







课前问题
rnn无法并行,transformer怎么就可以并行了
什么是残差链接
为什么那么多注意力组件
正弦位置编码表如何取代rnn自有的时序
编解码器结构有哪些变化
训练方式以及如何调整超参
不给出完整代码,如果想要作业和答疑课程推荐购买,有一些课还挺好的
知乎看到的一位大佬的讲解
Transformer 架构
总览:
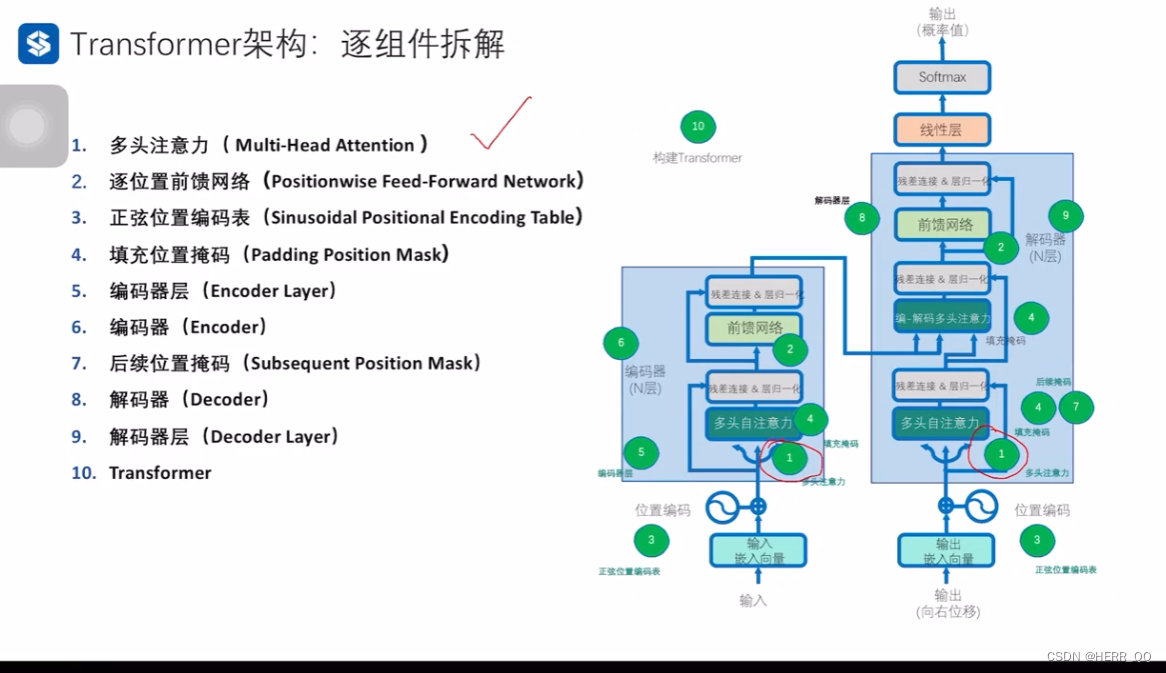
1. 缩放点积自注意力多头注意力
具体内容可以见第六节讲解,
输入通过线性变化(线性层学习)学到qkv变换linear参数,并且得到qkv,然后的到向量点积,之后缩放一下防止激活函数出现梯度消失,之后加入掩码(mask),通过激活函数softmax整理到0-1后再一次和v做点积。见下图:
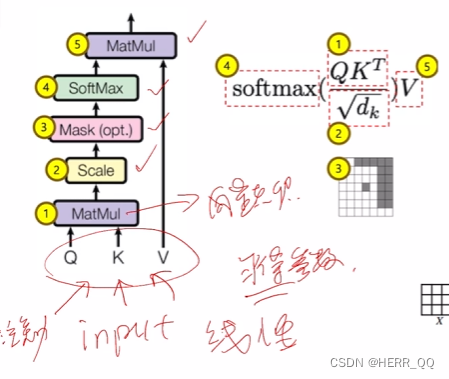
补充一句,这里没有突出显示的是输入向量通过线性层变换变成qkv,如果没有这个线性变换,自注意力机制将无法正常工作。通过反复迭代forward和back propagation过程,从物理意义角度来看权重矩阵逐渐调整到能够捕捉输入数据的有用特征的状态,从数学角度来看线性变换层的参数将朝着减小损失的方向调整。
老师源代码如下:
d_k = 64 # K(=Q)维度
d_v = 64 # V维度
device = "cuda" if torch.cuda.is_available() else "cpu"
# 定义缩放点积注意力类
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
#-------------------------维度信息--------------------------------
# Q K V [batch_size, n_heads, len_q/k/v, dim_q=k/v] (dim_q=dim_k)
# attn_mask [batch_size, n_heads, len_q, len_k]
#-----------------------------------------------------------------
# 计算注意力分数(原始权重)[batch_size,n_heads,len_q,len_k]
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
#-------------------------维度信息--------------------------------
# scores [batch_size, n_heads, len_q, len_k]
#-----------------------------------------------------------------
# 使用注意力掩码,将attn_mask中值为1的位置的权重替换为极小值
#-------------------------维度信息--------------------------------
# attn_mask [batch_size, n_heads, len_q, len_k], 形状和scores相同
#-------------------------维度信息--------------------------------
scores.masked_fill_(attn_mask, -1e9)
# 对注意力分数进行softmax
weights = nn.Softmax(dim=-1)(scores)
#-------------------------维度信息--------------------------------
# weights [batch_size, n_heads, len_q, len_k], 形状和scores相同
#-------------------------维度信息--------------------------------
# 计算上下文向量(也就是注意力的输出), 是上下文信息的紧凑表示
context = torch.matmul(weights, V)
#-------------------------维度信息--------------------------------
# context [batch_size, n_heads, len_q, dim_v]
#-------------------------维度信息--------------------------------
return context, weights # 返回上下文向量和注意力分数
batch_size 是批次大小,n_heads 是注意力头的数量,len_q, len_k, len_v 是查询、键和值的长度,dim_q 和 dim_k 表示查询和键的维度。这通常与 d_k 相等,因为缩放点积注意力需要这种维度一致。
掩码就是通过把比如一些padding的地方,不需要的位置,填充1e-9这样的极小值,然后通过激活函数softmax的特性给0化,填充是masked_fill函数来实现。
attn_mask 是一个与 scores 具有相同形状的二进制掩码矩阵,通常包含0和1的值,scores.masked_fill_(attn_mask, -1e9) 这一行代码将掩码矩阵中值为1的位置的注意力分数替换为极小值(-1e9)
1.2 多头注意力
目的是尝试各种各样的qkv组合
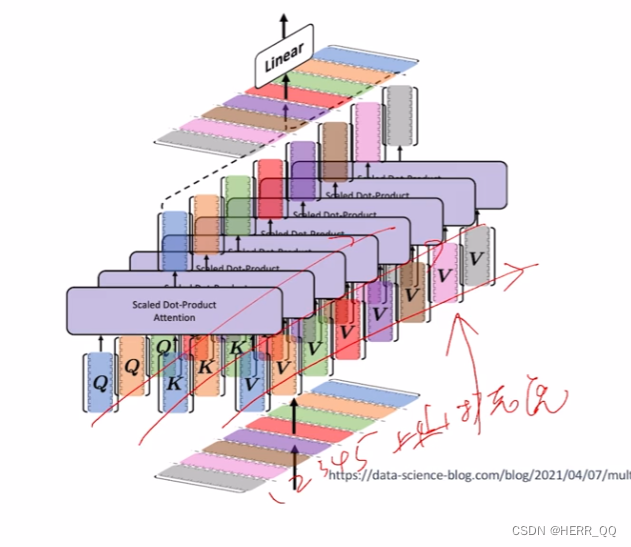
这里是并行处理,同时位置信息没有变化:逐位置。
同时代码里还有残差链接和层归一化代码:
# 定义多头注意力类
d_embedding = 512 # Embedding的维度
n_heads = 8 # Multi-Head Attention中头的个数
batch_size = 3 # 每一批的数据大小
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_embedding, d_k * n_heads) # Q的线性变换层
self.W_K = nn.Linear(d_embedding, d_k * n_heads) # K的线性变换层
