含 100 个二维点的随机数据集。然后,我们创建了一个 KMeans 实例,指定我们想要将数据分成的聚类数量(n_clusters=3),并设置了随机状态以确保结果的可重复性。
使用 fit 方法,我们让 K-均值算法在数据上运行,找到最佳的聚类中心。predict 方法用于为每个数据点分配一个聚类标签,表示这些点属于哪个聚类。最后,我们使用 Matplotlib 可视化了聚类结果,通过不同的颜色区分不同的聚类。
无监督学习的挑战和注意事项
-
选择合适的算法:不同的无监督学习任务和数据类型可能需要不同的算法。选择适合特定问题的算法是成功应用无监督学习的关键。
-
确定聚类数量:在聚类任务中,确定最佳聚类数量通常不是显而易见的。需要使用如肘方法(Elbow Method)、轮廓分数(Silhouette Score)等技术来估计最佳聚类数量。
-
数据预处理:无监督学习对数据预处理非常敏感,包括缩放、标准化等步骤。适当的数据预处理可以显著影响模型的性能。
-
结果解释:无监督学习模型的结果可能不像监督学习那样直观。解释和验证这些模型的结果需要领域知识和额外的分析。
-
维度缩减的应用:在处理高维数据时,维度缩减可以帮助去除噪声和冗余,突出重要特征,同时使得数据更易于可视化和分析。
无监督学习是一个强大的工具,可以帮助我们理解和解释数据中的潜在结构和模式。虽然它提出了一些独特的挑战,但通过适当的方法和技术,无监督学习可以揭示出数据中的深刻洞察。
这就是关于无监督学习的介绍。希望这能帮助你理解无监督学习的基本概念和常见算法,以及如何在实际问题中应用这些算法。如果你有任何问题或需要进一步的解释,请随时提问。
















 257
257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