self.W_V = nn.Linear(d_embedding, d_v * n_heads) # V的线性变换层
self.linear = nn.Linear(n_heads * d_v, d_embedding)
self.layer_norm = nn.LayerNorm(d_embedding)
def forward(self, Q, K, V, attn_mask):
#-------------------------维度信息--------------------------------
# Q K V [batch_size, len_q/k/v, embedding_dim]
#-------------------------维度信息--------------------------------
residual, batch_size = Q, Q.size(0) # 保留残差连接
# 将输入进行线性变换和重塑,以便后续处理
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2)
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2)
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2)
#-------------------------维度信息--------------------------------
# q_s k_s v_s: [batch_size, n_heads, len_q/k/v, d_q=k/v]
#-------------------------维度信息--------------------------------
# 将注意力掩码复制到多头 attn_mask: [batch_size, n_heads, len_q, len_k]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
#-------------------------维度信息--------------------------------
# attn_mask [batch_size, n_heads, len_q, len_k]
#-------------------------维度信息--------------------------------
# 使用缩放点积注意力计算上下文和注意力权重
# context: [batch_size, n_heads, len_q, dim_v]; weights: [batch_size, n_heads, len_q, len_k]
context, weights = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
#-------------------------维度信息--------------------------------
# context [batch_size, n_heads, len_q, dim_v]
# weights [batch_size, n_heads, len_q, len_k]
#-------------------------维度信息--------------------------------
# 重塑上下文向量并进行线性变换,[batch_size, len_q, n_heads * dim_v]
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v)
#-------------------------维度信息--------------------------------
# context [batch_size, len_q, n_heads * dim_v]
#-------------------------维度信息--------------------------------
output = self.linear(context) # [batch_size, len_q, embedding_dim]
#-------------------------维度信息--------------------------------
# output [batch_size, len_q, embedding_dim]
#-------------------------维度信息--------------------------------
# 与输入(Q)进行残差链接,并进行层归一化后输出[batch_size, len_q, embedding_dim]
output = self.layer_norm(output + residual)
#-------------------------维度信息--------------------------------
# output [batch_size, len_q, embedding_dim]
#-------------------------维度信息--------------------------------
return output, weights # 返回层归一化的输出和注意力权重
以下是借助gpt对两个概念进行了理解
- 残差链接:
残差链接是指将网络的输入直接添加到神经网络的某些层的输出上。设 H(x) 为网络的某一层的输出, F(x) 为该层的输入。残差连接则定义为:Output = H(x) + F(x)
这里的加法操作是逐元素的,即对应位置的元素相加。这种连接方式可以帮助信息在网络中更快地传播,特别是在网络较深时。如果没有残差连接,深层网络可能会遇到梯度消失或梯度爆炸等问题,导致训练困难。残差连接可以缓解这些问题,使得网络更容易训练。
老师的代码中,残差连接被用于保留原始输入 ( Q ),使其与多头注意力的输出相加,以便在网络中传递信息并减缓梯度消失问题。 - 层归一化:
层归一化可以使得每层的输出分布相对稳定,有助于加速训练过程并提高模型的泛化能力。这里层归一化被应用在多头注意力的输出上,以规范化每个注意力头的输出,即每个样本的每个特征进行归一化,使得输出的均值为0,方差为1
这里我觉得概念还有点混淆,于是追问:
Q:归一化这里指的是使一系列的样本的同一个feature总体来看平均值为0方差为1还是同一个样本的不同feature平均值为0方差为1
ANS:层归一化的主要思想是对每个样本的所有特征进行归一化,而不是批量归一化方法中的对所有样本的同一个特征进行归一化。即层归一化是在单个样本上做归一化。
具体来说,在实际计算时,对单个样本,在某一层的所有神经元输出上,让他们的平均值为0,方差为1。也就是对单个样本的所有特征输出进行归一化,而不考虑批次维度。此时,归一化的统计量(均值和方差)是跨特征计算的。
扩展一点: 批量归一化(Batch
Normalization):批量归一化是对每个特征维度在一个小批量(批次)上进行归一化,目的是使同一个特征在一组样本上的均值为0,方差为1。这意味着在每个特征上,统计归一化操作是在一个小批量的所有样本上完成的。
2. 逐位置前向传播网络
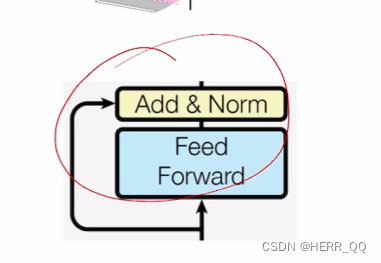
本质上还是多学习了几层,增加表现力,不破坏位置结构,,代码:
# 定义逐位置前向传播网络类
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
# 定义一维卷积层1,用于将输入映射到更高维度
self.conv1 = nn.Conv1d(in_channels=d_embedding, out_channels=2048, kernel_size=1)
# 定义一维卷积层2,用于将输入映射回原始维度
self.conv2 = nn.Conv1d(in_channels=2048, out_channels=d_embedding, kernel_size=1)
# 定义层归一化
self.layer_norm = nn.LayerNorm(d_embedding)
def forward(self, inputs): # inputs: [batch_size, len_q, embedding_dim]
#-------------------------维度信息--------------------------------
# inputs [batch_size, len_q, embedding_dim]
#-------------------------维度信息--------------------------------
residual = inputs # 保留残差连接 [batch_size, len_q, embedding_dim]
# 在卷积层1后使用ReLU激活函数 [batch_size, embedding_dim, len_q]->[batch_size, 2048, len_q]
output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))
#-------------------------维度信息--------------------------------
# output [batch_size, 2048, len_q]
#-------------------------维度信息--------------------------------
# 使用卷积层2进行降维 [batch_size, 2048, len_q]->[batch_size, embedding_dim, len_q]
output = self.conv2(output).transpose(1, 2) # [batch_size, len_q, embedding_dim]
#-------------------------维度信息--------------------------------
# output [batch_size, len_q, embedding_dim]
#-------------------------维度信息--------------------------------
# 与输入进行残差链接,并进行层归一化,[batch_size, len_q, embedding_dim]
output = self.layer_norm(output + residual) # [batch_size, len_q, embedding_dim]
#-------------------------维度信息--------------------------------
# output [batch_size, len_q, embedding_dim]
#-------------------------维度信息--------------------------------
return output # 返回加入残差连接后层归一化的结果
关于卷积,是cnn基础里学到的,这里有一个很好的说明 卷积很好的说明,这里也可以使用线性层
3. 正弦位置编码表
RNN慢,但是位置信息在时序中保留,但是无法并行。如果并行要想办法保留位置信息。
使用一个新的矩阵,保留位置编码与输入矩阵一起发送。
为什么使用正弦而不是用123456…之类的呢呢?自然语言中有很多模式是循环出现的,周期性的函数很棒棒。

老师这里是说,i是维度,d是维度总数。pos是指时序,那么同样的第6个维度在不同位置的sin值就不同。
代码就不贴了比较好理解,奇数i用了sin偶数用了cos
4. padding
是之前mask函数之前的操作,将pad变成掩码矩阵(0 1矩阵)
老师代码:
# 生成填充注意力掩码的函数,用于在多头自注意力计算中忽略填充部分
def get_attn_pad_mask(seq_q, seq_k):
#-------------------------维度信息--------------------------------
# seq_q 的维度是 [batch_size, len_q]
# seq_k 的维度是 [batch_size, len_k]
#-----------------------------------------------------------------
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# 生成布尔类型张量[batch_size,1,len_k(=len_q)]
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) #<PAD> Token的编码值为0
# 变形为何注意力分数相同形状的张量 [batch_size,len_q,len_k]
pad_attn_mask = pad_attn_mask.expand(batch_size, len_q, len_k)
#-------------------------维度信息--------------------------------
# pad_attn_mask 的维度是 [batch_size,len_q,len_k]
#-----------------------------------------------------------------
return pad_attn_mask # [batch_size,len_q,len_k]
解释一下关键操作:
pad_attn_mask = seq_k.data.eq(0):这一行代码用于创建一个布尔类型的张量 pad_attn_mask,它的形状与 seq_k 的形状相同,即 [batch_size, len_k]。这个张量的目的是将填充标记的位置设为True,非填充位置设为False。老师使用了 .eq(0) 来检查 seq_k 是否等于0。
pad_attn_mask = pad_attn_mask.unsqueeze(1):在 pad_attn_mask 张量的维度1位置添加一个维度,将其形状从 [batch_size, len_k] 变成 [batch_size, 1, len_k]。
pad_attn_mask = pad_attn_mask.expand(batch_size, len_q, len_k):这一行代码通过 expand 操作将填充掩码的维度扩展,使其与查询序列的长度 len_q 匹配。
5. 编码器层
这只是一个层的打包
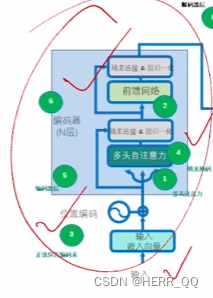
# 定义编码器层类
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention() #多头自注意力层
self.pos_ffn = PoswiseFeedForwardNet() # 位置前馈神经网络层
def forward(self, enc_inputs, enc_self_attn_mask):
#-------------------------维度信息--------------------------------
# enc_inputs 的维度是 [batch_size, seq_len, embedding_dim]
# enc_self_attn_mask 的维度是 [batch_size, seq_len, seq_len]
#-----------------------------------------------------------------
# 将相同的Q,K,V输入多头自注意力层
enc_outputs, attn_weights = self.enc_self_attn(enc_inputs, enc_inputs,
enc_inputs, enc_self_attn_mask)
# 将多头自注意力outputs输入位置前馈神经网络层
enc_outputs = self.pos_ffn(enc_outputs)
#-------------------------维度信息--------------------------------
# enc_outputs 的维度是 [batch_size, seq_len, embedding_dim] 维度与 enc_inputs 相同
# attn_weights 的维度是 [batch_size, n_heads, seq_len, seq_len] 在注意力掩码维度上增加了头数
#-----------------------------------------------------------------
return enc_outputs, attn_weights # 返回编码器输出和每层编码器注意力权重
6. 编码器
先上代码,逻辑上有老师备注还好,我对于一些我自己不熟悉的语法在这里做出解释
# 定义编码器类
n_layers = 6 # 设置Encoder/Decoder的层数
class Encoder(nn.Module):
def __init__(self, corpus):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(corpus.src_vocab, d_embedding) # 词嵌入层
self.pos_emb = nn.Embedding.from_pretrained( \
get_sin_enc_table(corpus.src_len+1, d_embedding), freeze=True) # 位置嵌入层
self.layers = nn.ModuleList(EncoderLayer() for _ in range(n_layers))# 编码器层数
def forward(self, enc_inputs):
#-------------------------维度信息--------------------------------
# enc_inputs 的维度是 [batch_size, source_len]
#-----------------------------------------------------------------
# 创建一个从1到source_len的位置索引序列
pos_indices = torch.arange(1, enc_inputs.size(1) + 1).unsqueeze(0).to(enc_inputs)
#-------------------------维度信息--------------------------------
# pos_indices 的维度是 [1, source_len]
#-----------------------------------------------------------------
# 对输入进行词嵌入和位置嵌入相加 [batch_size, source_len,embedding_dim]
enc_outputs = self.src_emb(enc_inputs) + self.pos_emb(pos_indices)
#-------------------------维度信息--------------------------------
# enc_outputs 的维度是 [batch_size, seq_len, embedding_dim]
#-----------------------------------------------------------------
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # 生成自注意力掩码
#-------------------------维度信息--------------------------------
# enc_self_attn_mask 的维度是 [batch_size, len_q, len_k]
#-----------------------------------------------------------------
enc_self_attn_weights = [] # 初始化 enc_self_attn_weights
# 通过编码器层 [batch_size, seq_len, embedding_dim]
for layer in self.layers:
enc_outputs, enc_self_attn_weight = layer(enc_outputs, enc_self_attn_mask)
enc_self_attn_weights.append(enc_self_attn_weight)
#-------------------------维度信息--------------------------------
# enc_outputs 的维度是 [batch_size, seq_len, embedding_dim] 维度与 enc_inputs 相同
# enc_self_attn_weights 是一个列表,每个元素的维度是[batch_size, n_heads, seq_len, seq_len]
#-----------------------------------------------------------------
return enc_outputs, enc_self_attn_weights # 返回编码器输出和编码器注意力权重
self.src_emb = nn.Embedding(corpus.src_vocab, d_embedding):这一行代码创建一个词嵌入层,nn.Embedding 接受两个参数:词汇表的大小 和嵌入维度 。
nn.Embedding.from_pretrained(embeddings, freeze=True):from_pretrained() 方法用预训练的嵌入矩阵初始化嵌入层的权重。embeddings 参数是之前由 get_sin_enc_table 函数生成的嵌入矩阵。设置 freeze=True 的目的是冻结这个嵌入层的权重,使其在训练过程中保持不变,不会被梯度更新。
self.layers = nn.ModuleList(EncoderLayer() for _ in range(n_layers)):这一行代码创建了一个包含多个编码器层的列表,并将其分配给 self.layers 类属性。nn.ModuleList 是PyTorch中的一个容器,它允许将多个子模块(这里是 EncoderLayer 的实例)组合在一起,并在模型中一起使用。
pos_indices = torch.arange(1, enc_inputs.size(1) + 1).unsqueeze(0).to(enc_inputs):这一行代码创建一个位置索引张量 pos_indices,用来表示输入序列中各个位置的位置编码。torch.arange 生成从 1 到 enc_inputs.size(1) + 1 的整数序列,然后 unsqueeze(0) 将其形状从 [source_len] 变成 [1, source_len],最后使用 to(enc_inputs) 将其转换为与 enc_inputs 相同的数据类型
for layer in self.layers: 和 enc_outputs, enc_self_attn_weight = layer(enc_outputs, enc_self_attn_mask):这两行代码通过循环遍历每个编码器层,并调用每个层的前向传播函数,即 layer 的 forward 函数,传入编码器的输出 enc_outputs 和自注意力掩码 enc_self_attn_mask,得到编码器层的输出和注意力权重。每个注意力权重被添加到 enc_self_attn_weights 列表中。
7. 后续位置掩码
出现的原理是,你说一句话的时候只会对前面注意,而不会对后面产生注意。
使用padding
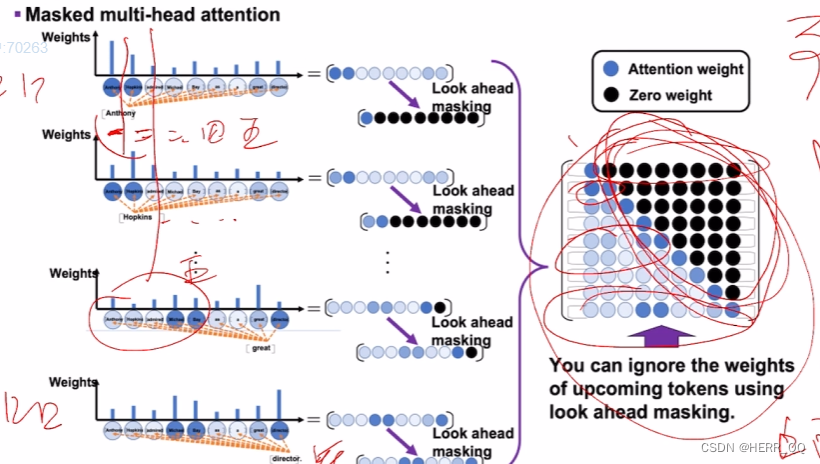
主要代码就是
# 使用numpy创建一个上三角矩阵(triu = triangle upper)
subsequent_mask = np.triu(np.ones(attn_shape), k=1)
只是解码器用,编码器负责将输入序列编码成一个上下文向量编码器随便看。解码器不能随便看,这是为了避免信息泄漏和确保模型按顺序生成输出。后续位置掩码将未来位置的信息屏蔽掉,确保解码器只能看到已生成的部分。
8. 解码器层
直接上代码
# 定义解码器层类
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention() # 多头自注意力层
self.dec_enc_attn = MultiHeadAttention() # 多头注意力层,连接编码器和解码器
self.pos_ffn = PoswiseFeedForwardNet() # 位置前馈神经网络层
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
#-------------------------维度信息--------------------------------
# dec_inputs 的维度是 [batch_size, target_len, embedding_dim]
# enc_outputs 的维度是 [batch_size, source_len, embedding_dim]
# dec_self_attn_mask 的维度是 [batch_size, target_len, target_len]
# dec_enc_attn_mask 的维度是 [batch_size, target_len, source_len]
#-----------------------------------------------------------------
# 将相同的Q,K,V输入多头自注意力层
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs,
dec_inputs, dec_self_attn_mask)
#-------------------------维度信息--------------------------------
# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]
# dec_self_attn 的维度是 [batch_size, n_heads, target_len, target_len]
#-----------------------------------------------------------------
# 将解码器输出和编码器输出输入多头注意力层
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs,
enc_outputs, dec_enc_attn_mask)
#-------------------------维度信息--------------------------------
# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]
# dec_enc_attn 的维度是 [batch_size, n_heads, target_len, source_len]
#-----------------------------------------------------------------
# 输入位置前馈神经网络层
dec_outputs = self.pos_ffn(dec_outputs)
#-------------------------维度信息--------------------------------
# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]
# dec_self_attn 的维度是 [batch_size, n_heads, target_len, target_len]
# dec_enc_attn 的维度是 [batch_size, n_heads, target_len, source_len]
#-----------------------------------------------------------------
# 返回解码器层输出,每层的自注意力和解-编编码器注意力权重
return dec_outputs, dec_self_attn, dec_enc_attn
没有可好解释的
9 解码器
# 定义解码器类
n_layers = 6 # 设置Decoder的层数
class Decoder(nn.Module):
def __init__(self, corpus):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(corpus.tgt_vocab, d_embedding) # 词嵌入层
self.pos_emb = nn.Embedding.from_pretrained( \
get_sin_enc_table(corpus.tgt_len+1, d_embedding), freeze=True) # 位置嵌入层
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) # 叠加多层
def forward(self, dec_inputs, enc_inputs, enc_outputs):
#-------------------------维度信息--------------------------------
# dec_inputs 的维度是 [batch_size, target_len]
# enc_inputs 的维度是 [batch_size, source_len]
# enc_outputs 的维度是 [batch_size, source_len, embedding_dim]
#-----------------------------------------------------------------
# 创建一个从1到source_len的位置索引序列
pos_indices = torch.arange(1, dec_inputs.size(1) + 1).unsqueeze(0).to(dec_inputs)
#-------------------------维度信息--------------------------------
# pos_indices 的维度是 [1, target_len]
#-----------------------------------------------------------------
# 对输入进行词嵌入和位置嵌入相加
dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(pos_indices)
#-------------------------维度信息--------------------------------
# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]
#-----------------------------------------------------------------
# 生成解码器自注意力掩码和解码器-编码器注意力掩码
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) # 填充位掩码
dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs) # 后续位掩码
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask.to(device) \
+ dec_self_attn_subsequent_mask.to(device)), 0)
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # 解码器-编码器掩码
#-------------------------维度信息--------------------------------
# dec_self_attn_pad_mask 的维度是 [batch_size, target_len, target_len]
# dec_self_attn_subsequent_mask 的维度是 [batch_size, target_len, target_len]
# dec_self_attn_mask 的维度是 [batch_size, target_len, target_len]
# dec_enc_attn_mask 的维度是 [batch_size, target_len, source_len]
#-----------------------------------------------------------------
dec_self_attns, dec_enc_attns = [], [] # 初始化 dec_self_attns, dec_enc_attns
# 通过解码器层 [batch_size, seq_len, embedding_dim]
for layer in self.layers:
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs,
dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
#-------------------------维度信息--------------------------------
# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]
# dec_self_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, target_len, target_len]
# dec_enc_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, target_len, source_len]
#-----------------------------------------------------------------
# 返回解码器输出,解码器自注意力和解-编编码器注意力权重
return dec_outputs, dec_self_attns, dec_enc_attns
torch.gt((dec_self_attn_pad_mask.to(device) + dec_self_attn_subsequent_mask.to(device)), 0) 的作用是将填充位掩码和后续位掩码相加,然后将所有大于零的元素设置为 True,其他元素设置为 False,创建一个掩码矩阵。
重点再讲一下我对decoder forward输入的理解:
dec_inputs 是目标语言的输入序列,是真实的答案,经过词嵌入层和位置嵌入层的嵌入表示之后,输入网络
这里需要endonder的input,是创建掩码的需要。
enc_outputs 是源语言编码器的输出,表示将被用于解码器中的注意力机制,以便解码器可以利用源语言信息来生成目标语言的输出序列。
看到以下例子挺好的,便于理解,这里掩码直接是建立好的,不像老师把encoder的input放到decoder的forward中再计算,是直接通过形参传入的
任务是英语翻译到法语 源语言句子 (Encoder Input): “Hello, how are you?”
目标语言句子 (Decoder Input): “Bonjour, comment ça va ?”
在这个例子中:
目标语言的输入序列(Decoder Input) 是 “Bonjour, comment ça va ?”。
编码器输出(Encoder Outputs) 包含了关于源语言句子 “Hello, how are you?” 的编码信息。
解码器自注意力掩码和解码器-编码器注意力掩码 确保在解码器的自注意力机制和解码器-编码器注意力机制中,每个位置只依赖当前位置及其之前的信息。
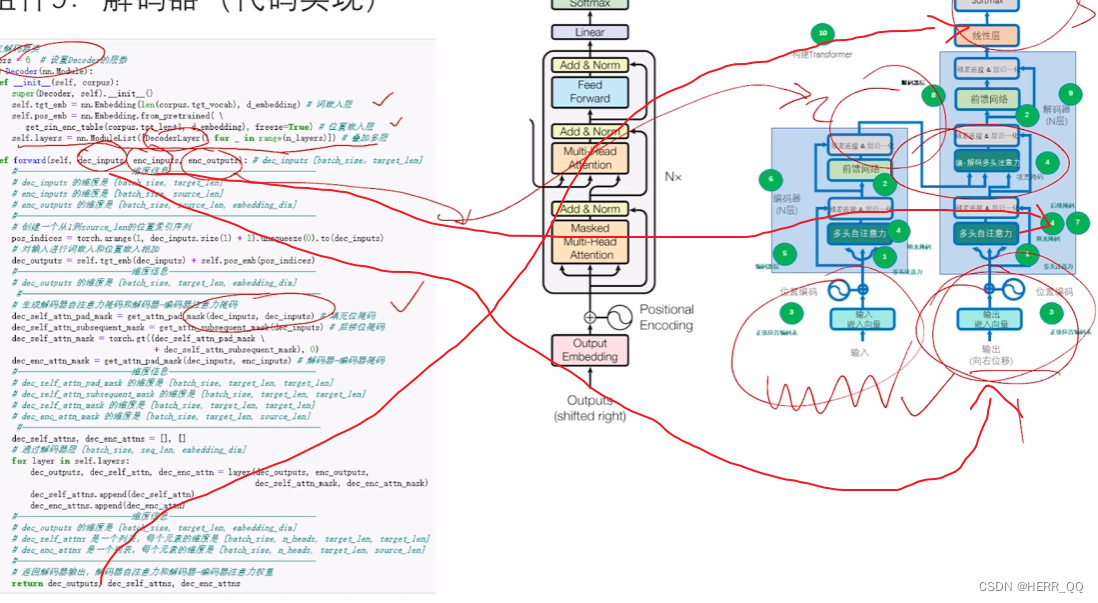
其他的部分看老师的注释应该就可以理解。
完整 Transformer
积木都有了现在开始建立Transformer
# 定义Transformer模型
class Transformer(nn.Module):
def __init__(self, corpus):
super(Transformer, self).__init__()
self.encoder = Encoder(corpus) # 初始化编码器实例
self.decoder = Decoder(corpus) # 初始化解码器实例
# 定义线性投影层,将解码器输出转换为目标词汇表大小的概率分布
self.projection = nn.Linear(d_embedding, corpus.tgt_vocab, bias=False)
def forward(self, enc_inputs, dec_inputs):
#-------------------------维度信息--------------------------------
# enc_inputs 的维度是 [batch_size, source_seq_len]
# dec_inputs 的维度是 [batch_size, target_seq_len]
#-----------------------------------------------------------------
# 将输入传递给编码器,并获取编码器输出和自注意力权重
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
#-------------------------维度信息--------------------------------
# enc_outputs 的维度是 [batch_size, source_len, embedding_dim]
# enc_self_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, src_seq_len, src_seq_len]
#-----------------------------------------------------------------
# 将编码器输出、解码器输入和编码器输入传递给解码器
# 获取解码器输出、解码器自注意力权重和编码器-解码器注意力权重
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
#-------------------------维度信息--------------------------------
# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]
# dec_self_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, tgt_seq_len, src_seq_len]
# dec_enc_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, tgt_seq_len, src_seq_len]
#-----------------------------------------------------------------
# 将解码器输出传递给投影层,生成目标词汇表大小的概率分布
dec_logits = self.projection(dec_outputs)
#-------------------------维度信息--------------------------------
# dec_logits 的维度是 [batch_size, tgt_seq_len, tgt_vocab_size]
#-----------------------------------------------------------------
# 返回逻辑值(原始预测结果),编码器自注意力权重,解码器自注意力权重,解-编码器注意力权重
return dec_logits, enc_self_attns, dec_self_attns, dec_enc_attns
代码依旧老师解释的很详细,这里我对为什么需要三种注意力机制还是有点疑问:通过一个英语到法语的机器翻译作为示例研究了一下。GPT原回答里笔者认为有点错误做了删除线处理,请读者大佬再看一眼?????
编码器自注意力(Encoder Self-Attention):
在编码器中,模型需要将输入的英语句子转化为一个适合理解的内部表示。这是通过编码器自注意力来实现的。考虑以下英语句子:“The cat is on the mat.”。在编码器自注意力的帮助下,模型可以关注句子中的每个词,并了解它们之间的关系。这有助于模型捕捉长距离的依赖关系,例如,了解句子中的主语和谓语之间的关系。
在这种情况下,编码器自注意力权重会显示模型在编码输入句子时,对每个单词的关注程度。对于英语句子 “The cat is on the mat.”,编码器自注意力可能会显示模型在生成每个单词的编码表示时,如何对其他单词进行关注。这有助于确保模型在编码输入句子时能够有效地捕捉上下文信息。
解码器自注意力(Decoder Self-Attention):
在解码器中,模型需要生成法语翻译,同时考虑到已生成的部分。例如,当模型生成法语翻译的第一个单词 第二或之后的单词时时,它需要了解输入英语句子的内容 以及已生成的单词。这是通过解码器自注意力来实现的。
在这种情况下,解码器自注意力权重会显示模型在生成法语翻译的每个单词时,如何对已生成的单词和输入英语句子 进行关注。这确保了模型能够生成正确的语法结构和语义信息,因为它了解了先前生成的内容和输入内容。
编码器-解码器注意力(Encoder-Decoder Attention):
在翻译任务中,模型需要将输入英语句子的信息与正在生成的法语翻译相对应。这是通过编码器-解码器注意力来实现的。当模型生成法语翻译的一个单词时,它需要对输入英语句子的每个单词进行关注,以便正确对齐输入和输出。
编码器-解码器注意力权重会显示模型在生成法语翻译的每个单词时,如何对输入英语句子的不同位置进行关注。这确保了模型在生成法语翻译时能够正确地对应英语句子的内容,以实现准确的翻译。
笔者本来计划把transformer-gpt系列做出一个完整的demo,但是由于经济局势很危,故直接开始bevformer的研究学习,学习的过程中再查缺补漏,请有兴趣一起研究的大佬们私信呀!!!!!!!!!!!!!!!!!!!!!!!!!!!














 5094
5094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









